Datenwissen von A-Z
WIKI
WIKI
A wie:
A wie: Azure Data Factory
Einführung
Azure Data Factory ist ein von Microsoft bereitgestellter cloudbasierter Datenintegrations- und Orchestrierungsdienst. Er ermöglicht Unternehmen die effiziente Verwaltung und Verarbeitung ihrer Daten (sowohl strukturiert als auch unstrukturiert) aus einer Vielzahl von Quellen, lokal und in der Cloud. Mithilfe einer intuitiven visuellen Benutzeroberfläche und leistungsstarker Funktionen können Benutzer datengesteuerte Workflows für die Datenverschiebung und -transformation erstellen, um ihre Daten einfach über verschiedene Systeme hinweg zu integrieren. Somit ist Azure Data Factory eine wertvolle Ergänzung für die Datenverwaltungsstrategie jedes Unternehmens.
Zusätzlich zur Datenverschiebung bietet Azure Data Factory auch eine breite Palette an Datentransformationsfunktionen, mit denen Benutzer ihre Daten einfach bereinigen, anreichern und transformieren können. Die integrierten Konnektoren und Integration mit anderen Azure-Diensten wie Azure HDInsight, Azure Machine Learning und Azure Synapse Analytics erleichtern die Durchführung komplexer Datentransformationen und -analysen.
Nutzen
- Azure Data Factory ist ein cloudbasierter Dienst von Microsoft, der es Unternehmen ermöglicht, ihre Daten einfach und effizient zu verwalten und zu verarbeiten.
- Durch die Skalierbarkeit des Dienstes können Organisationen ihre Ressourcen basierend auf ihren Datenverarbeitungsanforderungen einfach hoch- oder runterskalieren, ohne zusätzliche Investitionen in Hardware oder Infrastruktur tätigen zu müssen.
- Die Funktionen zur Datenintegration und -transformation von Azure Data Factory ermöglichen es Unternehmen, ihre Daten einfach zu verwalten und zu verarbeiten.
- Die integrierten Sicherheitsfunktionen wie Verschlüsselung und Zugriffskontrolle gewährleisten die Datensicherheit und die Einhaltung von Datenschutzbestimmungen.
- Die Integration von Azure Data Factory mit anderen Azure-Diensten wie Azure HDInsight, Azure Machine Learning und Azure Synapse Analytics ermöglicht es Unternehmen, tiefere Einblicke in ihre Daten zu gewinnen und datengestützte Entscheidungen zu treffen.
- Die visuelle, benutzerfreundliche Oberfläche erleichtert es Organisationen, ihre Datenpipelines zu verwalten und zu überwachen, was die Effizienz und Produktivität verbessert und den Zeitaufwand für die Datenverwaltung reduziert.
A wie: Azure DevOps
Einführung
Azure DevOps bietet Entwicklerdienste für Support-Teams zur Arbeitsplanung, zur Zusammenarbeit bei der Code-Entwicklung und zur Erstellung und Bereitstellung von Anwendungen. Azure DevOps unterstützt eine Kultur und eine Reihe von Prozessen, die Entwickler und Projektmanager zusammenbringen, um die Softwareentwicklung abzuschließen. Es ermöglicht Unternehmen, Produkte in einem schnelleren Tempo zu erstellen und zu verbessern, als dies mit herkömmlichen Softwareentwicklungsansätzen möglich ist.
Architektur
Azure Boards ist in mehreren hierarchischen Ebenen organisiert, um Flexibilität und Anpassungsfähigkeit in verschiedenen Organisationen zu gewährleisten.
- Eine Organisation ist das oberste Element der Architektur. Ihre Anzahl ist innerhalb eines einzelnen Unternehmens unbegrenzt. Jede Organisation kann mit einem Azure AD verknüpft werden, um nach Personen innerhalb der Organisation zu suchen. Jede Organisation hat einen und nur einen Eigentümer, der die meisten Rechte hat.
- Ein Projekt ist das zweite Top-Element der Architektur. Es bietet eine Reihe von Komponenten für die Arbeitsplanung und die Zusammenarbeit bei der Softwareentwicklung, darunter auch Azure Boards. Jedes Projekt muss sich innerhalb einer Organisation befinden und es gibt eine weiche Begrenzung von 300 Projekten pro Organisation auf Azure DevOps Services (Cloud-Version), aber keine Begrenzung auf Azure DevOps On-Premise. Jedes Projekt hat einen oder mehrere Projektadminsitratoren.
- Azure Boards ist eine der Komponenten eines jeden Projekts. Andere Komponenten sind Azure Repos, Azure Pipelines und Azure Artifacts. Azure Boards besteht aus einer Backlog-Liste, einem Kanban Board, einem Query Builder und Lieferplänen.
- Ein Work Item ist das Kernelement eines jeden Projekts in Azure Boards. Ein Work Item kann viele Typen haben, die durch einen Projektprozess definiert werden.
Azure Boards
Azure Boards bietet eine Reihe von Agile-Tools zur Unterstützung der Planung und Verfolgung von Arbeit, Code-Fehlern und Problemen mit Kanban- und Scrum-Methoden. Es ist eine der vielen Komponenten, die in Azure DevOps enthalten sind.
Es bietet Ihnen eine Reihe von vordefinierten Arbeitselementtypen zur Unterstützung der Verfolgung von Features, User Stories, Bugs und Aufgaben. Sie können schnell loslegen, indem Sie Ihr Product Backlog oder Kanban-Board verwenden. Unabhängig davon, welche agile Methode Sie verwenden, Azure Boards unterstützt Sie mit den Tools, die Sie für die Umsetzung dieser Methode benötigen.
Mit dem Azure Boards-Webdienst können Teams ihre Softwareprojekte verwalten. Er bietet eine Vielzahl von Funktionen, darunter native Unterstützung für Scrum und Kanban, anpassbare Dashboards und integrierte Berichte. Diese Tools skalieren mit dem Wachstum Ihres Unternehmens.
Verfolgen Sie schnell und einfach User Stories, Backlog-Elemente, Aufgaben, Features und Bugs, die mit Ihrem Projekt verbunden sind. Verfolgen Sie die Arbeit, indem Sie Arbeitselemente basierend auf den für Ihr Projekt verfügbaren Prozess- und Arbeitselementtypen hinzufügen.
Nutzen
Azure DevOps ist eine vollständige, skalierbare und datengesteuerte Lösung für das Projektmanagement, die eine agile Methode bietet und gleichzeitig alles unter dem Microsoft Stack hält. Die Nutzung von Azure Boards bleibt auch für große Organisationen kosteneffizient und bringt Struktur mit allen möglichen Microsoft-Integrationen und benutzerdefinierten Projektprozessen.
A wie: Azure Functions

Einführung
Mit Azure Functions können Sie die Logik Ihres Systems als ereignisgesteuerte, leicht verfügbare Codeblöcke in Ihrer bevorzugten Programmiersprache mit automatischer Bereitstellung implementieren. Diese Codeblöcke werden als „Funktionen“ bezeichnet.
Funktionen
Eine Funktion ist das wichtigste Konzept in Azure Functions. Eine Funktion enthält zwei wichtige Teile – Ihren Code und eine Konfigurationsdatei, die function.json. Bei kompilierten Sprachen wird diese Konfigurationsdatei automatisch aus den Anmerkungen in Ihrem Code generiert. Bei Skriptsprachen müssen Sie die Konfigurationsdatei selbst erstellen.
Die Datei function.json definiert den Auslöser der Funktion, die Bindungen und andere Konfigurationseinstellungen. Jede Funktion hat einen und nur einen Auslöser. Die Laufzeitumgebung verwendet diese Konfigurationsdatei, um die zu überwachenden Ereignisse und die Art und Weise der Datenübergabe und -rückgabe bei der Ausführung einer Funktion zu bestimmen.
Anwendungen
Azure Functions kann für die Erstellung von Systemen verwendet werden, die auf eine Reihe kritischer Ereignisse reagieren. Egal, ob Sie eine Web-API erstellen, auf Datenbankänderungen reagieren, IoT-Datenströme verarbeiten oder Nachrichtenwarteschlangen verwalten – jede Anwendung benötigt eine Möglichkeit, Code auszuführen, wenn diese Ereignisse eintreten.
Mit Azure Functions sind Sie in der Lage, die Logik Ihres Systems in Funktionen zu implementieren, die jederzeit ausgeführt werden können, wenn Sie auf kritische Ereignisse reagieren müssen. Azure Functions deckt den Bedarf mit so vielen Ressourcen und Funktionsinstanzen wie nötig – aber nur solange wie nötig. Wenn die Anfragen zurückgehen, werden alle zusätzlichen Ressourcen und Anwendungsinstanzen automatisch abgeschaltet. Sie zahlen nur, solange Ihre Funktionen laufen.
Bearbeitung von Funktionen
Mit dem in das Azure-Portal integrierten Funktionseditor können Sie Ihren Code und Ihre function.json-Datei direkt inline aktualisieren. Dies wird nur für kleine Änderungen oder Proofs of Concept empfohlen – am besten verwenden Sie ein lokales Entwicklungstool wie Visual Studio Code.
Nutzen
Hier sind einige Vorteile von Microsoft Azure Functions:
- Skalierbarkeit: Azure Functions sind von Natur aus skalierbar und können automatisch an die Anforderungen angepasst werden.
- Kosteneffektivität: Azure Functions berechnen nur die tatsächlich ausgeführte Zeit und vermeiden damit unnötige Kosten für ungenutzte Kapazitäten.
- Einfache Integration: Azure Functions können einfach mit anderen Azure-Diensten wie Azure Event Grid, Azure Blob Storage oder Azure Cosmos DB integriert werden.
- Programmiersprachen: Azure Functions unterstützt mehrere Programmiersprachen wie C#, Java, JavaScript und Python.
- Entwicklerfreundlichkeit: Azure Functions bieten eine einfache und schnelle Möglichkeit, Funktionen zu erstellen und zu testen.
- Schnelle Bereitstellung: Azure Functions werden automatisch bereitgestellt und aktualisiert, so dass sich Entwickler auf ihre Funktionen konzentrieren können, anstatt sich um Infrastrukturdetails zu kümmern.
- Flexibilität: Azure Functions können auf verschiedene Arten ausgelöst werden, z.B. durch HTTP-Anforderungen, Zeitpläne oder Ereignisse von Azure-Diensten.
A wie: Azure Log Analytics
Monitoring von Log-Daten mit Azure Log Analytics
Sobald eine Premium Kapazität vorhanden ist, muss die Auslastung der Kapazitäten selbstständig verwaltet werden. Azure Log Analytics ist ein Dienst, welcher die Auswertung von Log-Daten in Power BI mithilfe der Power BI Analysis Services Engine ermöglicht und so mehr Transparenz in den Kapazitätsverbrauch pro Power BI Bericht uvm. liefert. Folgende Einblicke sind mit der Power BI Analysis Services Engine möglich:
- Zusammenfassung auf Arbeitsbereichs-Ebene
- Top Reports mit dem höchsten CPU Verbrauch
- Dataset (Semantisches Modell) Failure und Success Rate
- Datasets mit den meisten Abfragen + Dauer der Abfragen
- Berichtnutzung pro Tag/Monat/Woche
- uvm. mit Drillthroughs
- Engine Aktivitäten
- Kapazitäten auf Arbeitsbereichs-, Datenset-, und Report-Ebene
- Rechenzeiten (CPU time) mit Drillthrough auf Query-Ebene (z.B. Welche DAX-Query brauchte lange zum Durchführen?)
- uvm. mit Drillthroughs
- Dataset Refreshes
- Übersichten über die Refresh-Dauer verschiedener Datasets
- uvm. mit Drillthroughs
- Abfragestatistiken
- Top Queries mit dem höchsten CPU Verbrauch
- Queries die am längsten gebraucht haben
- uvm. mit Drillthroughs
- Nutzeraktivitäten
- Übersicht über die Top Nutzer diverser Berichte
- uvm. mit Drillthroughs
- Fehlerübersicht
- Details zu Fehlern (falls vorhanden)
A wie: Azure Machine Learning
Einführung Azure ML
Azure Machine Learning ist ein cloudbasierter Service von Microsoft, der Unternehmen dabei unterstützt, den Workflow von Machine Learning Projekten zu managen. Dies beinhaltet die Datenvorbereitung, das Training und Deployment von Modellen sowie das Monitoring und die Verwaltung von Modellen durch MLOps.
Azure Machine Learning Studio bietet verschiedene Optionen zur Entwicklung von Machine Learning Modellen an, darunter:
- Notebooks: Benutzer können Jupyter Notebooks direkt in Azure Machine Learning Studio erstellen und ausführen.
- Automated Machine Learning: Mit automatisierten ML-Experimenten können Modelle über eine Benutzeroberfläche erstellt werden.
- Azure Machine Learning Designer: Der Designer ermöglicht das Training und Deployment von Machine Learning Modellen, ohne dass Benutzer Code schreiben müssen. Durch Drag & Drop von Datensätzen und Komponenten kann eine Machine Learning Pipeline erstellt werden.
Um die Leistung dieser drei Methoden zu bewerten, können sie für das Trainieren eines Modells zur Vorhersage der Kreditwürdigkeit von Hauskreditkunden verglichen werden. Diese Vorhersage ermöglicht Unternehmen, automatisch festzustellen, welche Kunden für die Kreditvergabe geeignet sind, basierend auf den Angaben der Kunden.
Nutzen Azure ML
- Management des Workflows von Machine Learning Projekten
- Datenvorbereitung, Training und Deployment von Modellen
- MLOps zur Überwachung und Verwaltung von Modellen
- Möglichkeit, Modelle ohne eigenen Code zu schreiben zu trainieren und zu deployen
- Automatisierte ML-Experimente zur Erstellung von Modellen über eine Benutzeroberfläche
- Vergleich der Ergebnisse von verschiedenen Methoden zur Modellentwicklung
- Automatisierte Entscheidungen auf Basis von Kundenangaben
A wie: Azure Monitor
Einführung Azure Monitor
Azure Monitor unterstützt Ihren Betrieb dabei, die Leistung und Verfügbarkeit Ihrer Ressourcen zu maximieren und Probleme proaktiv zu erkennen.
Das folgende Diagramm bietet eine allgemeine Ansicht von Azure Monitor.
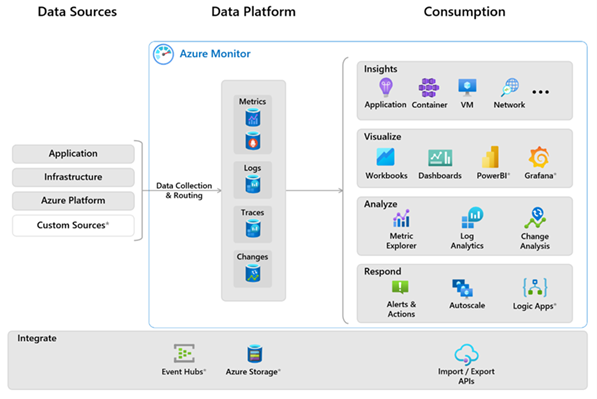
Das Diagramm zeigt die Azure Monitor-Systemkomponenten:
- Die Datenquellen sind Arten von Daten, die von jeder überwachten Ressource gesammelt wurden. Die Daten werden gesammelt und an die Datenplattform weitergeleitet.
- Die Datenplattform besteht aus den Datenspeichern für gesammelte Daten. Die Azure Monitor-Datenplattform verfügt über Speicher für Metriken, Protokolle, Ablaufverfolgungen und Änderungen.
- Zu den Funktionen und Komponenten, die Daten nutzen, gehören Analysen, Visualisierungen, Erkenntnisse und Antworten.
- Dienste, die sich in Azure Monitor integrieren lassen und zusätzliche Funktionen bereitstellen, sind im Diagramm mit einem Sternchen * gekennzeichnet.
Azure Log Analytics Workspace
Ein Log Analytics-Arbeitsbereich sammelt Protokolle aus verschiedenen Datenquellen zur Datenanalyse. Es kann von anderen Diensten verwendet werden und zum Auslösen von Warnungen und Aktionen, beispielsweise mithilfe von Logic Apps. Der Log Analytics-Arbeitsbereich besteht aus Tabellen, die Sie konfigurieren können, um Ihr Datenmodell und die protokollbezogenen Kosten zu verwalten.
Azure Dashboards
Mit Azure Dashboards können Sie verschiedene Arten von Daten in einem einzigen Bereich im Azure-Portal kombinieren. Sie können das Dashboard optional mit anderen Azure-Benutzern teilen. Sie können die Ausgabe jeder Protokollabfrage oder Metrik als Diagramm zu einem Azure-Dashboard hinzufügen. Sie könnten beispielsweise ein Dashboard erstellen, das ein Diagramm mit Metriken, eine Tabelle mit Aktivitätsprotokollen, ein Nutzungsdiagramm von Application Insights und die Ausgabe einer Protokollabfrage anzeigt.
Logs Analytics
Die Log Analytics-Benutzeroberfläche im Azure-Portal unterstützt Sie beim Abfragen der von Azure Monitor gesammelten Protokolldaten, sodass Sie die gesammelten Daten schnell abrufen und analysieren können. Nachdem Sie Testabfragen erstellt haben, können Sie die Daten direkt mit Azure Monitor-Tools analysieren oder die Abfragen zur Verwendung mit Visualisierungen oder Warnungsregeln speichern.
A wie: Azure Purview

Einführung
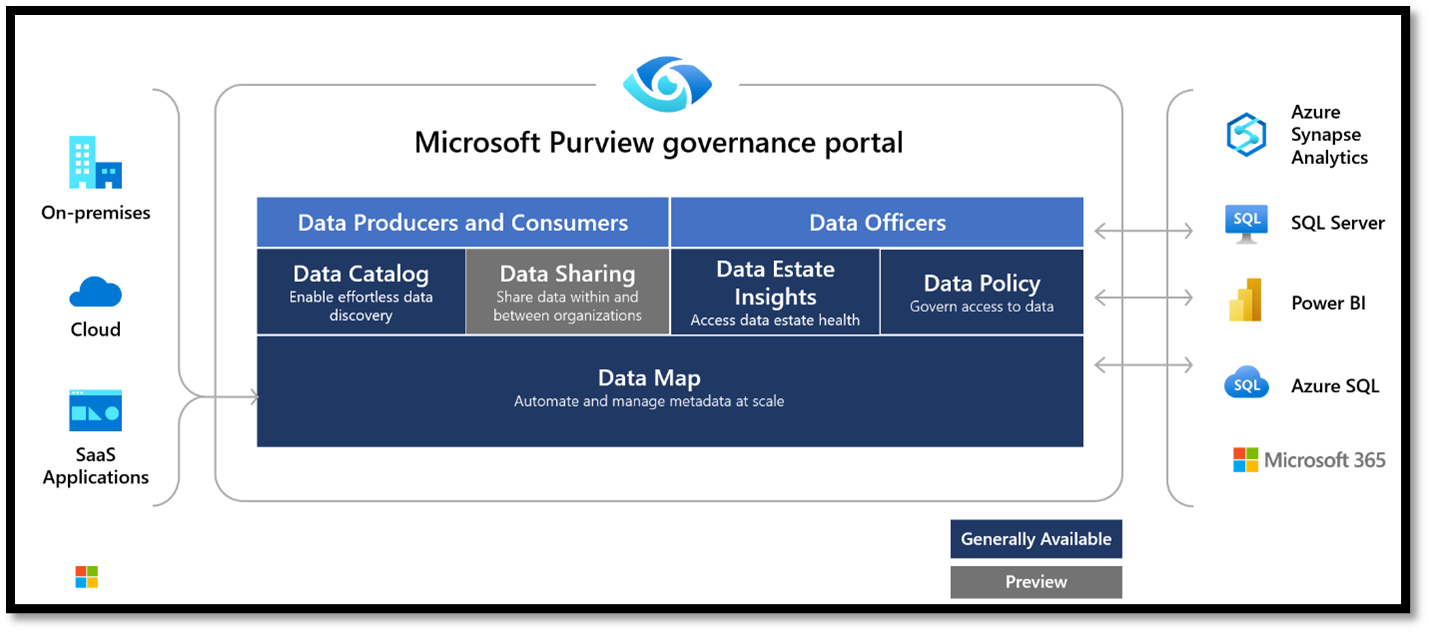
Das Governanceportal Microsoft Purview bietet umfassende Lösungen zur Datenverwaltung, die helfen können, lokale, Multicloud- und Software-as-a-Service-Daten (SaaS) zu verwalten. Mit dem Microsoft Purview-Governanceportal kann man folgendes erreichen:
- Erstellung einer ganzheitlichen und aktuellen Übersicht über die aktuelle Datenlandschaft, mithilfe einer automatisierten Datenermittlung, Klassifizierung und Verfolgung der Daten nutzen.
- Befähigen Sie Data Owners, ihren Datenbestand effektiv zu verwalten und zu schützen.
 Nutzen
Nutzen
 Nutzen
Nutzen- Microsoft Purview unterstützt Unternehmen bei der optimalen Nutzung ihrer vorhandenen Informationsressourcen.
- Der Data Map macht Datenquellen leicht auffindbar und verständlich für die Benutzer, die die Daten verwalten.
- Der Data Catalog ermöglicht es Benutzern, schnell nach relevanten Daten zu suchen, sie zu verstehen und in ihrem bevorzugten Tool zu nutzen. Benutzer können auch Beiträge zum Katalog leisten, indem sie Datenquellen taggen, dokumentieren und kommentieren, sowie neue Datenquellen registrieren.
- Data Policies erlauben den einfachen Zugang zu Datenquellen intern zu verwalten
- Data Sharing öffnet Purview für externe Nutzer und erweitert die Zusammenarbeit auf Firmenpartner
Komponenten
Purview Scan
Bei einem Microsoft Purview Scan werden Metadaten über die verfügbaren Datenquellen gesammelt und organisiert. Dazu muss zunächst die Datenquelle ausgewählt werden, welche gescannt werden soll. Dies können Datenbanken, Data Lakes, Cloud-Speicher, Dateisysteme oder andere Datenquellen in Ihrer Azure-Umgebung sein. Anschließend können die Parameter für den Scan konfiguriert werden, wobei unter anderem die Scanhäufigkeit festgelegt wird. Hier gibt es die Möglichkeit, einen Trigger zur regelmäßigen Ausführung des Scans basierend auf bestimmten Datums- und Uhrzeitwerten zu definieren oder einen einmaligen Scan durchzuführen. Nach Abschluss des Scans können die Resultate im Purview-Governanceportal ausgewertet werden.
Purview Sources
Die Datenquellen können in Purview sowohl in einer Tabellenansicht als auch in einer Zuordnungsansicht dargestellt werden. Die Zuordnungsansicht liefert dabei eine hierarchische Anordnung der einzelnen Datenquellen. Beim detaillierten Blick in eine Sammlung werden alle Ressourcen aufgelistet, wobei für jede Ressource das Schema und weitere Eigenschaften ersichtlich ist.
Purview Glossar
Die Anlegung eines Unternehmensglossars bietet die Möglichkeit, bestimmte Begriffe zu definieren, um eine einheitliche Verwendung zu gewährleisten. Beim Hinzufügen eines neuen Begriffs wird der Name, eine Beschreibung und optional ein Akronym festgelegt. Zudem können die Begriffe durch die Angabe eines übergeordneten Begriffs hierarchisch angeordnet werden. Die Glossarbegriffe können anschließend zum Labeling einzelner Ressourcen verwendet werden.
Purview Datenkatalog
Der Datenkatalog in Purview bietet eine Übersicht zu allen verfügbaren Datenquellen. Jede Ressource kann dabei untersucht und bearbeitet werden. Beispielsweise kann das Schema einer Tabelle aktualisiert werden, indem Glossarbegriffe oder Klassifizierungen auf Spaltenebene hinzugefügt oder Datentypen geändert werden. Zudem sind die Eigenschaften und Kontaktdaten der Ressource bearbeitbar.
Purview Lineage
Mithilfe von Purview kann der Datenfluss über Azure Data Factory Pipelines von der Quelle bis zum Ziel dargestellt werden. Dadurch ist es leicht, die Herkunft der Daten nachzuvollziehen.
A wie: Azure Storage Accounts

Einführung
Azure Storage Accounts sind ein unverzichtbarer Bestandteil der Azure-Cloud-Plattform von Microsoft und ermöglichen Unternehmen und Entwicklern die Speicherung, Sicherung und den Abruf von Daten in der Cloud. Azure Storage zeichnet sich durch Skalierbarkeit, Sicherheit und Zuverlässigkeit aus und bietet somit eine ideale Lösung für die Datenspeicherung in der Cloud.
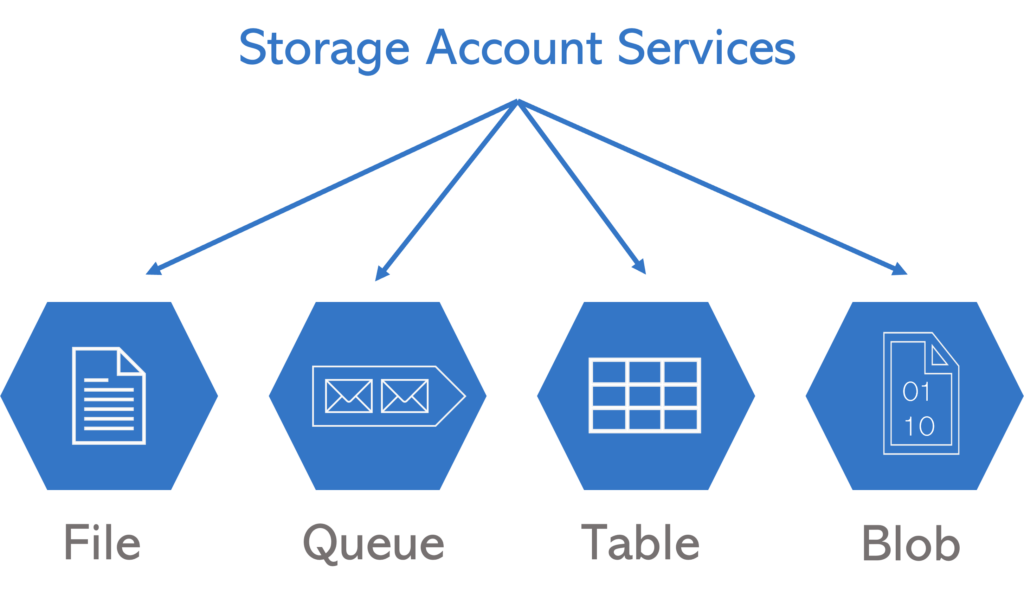
Jeder Azure Storage Account ist im Grunde ein Container, der dazu dient, Daten zu speichern. Es gibt verschiedene Arten von Azure Storage Accounts, wie beispielsweise Blob Storage, File Storage, Table Storage und Queue Storage. Jeder Typ bietet unterschiedliche Funktionen und Vorteile, die den spezifischen Anforderungen der Benutzer entsprechen.
- Blob Storage ist der am häufigsten verwendete Storage Account Service und eignet sich am besten für die Speicherung großer Binärdaten wie Bilder, Videos und Dokumente.
- File Storage ist ideal für die gemeinsame Nutzung von Dateien zwischen Anwendungen und Benutzern.
- Table Storage ermöglicht es Benutzern, strukturierte Daten in der Cloud zu speichern und abzurufen, während
- Queue Storage die Skalierung von Anwendungen unterstützt, die in der Cloud ausgeführt werden.
Nutzen
Azure Storage Accounts bieten eine Vielzahl von Vorteilen, die Unternehmen zu schätzen wissen werden. Dazu zählen insbesondere die Skalierbarkeit, Zuverlässigkeit und Sicherheit. Durch die Skalierbarkeit ist es jederzeit möglich, den Speicherbedarf zu erhöhen oder zu reduzieren, wodurch Unternehmen ihre Kosten flexibel steuern können, während sie sicherstellen, dass sie immer ausreichend Speicherplatz zur Verfügung haben. Azure Storage zeichnet sich auch durch eine hohe Verfügbarkeit und Ausfallsicherheit aus, so dass Daten jederzeit sicher und zuverlässig zugänglich sind.
B wie:
B wie: BI-Architektur
Einführung
Zur Auswahl des Business Intelligence Tools, welches sich am besten zur Erfüllung all Ihrer Ansprüche eignet, führen wir ein Tool-Benchmarking durch, um die unterschiedlichen Lösungen, die der Markt momentan bietet, miteinander zu vergleichen und zu bewerten. Anschließend entwickeln wir für Sie ein geeignetes, performanceorientiertes Datenmodell sowie ein Konzept zur Datenstrukturierung/-architektur. Zusätzlich kümmern wir uns um den reibungslosen Ablauf des ETL-Prozesses, wodurch Ihre Daten fehlerfrei aus verschiedensten Quellen in das Data Warehouse geladen werden.
Inhalte:
- Tool-Benchmarking
- Datenarchitektur
- Datenmodellierung (Queries)
- ETL
- Konnektoren
- Performanceoptimierungen

B wie: BI-Organisation
Einführung
Wir unterstützen Sie dabei, Fachkompetenzen für den Einsatz von Business Intelligence innerhalb eines Competence Centers in Ihrem Unternehmen aufzubauen. Zusätzlich sorgen wir dafür, dass Sie eine Reporting Factory für eine effiziente Aufbereitung der Unternehmensdaten einführen können, sodass die Daten in geeigneter Form den Verantwortlichen Ihres Unternehmens als Fundament für jegliche Entscheidungen zur Verfügung gestellt werden können.
Inhalte:
- Competence Center
- Reporting Factory
- Wissensmanagement
B wie: BI-Strategie
Einführung
Wir möchten mit Ihnen zusammen eine passende, ganzheitliche und zukunftsgerichtete Business Intelligence-Strategie für Ihr Unternehmen entwickeln.
Dafür erstellen wir zunächst ein auf Ihre Anforderungen zugeschnittenes Vorgehensmodell. Außerdem analysieren wir Ihren Reifegrad, um einen Überblick zur aktuellen Leistungsfähigkeit Ihrer Prozesse zu erhalten. Anschließend entwerfen wir zur Visualisierung des gesamten Weges von der aktuellen Situation bis hin zum gewünschten Ergebnis eine BI-Roadmap, um unser Vorgehen und unsere Leistungen transparent zu machen. Zusätzlich führen wir eine Analyse aller bisher gesammelten, relevanten Daten Ihres Unternehmens durch.
Inhalte:
- Vorgehensmodell
- Reifegradanalyse
- BI-Roadmap
- Datenanalyse
C wie:
C wie: Cosmos DB
Einführung Azure Cosmos DB
Azure Cosmos DB ist eine mehrmodellige und flexible Datenbanklösung von Microsoft, welche sich als vollständig verwaltete NoSQL und relationale Datenbank für die moderne App-Entwicklung eignet. Es bietet eine skalierbare und hochleistungsfähige Lösung für das Speichern und Abfragen von strukturierten, halbstrukturierten und unstrukturierten Daten.
Vorteile Cosmos DB
- Globale Skalierbarkeit: Cosmos DB ermöglicht es, Daten über mehrere Regionen hinweg zu replizieren, um eine hohe Verfügbarkeit und Leistung zu gewährleisten. Sie können Ihre Datenbankinstanzen in verschiedenen Azure-Regionen verteilen und den Zugriff auf die Daten von überall auf der Welt ermöglichen.
- Mehrmodellige Unterstützung: Cosmos DB unterstützt verschiedene Datenmodelle, darunter Dokumente, Schlüssel-Wert, Spaltenorientierung, Graphen und Tabellen. Dadurch können Entwickler das für ihre Anwendung am besten geeignete Datenmodell auswählen und flexibel arbeiten.
- Konsistenzstufen: Cosmos DB bietet verschiedene Konsistenzstufen, von starker Konsistenz bis hin zu Eventual Consistency. Entwickler können die gewünschte Konsistenzstufe für ihre Anwendungen auswählen, je nach den Anforderungen an Datengenauigkeit und Latenz.
- SLA-gestützte Verfügbarkeit und Replikation: Cosmos DB gewährleistet eine hohe Verfügbarkeit mit einer SLA (Service Level Agreement) von 99,99 %. Die Daten werden automatisch innerhalb der Azure-Regionen repliziert, um Ausfallsicherheit und Datensicherheit zu gewährleisten.
- Elastische Skalierung: Mit Cosmos DB können Sie die Leistung und Speicherkapazität Ihrer Datenbank elastisch anpassen, um auf wechselnde Workload-Anforderungen zu reagieren. Sie können die Durchsatzkapazität und Speichergröße mit nur wenigen Klicks oder über eine API automatisch erhöhen oder verringern.
- Integrierte Unterstützung für globale Verteilung: Cosmos DB bietet integrierte Unterstützung für die Replikation von Daten über Azure-Regionen hinweg, um eine geringe Latenz und hohe Verfügbarkeit weltweit zu gewährleisten. Sie können die Datenreplikation in Echtzeit konfigurieren und die geografischen Standorte auswählen, an denen Ihre Daten gespeichert werden sollen.
- Entwicklerfreundlichkeit: Cosmos DB bietet eine Vielzahl von SDKs und APIs für verschiedene Programmiersprachen und Plattformen, einschließlich .NET, Java, Node.js, Python und mehr. Es ermöglicht Entwicklern, nahtlos mit ihren bevorzugten Tools und Sprachen zu arbeiten und schnell auf die Datenbank zuzugreifen.
- Eingebaute Sicherheit: Cosmos DB bietet integrierte Sicherheitsmechanismen wie Verschlüsselung im Ruhezustand und in Bewegung, Firewall-Regeln, Zugriffssteuerungen und rollenbasierte Zugriffskontrolle (RBAC). Dadurch werden die Daten vor unbefugtem Zugriff und Manipulation geschützt.
D wie:
D wie: Dashboard und Report
Einführung
Mithilfe von Business Intelligence Berichten können Sie all Ihre Unternehmensdaten erfassen, auswerten und in Reports sowie Dashboards visualisieren, um dadurch Key Performance Indicators (KPIs) zu ermitteln und somit wichtige Erkenntnisse zur Verbesserung Ihrer Geschäftsprozesse zu gewinnen. Eine ungeeignete Darstellung von Daten kann schnell zu Missverständnissen oder Fehlinterpretationen führen, weshalb wir Sie gerne bei der Entwicklung des passenden Designs bzw. Layouts Ihrer Berichte, Dashboards und ScoreCards unterstützen.
Inhalte:
- 3-Phasen Modell (Dashboardentwicklung)
- Data Story Telling
- Mockups
- KPI
- ScoreCard
- Automatisierte Berichterstattung
D wie: Databricks
Databricks ist eine Multi-Cloud Lakehouse Plattform basierend auf Apache Spark. Databricks wird auf den größten Cloud-Plattformen Microsoft Azure, Google Cloud und Amazon AWS angeboten. Es deckt den gesamten Prozess der Datenverarbeitung ab: Data Engineering, Data Science und Machine Learning.
Die Databricks Umgebung übernimmt die Verwaltung von Spark Clustern und bietet interaktive Notebooks zur Verarbeitung, Analyse und Visualisierung von Daten in mehreren Programmiersprachen. Die Aufsetzung und Steuerung von Jobs und Pipelines ermöglichen zudem die Automatisierung der Datenverarbeitung.
Zentrale Komponenten von Databricks sind dabei Apache Spark, Delta Lakes und MLflow.
Apache Spark
Durch den Einsatz von Apache Spark als Framework zur Datenverarbeitung eignet sich Databricks zur Analyse von Big Data und Entwicklung von Machine Learning Modellen, da Spark Cluster mit einer Vielzahl an Servern zur Datenverarbeitung nutzt, welche durch Skalierung eine fast unbeschränkte Rechenleistung bieten. Spark bietet zudem eine Schnittstelle zur Programmierung in verschiedenen Sprachen, wie Java, Scala, Python, R oder SQL.
Delta Lake
Delta Lake ist eine Open-Source Speicherschicht, die für die Verwaltung von Big Data in Data Lakes entwickelt wurde. Delta Lakes erhöhen die Zuverlässigkeit von Data Lakes, indem sie die Datenqualität und Datenkonsistenz von Big Data steigern und Funktionen aus traditionellen Data Warehouses hinzufügen. Delta Lakes unterstützen ACID-Transaktionen, skalierbare Metadaten und Time Traveling durch das Logging aller Transaktionen. Zudem sind Delta Lakes Spark kompatibel und nutzen standardisierte Datenformate, wie Parquet und Json.
Dadurch ermöglichen Delta Lakes die Bildung von einem Lakehouse, welches die Vorteile von Data Lakes und Data Warehouses kombiniert.

MLflow
MLflow ist eine Open-Source-Plattform zur Verwaltung des gesamten Machine-Learning-Lebenszyklus. Es wurde entwickelt, um den Prozess des Trainings, der Verwaltung und der Bereitstellung von Machine-Learning-Modellen zu vereinfachen. MLflow ermöglicht das Protokollieren und Verfolgen von Machine Learning Experimenten während des Modelltrainings und die einfache Bereitstellung von trainierten Modellen als Docker-Container, Python-Funktionen und RESTful API-Endpunkte. MLflow ist kompatibel mit verschiedenen Machine-Learning-Frameworks wie TensorFlow, PyTorch, Scikit-Learn und XGBoost. Es kann unter anderem in Jupyter Notebooks, Apache Spark, Databricks und AWS SageMaker genutzt werden.
D wie: Dataflows Gen2
Dataflows (Gen2) sind eine cloudbasierte ETL-Plattform (Extrahieren, Transformieren und Laden), die es ermöglicht, skalierbare Datentransformationsprozesse zu erstellen und auszuführen. Diese Dataflows ermöglichen das Extrahieren von Daten aus verschiedenen Quellen, deren Transformation durch verschiedene Operationen sowie das Laden in ein definiertes Ziel. Die Verwendung von Power Query Online bietet auch eine grafische Benutzeroberfläche für die Durchführung dieser Aufgaben.
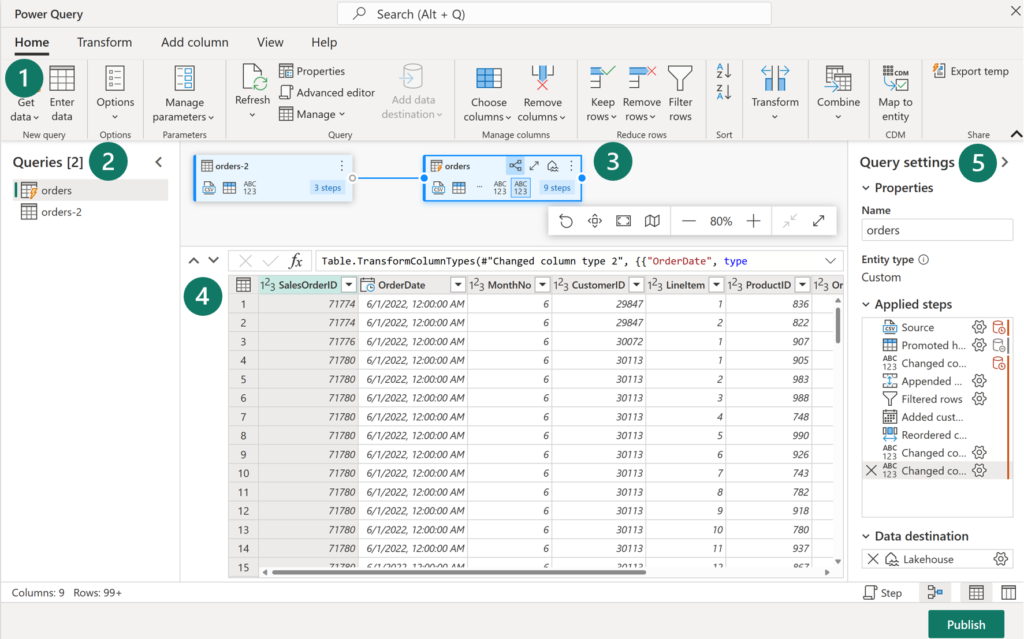
Das Ergebnis der Datenaufbereitung kann in eine neue Tabelle geladen, in eine Datenpipeline eingebunden oder von Datenanalysten als Datenquelle genutzt werden. Das Hauptziel von Dataflows (Gen2) besteht darin, eine einfache, wiederverwendbare Methode zur Durchführung von ETL-Aufgaben über Power Query Online bereitzustellen. Dataflows bieten eine Vielzahl von Transformationen und können manuell, nach einem Aktualisierungszeitplan oder als Teil einer Datenpipelineorchestrierung ausgeführt werden.
Durch die Verwendung von Dataflows (Gen2) können Daten konsistent aufbereitet und in das gewünschte Ziel verschoben werden. Zusätzlich erleichtern sie die Wiederverwendung und Aktualisierung von Daten. Ohne Dataflows müsste die Extraktion und Transformation von Daten manuell aus jeder Quelle erfolgen, was zeitaufwändig und fehleranfällig wäre.
Vorteile von Dataflows
- Konsistente Daten: Dataflows ermöglichen die Extraktion, Transformation und das Laden (ETL) von Daten in einer wiederholbaren und konsistenten Weise.
- Wiederverwendbare ETL-Logik: Dataflows ermöglichen die Implementierung von wiederverwendbarer ETL-Logik. Das bedeutet, dass einmal erstellte Transformationen und Workflows leicht in verschiedenen Projekten oder für unterschiedliche Datensätze wiederverwendet werden können.
- Self-Service-Zugriff: Dataflows ermöglichen es Self-Service-Benutzern, auf eine Teilmenge des Data Warehouse zuzugreifen. Dies fördert die Eigenständigkeit von Benutzern und reduziert die Abhängigkeit von spezialisierten IT-Abteilungen.
- Qualitätssicherung: Dataflows ermöglichen es Benutzern, Daten vor dem Laden in ein Ziel zu bereinigen und zu transformieren. Dies trägt zur Sicherung der Datenqualität bei, indem inkonsistente oder fehlerhafte Daten frühzeitig identifiziert und behoben werden.
- Einfache Datenintegration: Die Plattform stellt eine Low-Code-Schnittstelle bereit, die es ermöglicht, Daten aus verschiedenen Quellen einfach zu erfassen. Dies erleichtert die Integration von Daten ohne umfassende Programmierkenntnisse.
D wie: Data Warehouse
Ein Data Warehouse ist traditionell darauf ausgerichtet, strukturierte Daten aus verschiedenen Quellen zu integrieren und für die Analyse in einer optimierten, leistungsstarken Umgebung bereitzustellen.
Erstellung von einem Data Warehouse
Die Erstellung eines modernen Data Warehouse umfasst in der Regel folgende Schritte:
- Datenerfassung: Verschieben von Daten aus Quellsystemen in ein Data Warehouse
- Datenspeicher: Speichern der Daten in einem Format, das für die Analyse optimiert ist
- Datenverarbeitung: Transformieren der Daten zur Vorbereitung auf die Analyse
- Datenanalyse und -übermittlung: Analysieren der Daten, um Erkenntnisse zu gewinnen und diese bei Geschäftsentscheidungen für das Unternehmen zu berücksichtigen
Modellierung von Faktentabellen und Dimensionstabellen
Die Tabellen in einem Data Warehouse sollten so organisiert sein, dass eine effiziente Analyse großer Datenmengen unterstützt wird. Diese Organisation wird häufig als dimensionale Modellierung bezeichnet, bei der Tabellen in Faktentabellen und Dimensionstabellen strukturiert werden.
- Faktentabellen enthalten die numerischen Daten, welche ausgewertet werden können. Faktentabellen umfassen in der Regel eine große Anzahl von Zeilen und sind die primäre Datenquelle für die Analyse. Beispielsweise kann eine Faktentabelle den Gesamtbetrag enthalten, der für Bestellungen an einem bestimmten Datum oder in einer bestimmten Filiale bezahlt wurde.
- Dimensionstabellen enthalten beschreibende Informationen zu den Daten in den Faktentabellen. Sie weisen in der Regel eine geringe Anzahl von Zeilen auf und werden verwendet, um Kontext für die Daten in den Faktentabellen bereitzustellen. Beispielsweise kann eine Dimensionstabelle Informationen zu den Kunden enthalten, die Bestellungen aufgegeben haben.
Häufig wird ein Data Warehouse als Sternschema organisiert, in dem eine Faktentabelle direkt mit den Dimensionstabellen verknüpft ist.
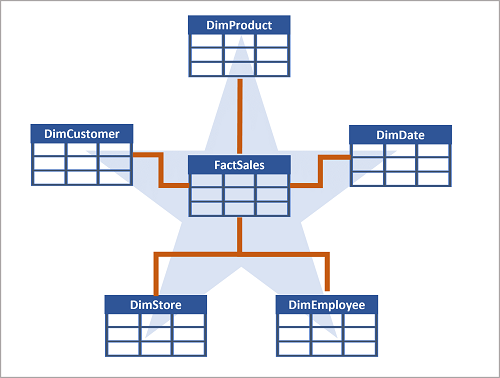
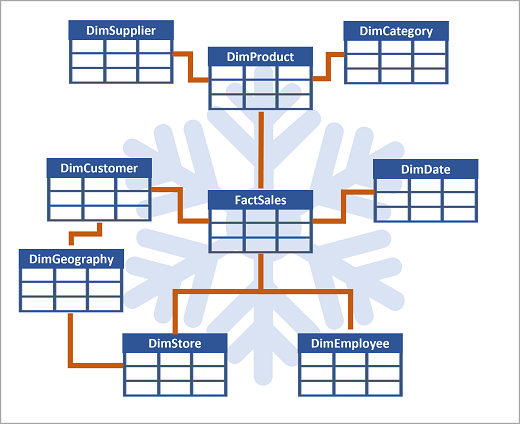
Falls es viele Ebenen gibt oder einige Informationen von verschiedenen Elementen geteilt werden, sollte stattdessen ein Schneeflockenschema genutzt werden.
D wie: Data Analytics vs. Business Intelligence
Unterschiede zwischen BI & Data Analytics
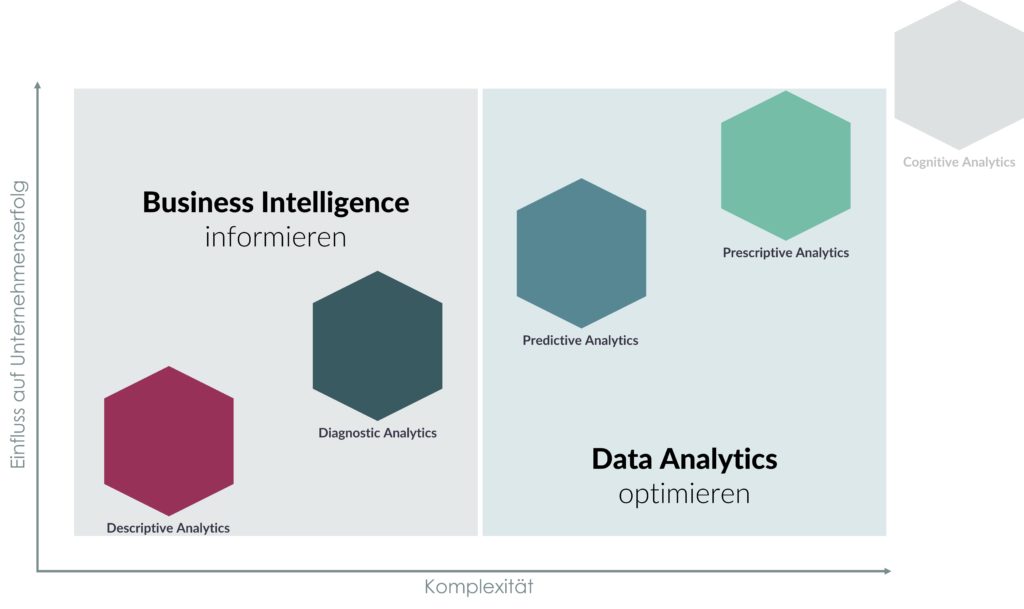
Descriptive Analytics
Bei der deskriptiven Analyse werden Daten statistisch ausgewertet, um festzustellen, was in der Vergangenheit passiert ist. Die deskriptive Analyse hilft einem Unternehmen zu verstehen, wie es funktioniert, indem sie den Beteiligten bei der Interpretation der Informationen hilft. Dies kann in Form von Datenvisualisierungen wie Diagrammen, Tabellen, Berichten und Dashboards geschehen.
Diagnostic Analytics
Die diagnostische Analyse geht bei den beschreibenden Daten noch einen Schritt weiter und bietet eine tiefere Analyse, um die Frage zu beantworten: Warum ist das passiert? Häufig wird die diagnostische Analyse auch als Ursachenanalyse bezeichnet. Dazu gehören Prozesse wie
- Data Discovery,
- Data Mining,
- Drill Down und
- Drill Through.
Predictive Analytics
Bei der prädiktiven Analyse werden historische Daten in ein maschinelles Lernmodell eingespeist, das wichtige Trends und Muster berücksichtigt. Das Modell wird dann auf aktuelle Daten angewendet, um vorherzusagen, was als Nächstes passieren wird.
Prescriptive Analytics
Die präskriptive Analyse hebt prädiktive Daten auf die nächste Stufe. Jetzt, da Sie eine Vorstellung davon haben, was wahrscheinlich in der Zukunft passieren wird, was sollten Sie tun? Es werden verschiedene Handlungsoptionen vorgeschlagen und die potenziellen Auswirkungen der einzelnen Optionen aufgezeigt.
Cognitive Analytics
Cognitive Analytics wendet menschenähnliche Intelligenz auf bestimmte Aufgaben an und vereint eine Reihe von intelligenten Technologien, darunter
- Semantik,
- Algorithmen der künstlichen Intelligenz,
- Deep Learning und
- maschinelles Lernen.
D wie: Data Asset
Data Asset ist ein Begriff, der sich auf Daten als Vermögenswerte oder Ressourcen eines Unternehmens oder einer Organisation bezieht. Dies bedeutet, dass Daten als wertvolle Güter betrachtet werden können, ähnlich wie physische Vermögenswerte wie Gebäude, Maschinen oder Fahrzeuge, Daten bilden die Geschäftsgrundlage von vielen Unternehmen.
Data Assets können aus verschiedenen Arten von Daten bestehen, einschließlich strukturierter Daten, wie sie beispielsweise in Datenbanken gespeichert werden, oder unstrukturierter Daten, wie Texte, Bilder oder Videos. Auch Prozessdaten oder Logdaten können Teil von Data Assets sein.
Nutzen von Data Assets
Unternehmen nutzen Data Assets für verschiedene Zwecke, wie beispielsweise
- zur Verbesserung der Entscheidungsfindung,
- zur Identifizierung von Trends oder
- zur Entwicklung neuer Produkte und Dienstleistungen.
Durch die Analyse von Data Assets können Unternehmen auch Betriebsabläufe optimieren, Risiken minimieren und Wettbewerbsvorteile erlangen.
Es ist wichtig, dass Unternehmen ihre Data Assets sorgfältig verwalten und schützen, da sie oft vertrauliche Informationen enthalten können. Ein Verlust oder Missbrauch von Daten kann erhebliche negative Auswirkungen auf das Unternehmen haben.
Insgesamt sind Data Assets ein wichtiger Bestandteil moderner Unternehmen und Organisationen. Durch die sorgfältige Verwaltung und Nutzung dieser Ressource können Unternehmen ihre Wettbewerbsfähigkeit verbessern und langfristigen Erfolg sichern.
Prozess eines Data Assets
Den Prozess der
- Beschaffung,
- Nachverfolgung,
- Nutzung und
- Optimierung
von Data Assets wird als Data Asset Management bezeichnet.
D wie: Data Catalog
Ein Data Catalog (zu Deutsch: Datenkatalog) ist eine Art Verzeichnis oder Register, das Informationen über Daten innerhalb eines Unternehmens oder einer Organisation enthält. Der Data Catalog ist in der Regel eine zentrale Datenbank, die Informationen über alle verfügbaren Daten und deren Eigenschaften enthält, wie zum Beispiel
- ihre Quelle,
- ihre Struktur,
- ihre Bedeutung oder
- ihren Verwendungszweck.
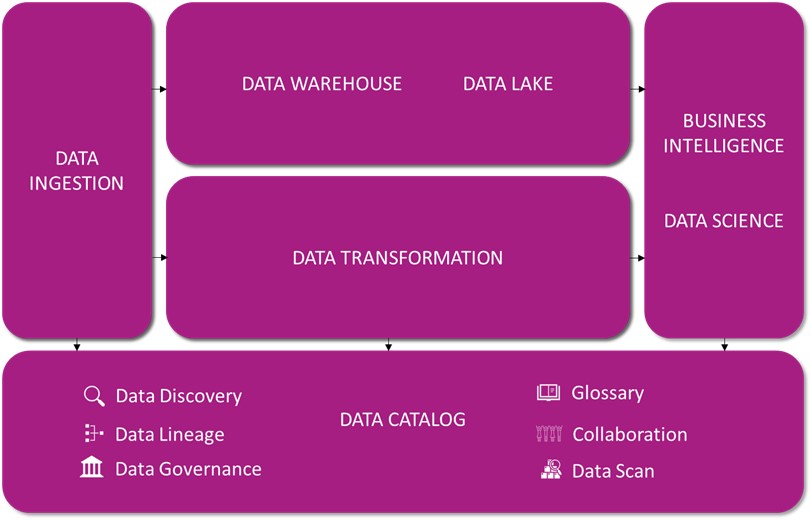
Zweck eines Datenkatalogs
Der Zweck des Data Catalog besteht darin, eine Übersicht über alle verfügbaren Daten im Unternehmen oder in der Organisation zu bieten und so die Auffindbarkeit und Nutzung der Daten zu erleichtern. Durch die Katalogisierung von Daten können Nutzer schnell und einfach auf die benötigten Daten zugreifen, ohne lange suchen zu müssen. Dies kann die Effizienz von Arbeitsabläufen erhöhen und die Entscheidungsfindung verbessern.
Der Data Catalog ist auch ein wichtiger Bestandteil des Datenmanagements, da er es den Verantwortlichen ermöglicht, den Zugriff auf Daten zu kontrollieren und sicherzustellen, dass sie korrekt verwendet werden. Darüber hinaus kann der Data Catalog helfen, die Datenqualität zu verbessern, indem er die Standardisierung von Daten und Metadaten fördert und so sicherstellt, dass alle Nutzer auf dieselben Informationen zugreifen.
Nutzen eines Data Catalogs
Moderne Data Catalogs verwenden oft Künstliche Intelligenz (KI) und Machine-Learning-Algorithmen, um die Verwaltung von Daten zu automatisieren und die Suche nach Daten zu erleichtern. Die Integration von Data Catalogs in das Datenmanagementsystem eines Unternehmens oder einer Organisation kann einen erheblichen Mehrwert schaffen, indem die
- Auffindbarkeit,
- Verfügbarkeit und
- Qualität
von Daten verbessert wird.
D wie: Data Driven Culture
Eine datengesteuerte Kultur ist eine Kultur, in der Daten als grundlegender Bestandteil der Entscheidungsfindungsprozesse eines Unternehmens verwendet werden und in der jede:r Mitarbeiter:In, unabhängig von Position, ermutigt wird, Daten zur Unterstützung der Arbeit zu nutzen. Eine Data Driven Culture sieht Daten als strategisches Gut und als Quelle von Wettbewerbsvorteilen.
Zu den wichtigsten Merkmalen einer datengesteuerten Kultur gehören:
- Datenorientierte Entscheidungsfindung: In einer datengesteuerten Kultur werden Daten als Grundlage und Antrieb für die Entscheidungsfindung auf allen Ebenen des Unternehmens genutzt. Entscheidungen beruhen auf der Analyse von Daten und nicht auf Intuition oder Vermutungen.
- Datenkenntnis: Mitarbeiter:Innen in einer datengesteuerten Kultur verfügen über die notwendigen Fähigkeiten und Kenntnisse, um Daten zu verstehen und mit ihnen zu arbeiten, und sind in Datenanalysetools und -techniken geschult.
- Zugänglichkeit von Daten: Eine datengesteuerte Kultur zeichnet sich durch einen einfachen Zugang zu Daten und Analysetools aus, der es den Mitarbeiter:Innen ermöglicht, mit Daten zu arbeiten und sie zu nutzen.
- Eine Kultur des Experimentierens: In einer datengesteuerten Kultur werden die Mitarbeiter:Innen ermutigt, mit Daten zu experimentieren und sie zu nutzen, um Wachstums- und Verbesserungsmöglichkeiten zu ermitteln.
D wie: Data Governance
Was ist Data Governance?
Data Governance beschreibt eine Reihe von Regeln, Verfahren und Standards, die sicherstellen sollen, dass Daten in Unternehmen
- qualitativ hochwertig sind,
- geschützt werden und
- sinnvoll genutzt werden können.
Dabei legt Data Governance fest, wer welche Daten nutzen darf und wie sie verwendet werden sollen. Außerdem definiert sie die Verantwortlichkeiten für die Qualität und Identifikation von einzelnen Datenbeständen sowie die Steuerung, Überwachung und Ausführung von datenbasierten Prozessen. Darüber hinaus regelt sie den Zugriff der Mitarbeiter auf relevante Daten.
Insgesamt hilft Data Governance Unternehmen dabei, den digitalen Wandel erfolgreich zu gestalten, indem sie sichere und wirtschaftliche Abläufe, konsistente Daten und valide Analyseergebnisse gewährleistet. Dadurch können Risiken gesteuert und Kosten reduziert werden, während gleichzeitig der größtmögliche Wert aus den vorhandenen Daten für das Unternehmen generiert wird.
Vorteile von Data Governance
Gemeinsames Datenverständnis
Durch Data Governance entsteht ein gemeinsames Verständnis der Daten, wodurch eine einheitliche Sicht auf die Daten und eine einheitliche Terminologie erreicht wird. Dabei können die einzelnen Geschäftseinheiten ihre Flexibilität behalten und dennoch auf eine einheitliche Datenbasis zugreifen.
Verbesserte Datenqualität
Ein gut durchdachter Data Governance-Plan sorgt für eine verbesserte Datenqualität, indem er die Genauigkeit, Vollständigkeit und Konsistenz der Daten sicherstellt. Dadurch wird gewährleistet, dass die Daten zuverlässig sind und für die verschiedenen Geschäftseinheiten nutzbar sind.
Durchgehende Compliance
Data Governance trägt zur durchgehenden Compliance bei, indem sie sicherstellt, dass gesetzliche Vorgaben wie die DSGVO (EU-Datenschutz-Grundverordnung), der US-HIPAA (Health Insurance Portability and Accountability Act) sowie branchenspezifische Anforderungen wie der PCI-DSS (Payment Card Industry Data Security Standards) eingehalten werden. Dadurch wird gewährleistet, dass das Unternehmen gesetzliche Vorgaben erfüllt und Strafen sowie Reputationsverluste vermieden werden können.
Single Source of Truth (SSoT)
Durch Data Governance können Organisationen eine 360-Grad-Sicht auf ihre Kunden und andere Geschäftseinheiten erlangen, indem sie eine „einzige Version der Wahrheit“ für zentrale Geschäftseinheiten festlegen und ein angemessenes Maß an Einheitlichkeit über verschiedene Einheiten und Geschäftsaktivitäten hinweg schaffen. Dadurch wird sichergestellt, dass alle Abteilungen und Geschäftsbereiche auf die gleichen Informationen zugreifen und eine konsistente Sicht auf die Geschäftsaktivitäten des Unternehmens haben.
Was Data Governance nicht ist
Data Governance ist nicht dasselbe wie Datenmanagement. Datenmanagement bezieht sich auf die Verwaltung des gesamten Lebenszyklus von Daten innerhalb einer Organisation. Data Governance ist ein zentraler Bestandteil des Datenmanagements und verbindet neun weitere Konzepte, wie beispielsweise
- Datenqualität,
- Referenz- und Stammdatenmanagement,
- Datensicherheit,
- Datenbankprozesse,
- Metadatenmanagement und
- Data Warehousing.
Data Governance ist auch nicht dasselbe wie Data Stewardship. Data Governance sorgt dafür, dass die richtigen Personen die richtigen Datenverantwortlichkeiten zugewiesen bekommen. Data Stewardship bezieht sich auf die notwendigen Aufgaben, um sicherzustellen, dass die Daten genau, kontrolliert und von den richtigen Benutzergruppen einfach zu finden und zu verarbeiten sind. Während es bei Data Governance in erster Linie um Strategie, Rollen, Organisation und Richtlinien geht, konzentriert sich Data Stewardship auf die Ausführung und Operationalisierung.
Data Governance ist auch nicht dasselbe wie Stammdatenmanagement. Das Stammdatenmanagement konzentriert sich darauf, wichtige Bereiche einer Organisation zu identifizieren und dann die Qualität dieser Daten zu verbessern. Es stellt sicher, dass Sie die vollständigsten und genauesten verfügbaren Informationen zu wichtigen Bereichen wie Kunden, Auftragnehmer, medizinische Dienstleister usw. haben.
D wie: Data Governance Framework
Was ist ein Data Governance Framework?
Ein Data Governance Framework ist ein systematischer Ansatz, der Richtlinien, Prozesse, Strukturen und Mechanismen bereitstellt, um die Verwaltung und Nutzung von Daten in einer Organisation zu steuern. Es bildet einen Rahmen, der sicherstellt, dass Daten von hoher Qualität, konsistent, sicher und vertrauenswürdig sind, um fundierte Geschäftsentscheidungen zu unterstützen und Risiken zu minimieren.
Das Data Governance Framework beinhaltet die Inventarisierung aller Datenquellen, die Einhaltung der Datenschutzrichtlinien und die Verbesserung der Datenqualität. Im nächsten Schritt werden die Rollen und Verantwortlichkeiten definiert, ein Berechtigungskonzept implementiert und das Bewusstsein der Mitarbeiter für das Data Governance gestärkt. Anschließend erfolgt das Management des Daten-Lebenszyklus, die Steigerung der Data Literacy im Unternehmen und die Analyse der Daten zur Unterstützung von Geschäftsentscheidungen.
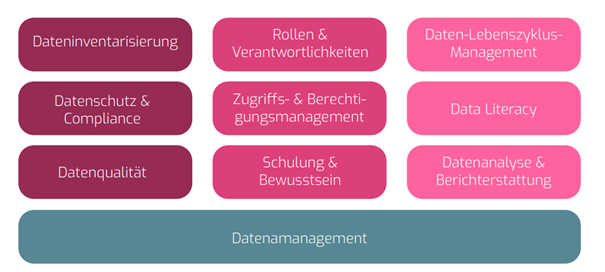
Praxisbeispiele Data Governance Framework
Ein internationales Unternehmen möchte seine Data Governance verbessern, um sicherzustellen, dass die Daten korrekt, sicher und gesetzeskonform verwaltet werden. Das Unternehmen erkennt die Bedeutung von Daten für seine Geschäftsprozesse, Kundenbeziehungen und strategischen Entscheidungen. Daher plant es, eine umfassende Data-Governance-Strategie in folgenden Schritten zu implementieren:
Dateninventarisierung
Das Unternehmen beginnt damit, alle Datenquellen und -ressourcen zu identifizieren, die es besitzt oder nutzt.
Datenschutz und Compliance
Das Unternehmen überprüft seine Datenschutzrichtlinien und -verfahren, um sicherzustellen, dass sie den geltenden Datenschutzgesetzen und -bestimmungen entsprechen
Datenqualität
Das Unternehmen implementiert Prozesse, um die Datenqualität zu überwachen und zu verbessern
Zugriffs- und Berechtigungsmanagement
Das Unternehmen führt ein Zugriffsund Berechtigungsmanagement ein, um sicherzustellen, dass die Daten nur von autorisierten Personen eingesehen und bearbeitet werden können.
Daten-Lebenszyklus-Management
Das Unternehmen entwickelt Richtlinien und Verfahren für das Daten-Lebenszyklus-Management, von der Datenerfassung über die Speicherung, Archivierung bis zur Löschung.
Datenanalyse und Berichterstattung
Das Unternehmen implementiert Systeme zur Datenanalyse und Berichterstattung, um den Benutzern den Zugriff auf aktuelle und relevante Informationen zu ermöglichen. Es stellt sicher, dass die Datenanalysen auf vertrauenswürdigen und qualitativ hochwertigen Daten basieren.
Schulung und Bewusstsein
Das Unternehmen führt Schulungen und Trainings für die Mitarbeiter durch, um sie über die Bedeutung von Data Governance und die Einhaltung der Richtlinien zu informieren.
Fazit
Durch die Umsetzung des Data Governance Frameworks kann das Unternehmen seine Daten effektiver nutzen. Es verbessert die Datenqualität, schützt sensible Informationen, erhöht die Datenintegrität und stellt die Einhaltung der Datenschutzvorschriften sicher. Dadurch wird das Unternehmen in der Lage sein, fundierte Geschäftsentscheidungen zu treffen und einen Mehrwert aus seinen Daten zu ziehen.
D wie: Data Intelligence
Data Intelligence bezieht sich auf die Nutzung von Daten durch Sammlung, Verarbeitung und Analyse, um wertvolle Erkenntnisse zu gewinnen. Es ermöglicht fundierte Entscheidungen, verbesserte Geschäftsprozesse und wettbewerbsfähige Vorteile durch den Einsatz von fortschrittlichen Analysetechniken wie maschinellem Lernen und künstlicher Intelligenz.
Data Governance Reifegrad
Ein wichtiger Aspekt des Konzepts „Data Intelligence“ betrifft die Entwicklung von Data Intelligence Reifegraden, die den Fortschritt und die Effektivität einer Organisation bei der Nutzung von Daten zur Informationsgewinnung und Entscheidungsfindung bewerten. Im Folgenden werden die Reifegrade im Detail erläutert.

Data Integration (Stufe 1)
In dieser Ausgangsstufe stehen die Grundlagen der Datenintegration im Vordergrund. Daten werden aus verschiedenen Quellen extrahiert, transformiert und geladen (ETL) sowie in einem zentralen Repository gespeichert. Die Schwerpunkte liegen auf der Konsolidierung von Daten und der Gewährleistung ihrer Konsistenz. Datenintegrationstechnologien wie ETL-Tools werden verwendet, um den Prozess zu automatisieren und die Effizienz zu steigern.
Data Integrity (Stufe 2)
Datenintegrität bezieht sich auf die Qualität und Genauigkeit von Daten sowie darauf, sicherzustellen, dass Data Governance Reifegrad Daten während ihres gesamten Lebenszyklus korrekt, vollständig, konsistent und vor unerwünschten Änderungen geschützt bleiben. Ein höherer Data Integrity Reifegrad deutet auf eine stärkere Sicherung und Verwaltung der Datenqualität hin.
Data Intelligence (Stufe 3)
Auf dieser letzten Stufe des Reifegrads geht es darum, Daten in einen strategischen Vermögenswert zu verwandeln. Data Intelligence beinhaltet nicht nur die Sammlung und Analyse von Daten, sondern auch die Integration von Erkenntnissen in den Geschäftsprozess. Hier werden Daten genutzt, um innovative Lösungen zu entwickeln, Geschäftsmodelle zu verbessern und Wettbewerbsvorteile zu erzielen.
D wie: Data Literacy
Data Literacy bezieht sich auf die Fähigkeit einer Person, Daten zu verstehen, zu interpretieren, zu analysieren und kritisch zu bewerten. Eine datenkompetente Person ist in der Lage, Datenquellen zu identifizieren, Daten zu sammeln oder zu beschaffen, sie in sinnvolle Zusammenhänge zu setzen und daraus Erkenntnisse zu gewinnen.
D wie: Data Ownership
Definition von Rollen und Verantwortlichkeiten
Im nächsten Schritt werden klare Rollen und Verantwortlichkeiten für die Datenverwaltung definiert. Dies ermöglicht es, Data Owner und Data Stewards zu benennen, die für bestimmte Datendomänen und Datenkategorien verantwortlich sind. Die Data Owner sind für die Datenklarheit, Qualität und Aktualität zuständig, während die Data Stewards operative Aufgaben im Zusammenhang mit den Daten übernehmen. Zudem wird eine Data Governance Stabstelle (DGS) definiert. Die DGS verantwortet Standards, Prozesse, Policies und ist für den Bereich Organisationsveränderung und Data Literacy zuständig.
Klare Verantwortungen und Regeln sorgen dafür, dass Anwender die jeweiligen Ansprechpartner und festgelegte Prozesse zu den einzelnen Data Assets vorfinden.
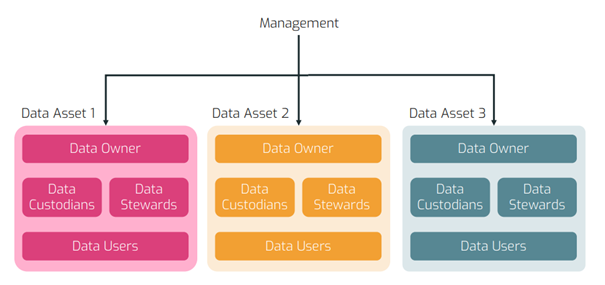
Rollen & Begriffe im Detail
Data Steward
Data Stewardship-Programme stellen sicher, dass leicht zugängliche, konsistente und qualitativ hochwertige Daten für die Mitarbeiter entstehen. Ein Data Stewardship-Programm umfasst folgende Punkte: » Datenqualitätsprogramme inklusive Qualitätskennzahlen sowie Qualitätserkennungs- und Korrekturverfahren. » Informationen und Richtlinien zum Datenlebenszyklusmanagement. » Datenschutz und Risikomanagement. » Unternehmensrichtlinien und -verfahren für den Datenzugriff.
Data Owner
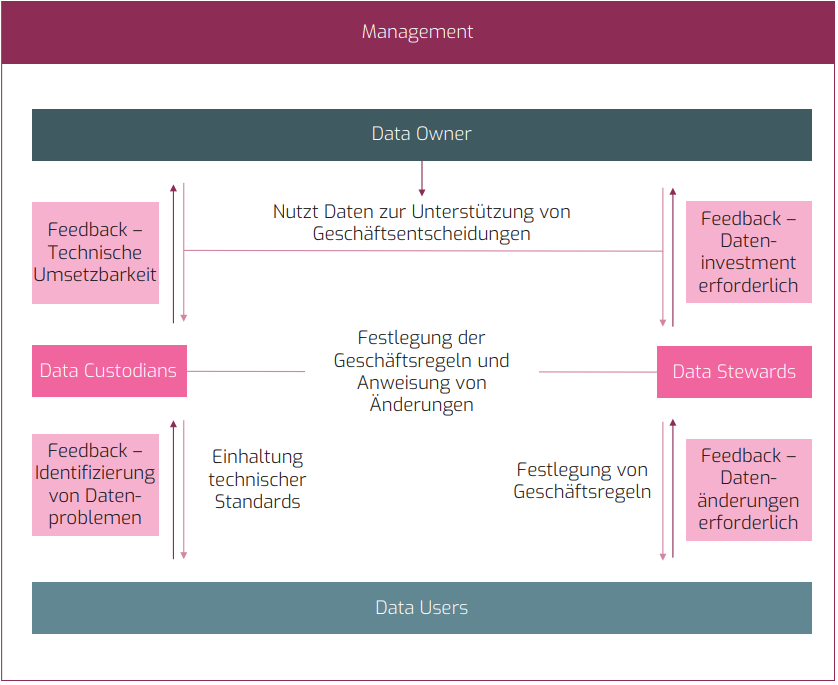
Ein Data Owner (Datenbesitzer) ist eine Einzelperson, eine Organisation oder eine Abteilung, die die Verantwortung für die Daten innerhalb eines Unternehmens oder einer Organisation trägt. Der Data Owner ist für die Kontrolle, den Schutz, die Integrität und die Verwaltung der Daten verantwortlich, die in seinem Besitz sind.
Data Custodian
Data Custodians (Datenverwalter) implementieren und pflegen die geschäftlichen und technischen Regeln zur Verwaltung eines Datensatzes, die vom zuständigen Data Steward festgelegt werden. Sie sind für die sichere Verwahrung, den Transport und die Speicherung von Daten verantwortlich.
Data Asset
Ein Data Asset (Datenwert) bezeichnet eine Datenressource oder einen Datensatz, der für ein Unternehmen, eine Organisation oder eine Einzelperson einen wirtschaftlichen oder strategischen Wert hat. Es handelt sich dabei um Daten, die einen Nutzen oder einen Beitrag zur Erreichung von Geschäftszielen liefern können. Data Assets können sowohl strukturierte Daten (z. B. Kundendaten, Verkaufsdaten, Bestandsdaten) als auch unstrukturierte Daten (z. B. Texte, Bilder, Videos) umfassen.
D wie: Data Quality
Datenqualität ist entscheidend für erfolgreiche Data Governance. Sie misst die Verlässlichkeit von Daten in Bezug auf Genauigkeit, Vollständigkeit, Gültigkeit und mehr. Die sechs wichtigsten Aspekte hierbei sind:
- Relevanz: Daten müssen dem vorgesehen Gebrauch entsprechen.
- Genauigkeit: Daten müssen fehlerfrei und präzise sein.
- Integrität: Daten müssen konsistent und zuverlässig sein.
- Aktualität: Daten müssen immer so zeitnah wie möglich verfügbar sein.
- Konsistenz: Daten sollten einheitlich und wiederspruchsfrei sein.
- Vollständigkeit: Daten sollten alle erforderlichen Infromationen haben.
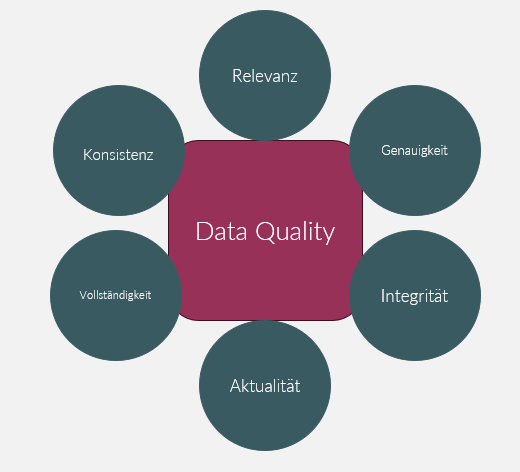
Der Fokus auf diese Aspekte ist nicht nur wichtig, sondern auch essenziell für fundierte Geschäftsentscheidungen und den Erfolg eines Unternehmens. Um eine gute Datenqualität zu erreichen, erfordert es kontinuierliche Überwachung, schnelle Lösungen, Unterstützung von Geschäftsexperten, menschliche Verantwortung und das Verständnis von Datenqualität im Entscheidungsprozess.
D wie: Data Steward
Data Steward Definition
Ein Data Steward ist eine Person oder ein Team, das für die Verwaltung und Aufrechterhaltung der Datenqualität und Datenintegrität in einem Unternehmen verantwortlich ist. Ihr Hauptziel besteht darin, sicherzustellen, dass die gesammelten Daten korrekt, konsistent, aktuell und für die relevanten Stakeholder zugänglich sind.
Verantwortlichkeiten eines Data Stewards
a) Datenqualitätssicherung: Data Stewards überwachen die Datenqualität und führen Maßnahmen durch, um sicherzustellen, dass die Daten genau und vollständig sind. Sie entwickeln Standards, Richtlinien und Prozesse zur Datenbereinigung und -verbesserung.
b) Datenintegration und -harmonisierung: Sie stellen sicher, dass verschiedene Datensätze und Datenbanken innerhalb des Unternehmens miteinander integriert und harmonisiert werden. Dadurch wird die Konsistenz und Interoperabilität der Daten gewährleistet.
c) Metadatenverwaltung: Data Stewards erfassen und verwalten Metadaten, die Informationen über die Daten liefern. Dies umfasst beispielsweise Informationen zur Herkunft, Bedeutung, Struktur und Verwendung der Daten. Dadurch wird die Nachvollziehbarkeit und Verständlichkeit der Daten verbessert.
d) Datenschutz und Compliance: Sie stellen sicher, dass die Datenverwaltung den geltenden Datenschutzrichtlinien und -vorschriften entspricht. Sie unterstützen bei der Identifizierung und Bewältigung von Datenschutzrisiken und arbeiten eng mit Datenschutzbeauftragten zusammen.
e) Zusammenarbeit mit Stakeholdern: Data Stewards arbeiten mit verschiedenen Geschäftsbereichen zusammen, um deren Datenbedürfnisse zu verstehen und sicherzustellen, dass die bereitgestellten Daten ihren Anforderungen entsprechen. Sie fungieren als Bindeglied zwischen den Fachabteilungen und der IT-Abteilung.
D wie: Datenpodukte
Datenprodukte Definition
Im Kontext von Datenprodukten wird das Konzept von Produkten auf Daten angewendet. Das bedeutet, es gibt Produzenten, die Daten als ihr Produkt anbieten, und Konsumenten, die in ähnlicher Weise wie Kunden behandelt werden. Dies ergibt sich aus der Anwendung des Data-Mesh-Prinzips „Daten als Produkt“ auf die Art und Weise, wie Unternehmen Daten verwalten.
Datenprodukte werden von den entsprechenden Geschäftsbereichen verwaltet und einer Qualitätsprüfung unterzogen, bevor sie auf einem Self-Service-Marktplatz für alle im Unternehmen aufbereitet und zur Verfügung gestellt werden. Business-Anwender können diese Datenprodukte dann für ihre spezifischen Anwendungsfälle nutzen.
Der Mehrwert von Datenprodukten liegt darin, dass sie Unternehmen ermöglichen, große Mengen von Daten, die sie sammeln und generieren, schnell und effizient zu verwalten, zu organisieren und sinnvoll zu nutzen. Dies erleichtert den Nutzern der Daten die Gewinnung von Erkenntnissen, eine effiziente Nutzung und die Möglichkeit, auf dieser Grundlage fundiertere Entscheidungen zu treffen.
D wie: DAX
DAX, kurz für Data Analysis Expressions, ist eine leistungsstarke Sprache für Datenanalyse, die in Microsoft Power BI, Excel Power Pivot und anderen Microsoft-Produkten verwendet wird. DAX ermöglicht es Benutzern, komplexe Datenmodelle zu erstellen, die auf große Datenmengen zugreifen und mithilfe von Formeln, Funktionen und Aggregationen analytische Erkenntnisse gewinnen können.
Die Grundlagen von DAX
DAX wurde entwickelt, um die Erstellung von Datenmodellen zu vereinfachen und die Abfrage von Daten zu beschleunigen. Die Sprache basiert auf einer Reihe von Funktionen, die ähnlich wie in Excel verwendet werden können, um Daten zu filtern, aggregieren und berechnen. Eine wichtige Funktion des DAX ist die Verwendung von Tabellen, die in der Regel aus einer Datenbank oder einem anderen Datensatz stammen. Diese Tabellen können dann mithilfe von DAX-Funktionen und -Formeln miteinander verknüpft werden, um komplexe Datenmodelle zu erstellen.
DAX-Funktionen
Eine der nützlichsten Funktionen von DAX ist die Möglichkeit, Aggregationen durchzuführen. Aggregationen sind eine Möglichkeit, um aus einer großen Datenmenge eine Zusammenfassung zu erstellen, die einfacher zu analysieren ist. DAX bietet verschiedene Aggregationsfunktionen wie
- SUM,
- AVERAGE,
- COUNT und
- MIN/MAX.
Diese Funktionen können verwendet werden, um schnell und einfach Zusammenfassungen zu erstellen und Trends in den Daten zu identifizieren.
Eine weitere wichtige Funktion von DAX ist die Möglichkeit, Filter anzuwenden. Filter ermöglichen es Benutzern, Daten zu filtern und nur die Daten anzuzeigen, die für ihre Analyse relevant sind. Filter können auch in Verbindung mit Aggregationsfunktionen verwendet werden, um genaue Ergebnisse zu erzielen. DAX bietet verschiedene Filterfunktionen wie
- ALL,
- FILTER und
- CALCULATETABLE,
die Benutzer:Innen die Flexibilität geben, ihre Datenanalyse auf ihre Bedürfnisse anzupassen.
Code-Beispiele
SUM (gibt die Summe der Spalte ‚Column‘)
SUM(‚Table'[Column])
AVERAGE (gibt den Durchschnittswert der Spalte ‚Column‘)
AVERAGE(‚Table'[Column])
CALCULATE (gibt die Summe der Spalte ‚Column‘, welche das Wort „Value“ in Column2 haben)
CALCULATE(SUM(‚Table'[Column]), ‚Table'[Column2] = „Value“)
Wenn Sie mehr über DAX und seine Anwendung in der Datenanalyse oder Business Intelligence erfahren möchten zögern Sie nicht uns zu kontaktieren.
D wie: Deep Learning
Definition von Deep Learning
- Deep Learning ist eine fortgeschrittene Form des Machine Learning, die auf künstlichen neuronalen Netzwerken basiert.
- Die Netzwerke bestehen aus mehreren Schichten von Neuronen, die Daten durch komplexe Transformationen verarbeiten.
- Deep Learning ist besonders effektiv bei der Verarbeitung unstrukturierter Daten wie Bildern, Texten und Sprache.
- Technologien zur Entwicklung von Deep Learning Modellen sind beispielsweise TensorFlow, Keras und PyTorch
Methoden im Deep Learning
- Artificial Neural Networks
- Convolutional Neural Networks
- Recurrent Neural Networks
- Deep Reinforcement Learning
- Generative Adversarial Networks
- AutoEncoders
Anwendungsmöglichkeiten im Deep Learning
- Bilderkennung
- Sprachverarbeitung
- Autonomes Fahren
- Generative KI
D wie: Delta Lake
Delta Lake ist eine Open-Source Speicherschicht, die für die Verwaltung von Big Data in Data Lakes entwickelt wurde. Delta Lakes erhöhen die Zuverlässigkeit von Data Lakes, indem sie die Datenqualität und Datenkonsistenz von Big Data steigern und Funktionen aus traditionellen Data Warehouses hinzufügen.
Dadurch ermöglichen Delta Lakes die Bildung von einem Lakehouse, welches die Vorteile von Data Lakes und Data Warehouses kombiniert.
Delta Tabellen
Deltatabellen sind Schemaabstraktionen für Datendateien, die im Deltaformat gespeichert sind. Für jede Tabelle legt das Lakehouse einen Ordner mit Parquet-Datendateien und einem Ordner namens _delta_log an, in dem die Transaktionsdetails im JSON-Format protokolliert werden.
Vorteile eines Delta Lakes
- Durch Relationale Tabellen werden Abfrage- und Datenänderungen unterstützt, sodass wie in einem relationalen Datenbanksystem Datenzeilen ausgewählt, eingefügt, aktualisiert und gelöscht werden können.
- Delta Lakes unterstützen ACID-Transaktionen, sodass bei Datenänderungen die Atomarität (Transaktionen werden als eine einzelne Arbeitseinheit abgeschlossen), Konsistenz (Transaktionen verlassen die Datenbank in einem konsistenten Zustand), Isolation (laufende Transaktionen können sich nicht gegenseitig beeinträchtigen) und Dauerhaftigkeit (wenn eine Transaktion abgeschlossen ist, werden die vorgenommenen Änderungen dauerhaft gespeichert) gewährleistet wird.
- Da alle Transaktionen im Transaktionsprotokoll gespeichert werden, können mehrere Versionen jeder Tabelle nachverfolgt und mithilfe von Zeitreisen frühere Versionen wiederhergestellt werden.
- Delta Lakes sind Spark kompatibel und nutzen standardisierte Datenformate, wie Parquet und Json. Zudem können Deltatabellen in SQL abgefragt werden.
- Spark bietet über die Spark Structured Streaming-API native Unterstützung für Streaming-Daten. Delta Lake Tabellen können dadurch sowohl als Senken als auch als Quellen für Batch- und Streaming-Daten dienen.
D wie: Denodo

Denodo, eine bekannte Datenvirtualisierungsplattform, spielt eine entscheidende Rolle im Kontext von Data Governance. Data Governance ist der Prozess, der sicherstellt, dass Daten in einer Organisation effizient und verantwortungsvoll verwaltet werden, und Denodo ist ein leistungsstarkes Werkzeug, um dieses Ziel zu erreichen.
Insgesamt unterstützt Denodo Data Governance, indem es die Integration, Kontrolle, Qualität und Transparenz von Daten verbessert. Die Plattform erleichtert die Einhaltung von Datenschutz- und Compliance-Anforderungen, was in der heutigen datengetriebenen Geschäftswelt von entscheidender Bedeutung ist.
Hier sind einige wichtige Punkte in Bezug auf Denodo und Data Governance:
Datenintegration und Zugriffskontrolle
Denodo ermöglicht eine nahtlose Integration von Daten aus verschiedenen Quellen, einschließlich heterogener Datenbanken und Anwendungen. Durch die Zentralisierung von Datenzugriff und -kontrolle können Organisationen sicherstellen, dass nur autorisierte Benutzer auf bestimmte Daten zugreifen.
Datenqualität und -konsistenz
Data Governance beinhaltet oft die Aufrechterhaltung von Datenqualität und Konsistenz. Mit Denodo können Datenbereinigung und -transformation durchgeführt werden, um sicherzustellen, dass die Daten hochwertig und konsistent sind, bevor sie in Data-Governance-Initiativen einfließen.
Metadatenverwaltung
Denodo bietet umfangreiche Metadatenverwaltungsfunktionen, die dazu beitragen, den Ursprung und die Bedeutung der Daten zu dokumentieren. Dies ist entscheidend für die Einhaltung von Datenschutzbestimmungen und die Verfolgung von Datenflüssen.
Datenzugriffsrichtlinien
Durch die Erstellung von Datenzugriffsrichtlinien und -kontrollen in Denodo können Organisationen sicherstellen, dass Daten nur von berechtigten Personen eingesehen und verwendet werden.
Data Lineage und Auditing
Data Governance erfordert oft die Möglichkeit, den Datenfluss zu verfolgen und zu überwachen. Denodo ermöglicht dies durch Data-Lineage-Funktionen und Auditing, um sicherzustellen, dass Datenbewegungen nachvollziehbar sind.
Zusammenarbeit und Reporting
Denodo erleichtert die Zusammenarbeit zwischen verschiedenen Abteilungen in Bezug auf Daten und bietet leistungsstarke Reporting-Funktionen, um Einblicke in Datenverwendung und -qualität zu gewinnen.
H wie:
H wie: Hyperparameter
Was sind Hyperparameter bei neuronalen Netzen
Beispiele für Hyperparameter von neuronalen Netzen sind die
- Lernrate,
- Batchgröße und
- Menge an Epochen sowie
- die Anzahl an Hidden Layers und
- die Anzahl deren Neuronen.
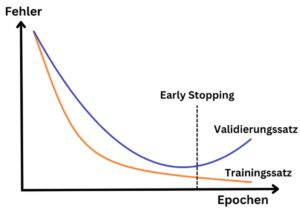
Details zu Architektur & Funktionsweise neuronaler Netze, Lernrate, Batchgröße, Epochen, Hidden Layers, Neuronen, Aktivierungsfunktion sowie Kostenfunktion findet ihr im Impuls Architektur und Funktionsweise von neuronalen Netzen.
I wie:
I wie: Informationsvisualisierung
Was ist Informationsvisualisierung?
Die Informationsvisualisierung ist ein Prozess, bei dem Daten und Informationen mithilfe visueller Darstellungen in graphischer Form dargestellt werden, um sie verständlicher, interpretierbarer und zugänglicher zu machen. Das Ziel der Informationsvisualisierung besteht darin, komplexe Daten und Zusammenhänge auf eine Weise zu präsentieren, die es den Menschen ermöglicht, Muster, Trends, Abweichungen und Erkenntnisse schnell zu erkennen.
Einige bekannte Beispiele für Informationsvisualisierung sind Balkendiagramme, Liniendiagramme, Tortendiagramme, Streudiagramme, geografische Karten, Word Clouds und Heatmaps. Informationsvisualisierung spielt eine wichtige Rolle in der heutigen datengesteuerten Welt und ermöglicht es Menschen, Daten effektiv zu nutzen, um bessere Entscheidungen zu treffen und komplexe Informationen zu verstehen.
K wie:
K wie: Künstliche Intelligenz (KI/AI)
Definition Künstliche Intelligenz (KI)
- Künstliche Intelligenz ist ein Zweig der Informatik.
- Es bezeichnet die Fähigkeit von Maschinen, selbstständig Aufgaben auszuführen, für die normalerweise menschliche Intelligenz erforderlich ist, beispielsweise logisches Denken, Problemlösung und das Lernen aus Erfahrungen.
- Teilbereiche der Künstlichen Intelligenz sind unter anderem Spracherkennung, Bildverarbeitung und Entscheidungsfindung.
- KI-Systeme werden entweder auf Regeln basierend oder durch maschinelles Lernen entwickelt.
Anwendungsmöglichkeiten von Artificial Intelligence (AI)
- Systeme zur Problemlösung und Entscheidungsfindung
- Chatbots
- Expertensysteme
- Spielautomaten
Teilgebiete von KI
Während KI den Oberbegriff für Maschinenintelligenz darstellt, ist Machine Learning eine Technik, die es Maschinen ermöglicht, aus Erfahrungen zu lernen, und Deep Learning ist eine spezifische Methode des Machine Learnings, die auf tiefen neuronalen Netzwerken basiert.
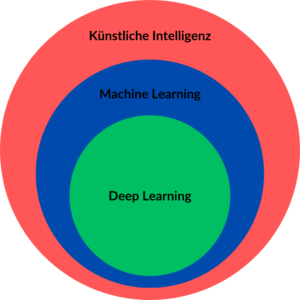
Weitere Teilgebiete der künstlichen Intelligenz sind unter anderem Robotik, Expertensysteme und Natural Language Processing.
L wie:
L wie: Lakehouse
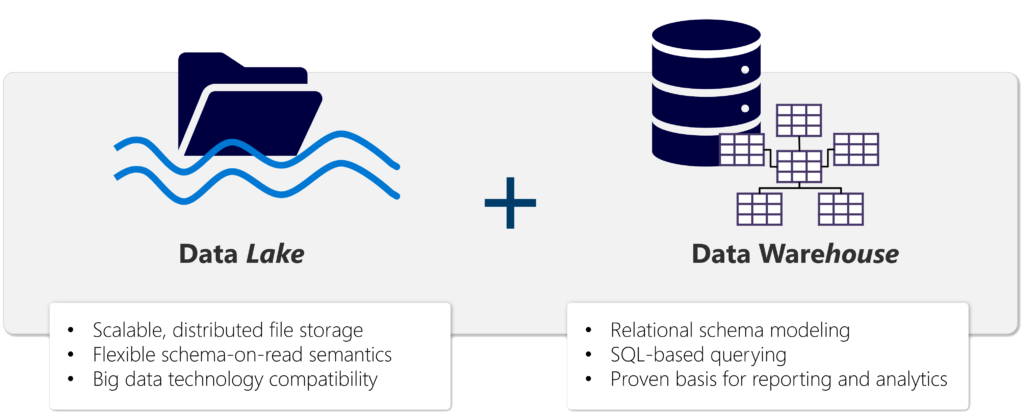
Ein Lakehouse ist eine Architektur, die Elemente sowohl von Data Warehouses als auch von Data Lakes kombiniert. Diese Kombination soll die Vorteile beider Ansätze nutzen, um eine umfassendere und flexiblere Plattform für die Verwaltung und Analyse von Daten zu schaffen.
Ein Data Warehouse ist traditionell darauf ausgerichtet, strukturierte Daten aus verschiedenen Quellen zu integrieren und für die Analyse in einer optimierten, leistungsstarken Umgebung bereitzustellen. Data Lakes hingegen sind flexiblere Speicherumgebungen, die eine breite Palette von strukturierten, unstrukturierten und halbstrukturierten Daten in ihrem nativen Format aufnehmen können.
Lakehouses kombinieren die SQL-basierten Analysefunktionen eines relationalen Data Warehouse mit der Flexibilität und Skalierbarkeit eines Data Lake. Ein Lakehouse ermöglicht es Unternehmen, sowohl strukturierte als auch unstrukturierte Daten in einem zentralen Repository zu speichern und sie für Analysezwecke zu nutzen, unabhängig von der Datenform oder -quelle.
Vorteile eines Lakehouses
- Lakehouses verwenden Spark- und SQL-Engines, um große Datenmengen zu verarbeiten und Maschinelles Lernen zu unterstützen.
- Lakehouse-Daten sind in einem Schema-on-Read-Format organisiert. Das bedeutet, dass Sie das Schema nach Bedarf definieren, anstatt ein vordefiniertes Schema nutzen.
- Lakehouses unterstützen ACID-Transaktionen (Atomicity, Consistency, Isolation, Durability – Unteilbarkeit, Konsistenz, Isolation, Dauerhaftigkeit) mithilfe von Delta Lake-formatierten Tabellen für Datenkonsistenz und -integrität.
- Bei Lakehouses handelt es sich um einen einzigen Standort für Data Engineers, Data Scientists und Datenanalysten, um auf Daten zuzugreifen und diese zu verwenden.
L wie: Lernen von Algorithmen
Lernen am Beispiel von neuronalen Netzen
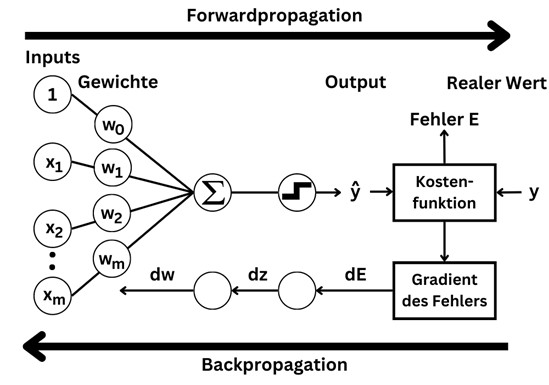
Beim Training eines neuronalen Netzes geht es darum, die Gewichte der Koeffizienten einzustellen. Je mehr Kanten es gibt, desto mehr Parameter muss das Modell lernen. Zum Lernen werden Trainingsdaten mit (x, y) Wertepaaren benötigt, wobei x den Input-Vektor mit den Werten für die einzelnen Features beschreibt und y die Zielvariable(n) enthält. Während des Trainings passt das neuronale Netz die Gewichte der Kanten so an, dass die Output-Neuronen möglichst ähnliche Werte zu y generieren, wenn x als Eingabewerte an die Input Layer übergeben wird.
Das neuronale Netz erzeugt durch eine Forwardpropagation von der Input Layer zur Output Layer Vorhersagen und beim Training lernt das neuronale Netz die richtige Einstellung der Parameter dadurch, dass der Fehler bei der Backpropagation in der entgegengesetzten Richtung zurückgegeben wird.
Details zu Architektur & Funktionsweise neuronaler Netze, Forwardpropagation, Backwordpropagation, Hyperparameter, Aktivierungsfunktion sowie Kostenfunktion findet ihr im Impuls Architektur und Funktionsweise von neuronalen Netzen.
M wie:
M wie: Machine Learning
Definition Machine Learning
- Machine Learning ist ein Teilgebiet der Künstlichen Intelligenz, das sich darauf konzentriert, Algorithmen zu entwickeln, die aus Daten lernen können, ohne explizit programmiert zu werden.
- Durch die Generierung von Wissen aus Erfahrungen lernen künstliche Systeme aus Beispielen und können diese nach Abschluss der Lernphase verallgemeinern. Das bedeutet, es werden nicht einfach die Beispiele auswendig gelernt, sondern es erkennt Muster und Gesetzmäßigkeiten in den Lerndaten.
- Durch einen Lerntransfer kann das System auch unbekannte Daten beurteilen oder aber aufgrund einer Überanpassung des Modells an die Trainingsdaten am Lernen unbekannter Daten scheitern.
Methoden Maschinelles Lernen
- Regressionsverfahren: Linear Regression, Random Forest Regression, Gradient Boosting Regression
- Klassifikationsverfahren: Logistische Regression, k-Nearest Neighbour, Support Vector Machines
- Clustering: k-Means Clustering, DBSCAN
Anwendungsmöglichkeiten Machine Learning
- Empfehlungssysteme
- Betrugserkennung
- medizinische Diagnose
- Spam-Erkennung
- Gesichtserkennung
- Finanzprognosen
M wie: Microsoft Fabric
Microsoft Fabric ist eine End-to-End Datenplattform für Datenintegration, Data Engineering, Data Science, Data Warehousing, Echtzeitanalysen und Business Intelligence. Somit bietet Microsoft Fabric eine All-in-One Lösung zur Erfassung, Verarbeitung, Speicherung und Analyse von Daten in einer einheitlichen Umgebung.
OneLake
Die Basis für die Software-as-a-Service-Plattform (SaaS) in der Azure Cloud bildet der OneLake. OneLake ist die Lake-basierte Architektur, welche ähnlich wie OneDrive als zentraler Datenspeicher fungiert. Durch die Verbindung verschiedener Speicherstandorte zu einem einzigen Lake, müssen die Daten nicht mehr zwischen unterschiedlichen Systemen verschoben oder kopiert werden. OneLake basiert auf Azure Data Lake Storage (ADLS), sodass Daten in jedem Dateiformat gespeichert werden können. Für Tabellendaten wird dabei das Delta-Parquet-Format genutzt.
Komponenten von Fabric
Durch die Integration verschiedener Azure Dienste bietet Fabric eine umfassende Plattform zur Datenanalyse. Dazu gehören die Azure Data Factory zur Datenintegration, Power BI zur Datenanalyse und Azure Synapse für Data Warehousing, Datentransformationen mit Spark, Data Science mit Azure Machine Learning sowie Echtzeitanalysen von großen Datenmengen.

Data Governance
Durch die zentrale Speicherung im OneLake können Governance- und Sicherheitsrichtlinien für alle Komponenten einfach erstellt und kontrolliert werden. Im Admin Center können Nutzergruppen und Berechtigungen verwaltet, Datenquellen und Gateways konfiguriert sowie die Nutzung und Leistung überwacht werden. Zudem verwendet Fabric die Vertraulichkeitsbezeichnungen von Microsoft Purview Information Protection zum Klassifizieren und Schutz vertraulicher Daten.
M wie: MicroStrategy
Einführung MicroStrategy
MicroStrategy ist eine leistungsstarke Business Intelligence (BI)-Plattform, die Unternehmen bei der Analyse und Visualisierung ihrer Daten unterstützt, um fundierte Geschäftsentscheidungen zu treffen. Insgesamt bietet MicroStrategy eine umfassende Lösung für Unternehmen, die Daten in wertvolle Informationen verwandeln möchten, um strategische Entscheidungen zu treffen und ihre Leistung zu verbessern. Es ist eine wertvolle Ressource für das Datenmanagement und die Business Intelligence.
Hier sind einige wichtige Aspekte und Funktionen von MicroStrategy.
Berichterstellung und Visualisierung
MicroStrategy ermöglicht es Benutzern, Berichte und Dashboards zu erstellen, die Daten aus verschiedenen Quellen kombinieren und in leicht verständlichen Grafiken, Diagrammen und Tabellen darstellen. Diese visuellen Elemente helfen Benutzern dabei, Muster, Trends und Erkenntnisse aus den Daten zu gewinnen.
Datenaufbereitung
Das BI-Tool bietet umfangreiche Datenaufbereitungsfunktionen, mit denen Daten gereinigt, transformiert und modelliert werden können. Dies erleichtert die Integration von Daten aus unterschiedlichen Quellen und deren Anpassung an die spezifischen Anforderungen des Unternehmens.
Self-Service-Analyse
MicroStrategy ermöglicht es nicht nur IT-Experten, sondern auch Geschäftsanwendern, Analysen durchzuführen. Benutzer können Daten eigenständig abfragen und visualisieren, ohne auf umfangreiche IT-Unterstützung angewiesen zu sein.
Mobile BI
Die Plattform bietet mobile Anwendungen, mit denen Benutzer von ihren Mobilgeräten aus auf Echtzeitdaten und Berichte zugreifen können. Dies erleichtert die Entscheidungsfindung, auch wenn man unterwegs ist.
Skalierbarkeit und Sicherheit
MicroStrategy ist sowohl für kleine Unternehmen als auch für große Konzerne geeignet. Es bietet Skalierbarkeit und leistungsstarke Sicherheitsfunktionen, um die Vertraulichkeit und Integrität der Daten zu gewährleisten.
Integration
Die Plattform lässt sich nahtlos in bestehende IT-Infrastrukturen integrieren und kann Daten aus einer Vielzahl von Quellen, einschließlich relationalen Datenbanken, Big Data-Systemen und Cloud-Diensten, abrufen.
In-Memory-Verarbeitung
MicroStrategy verwendet In-Memory-Technologie, um Daten für schnelle Abfragen und Analysen im Arbeitsspeicher zu halten. Dies führt zu beschleunigten Berichterstellungs- und Analyseprozessen.
Predictive Analytics
Neben der reinen Datenvisualisierung bietet MicroStrategy auch Predictive Analytics-Funktionen, die Vorhersagen und Empfehlungen basierend auf historischen Daten treffen können.
Berichtsautomatisierung
Es ermöglicht die Automatisierung von Berichts- und Benachrichtigungsprozessen, um Benutzern regelmäßig aktualisierte Informationen zuzusenden.
Cloud- und On-Premises-Optionen
MicroStrategy kann sowohl in der Cloud als auch lokal installiert werden, um den individuellen Anforderungen und Präferenzen von Unternehmen gerecht zu werden.
M wie: MongoDB
Einführung MongoDB
MongoDB ist eine dokumentenorientierte NoSQL-Datenbank, die in vielen Anwendungsfällen weit verbreitet ist, darunter Webanwendungen, Mobile Apps, Echtzeit-Analytik, IoT und Content-Management-Systeme. Es bietet Entwicklern die Flexibilität und Leistung, um moderne Anwendungen zu erstellen, die große Datenmengen verarbeiten müssen.
Dokumentenorientiertes Datenmodell
MongoDB verwendet ein dokumentenorientiertes Datenmodell. Ein Dokument ist eine Sammlung von Feld-Wert-Paaren, ähnlich wie ein JSON-Objekt. Diese flexiblen und schemalosen Dokumente ermöglichen es Entwicklern, Daten auf natürliche und hierarchische Weise zu modellieren, ohne an ein starres Schema gebunden zu sein. So können Datenmodelle agil angepasst und erweitert werden, ohne das Schema oder die Anwendung zu ändern. Dies macht MongoDB besonders geeignet für agile Entwicklungsumgebungen, in denen sich Anforderungen häufig ändern.
Abfragemöglichkeiten MongoDB
MongoDB bietet zudem flexible Abfragemöglichkeiten. Es unterstützt ein Abfragesystem, das Indexierung, Filterung, Projektion, Sortierung und Aggregation ermöglicht. Die Abfragen werden mit einer intuitiven Abfragesprache namens MongoDB Query Language (MQL) formuliert, die leicht zu erlernen und zu verwenden ist.
M wie: MongoDB Compass
Einführung MongoDB Compass
MongoDB Compass ist ein grafisches Tool zur Verwaltung und Visualisierung von Daten in MongoDB-Datenbanken. Es bietet einen leistungsfähigen Abfrageeditor, mit dem Sie Abfragen in der MongoDB Query Language (MQL) erstellen und ausführen können.
![]()
Mit MongoDB Compass können Sie Datenbanken und Collections erstellen, umbenennen, löschen und verwalten. Sie können Indizes definieren und verwalten, um die Abfrageleistung zu optimieren, und Zugriffsrechte sowie Sicherheitseinstellungen konfigurieren.
Zudem bietet MongoDB Compass eine nahtlose Integration mit MongoDB Atlas und Azure CosmosDB.
Import & Export von Daten
MongoDB Compass ermöglicht es Ihnen, Daten aus verschiedenen Quellen in Ihre MongoDB-Datenbanken zu importieren. Sie können Daten aus JSON-, CSV- oder BSON-Dateien importieren oder aus anderen Datenbanken migrieren. Darüber hinaus können Sie Daten aus Ihrer MongoDB-Datenbank in verschiedene Formate exportieren, um sie in anderen Tools oder Anwendungen zu verwenden.
N wie:
N wie: Neuronales Netz
Einführung in neuronale Netze
Neuronale Netze bestehen aus mehreren Schichten von miteinander verbundenen Neuronen zur Simulation des menschlichen Gehirns. Im Gegensatz zu traditionellen Machine Learning Algorithmen, wie Linearer Regression, profitieren neuronale Netze durch die Vielzahl an Parametern von einer enormen Menge an Trainingsdaten. Neuronale Netze eignen sich beispielsweise zur Klassifikation von
- Bildern,
- Spracherkennung oder für
- personalisierte Produktempfehlungen.
Architektur neuronales Netz
Ein neuronales Netz setzt sich zusammen aus einer
- Input Layer,
- beliebig vielen Hidden Layers und
- einer Output Layer.
Die Input Layer definiert die Features des Modells und nimmt entsprechend die Input-Werte dieser Features entgegen. Daher enthält die Input Layer für jedes Feature genau ein Neuron. In den Hidden Layers finden die Berechnungen statt, um auf Basis der Input-Werte Vorhersagen zu treffen. Die Anzahl der Hidden Layers und die Anzahl der Neuronen in den einzelnen Hidden Layers sind beliebig und müssen vom Entwickler als Hyperparameter festgelegt bzw. optimiert werden. Die Output Layer liefert schließlich das Ergebnis des neuronalen Netzes, wobei die Anzahl der Neuronen in der Output Layer der Anzahl der zu prädiktierenden Werten entspricht.
Details zu lernen neuronaler Netze, Forwardpropagation, Backwordpropagation, Hyperparameter, Aktivierungsfunktion sowie Kostenfunktion findet ihr im Impuls Architektur und Funktionsweise von neuronalen Netzen.
N wie: NoSQL-Datenbanken
Definition No-SQL-Datenbanken
NoSQL (englisch für „Not only SQL“) bezeichnet Datenbanken mit einem nicht-relationalen Ansatz zur Speicherung von Daten in einem flexiblen Schema. Dadurch können sowohl strukturierte als auch unstrukturierte Daten effizient gespeichert und genutzt werden, ohne diese in ein bestimmtes Format zu transformieren.
Vorteile NoSQL gegenüber relationalen Datenbanksystemen
- Speicherung und Verarbeitung von unstrukturierten Daten
- Flexible Anpassung des Datenmodells
- Hohe Verfügbarkeit
- Nahezu unbegrenzte Skalierbarkeit
- Ausfalltoleranz
Arten von NoSQL-Datenbanken
- Dokumentenorientierte Datenbanken dienen zur Speicherung und Abrufung halbstrukturierter Daten. Dabei werden die Daten als Schlüssel-Wert-Paare in Form von Dokumenten im JSON-Format gespeichert. Diese Datenbanken bieten eine hohe Flexibilität, da nicht definiert werden muss, welche Felder ein Dokument enthalten soll.
- Beispiele: MongoDB, CouchDB und Riak
- Schlüsselwert-Datenbanken sind die flexibelsten NoSQL-Datenbanken. Die Daten werden in einer Hash-Tabelle gespeichert, in welcher jeder Schlüssel einzigartig ist. Der Wert zu einem Schlüssel kann alles Mögliche sein, zum Beispiel ein JSON-Objekt, eine Liste oder Datei, sodass Anwendungen beliebige Werte ohne Schema in einer Schlüsselwert-Datenbank speichern können.
- Beispiele: Redis und Dynamo
- Spaltenorientierte Datenbanken speichern Daten in Form von Tabellen mit Zeilen und Spalten und basieren auf dem BigTable-Modell von Google. Die Werte der Spalten werden dabei zusammenhängend gespeichert, sodass sich diese Art von NoSQL-Datenbanken besonders gut für Aggregationsabfragen eignet.
- Beispiele: Cassandra und HBase
- Graphenorientierte Datenbanken speichern Daten in Form von Knoten und Kanten, wobei die Kanten die Beziehungen zwischen den Knoten darstellen. Dies ermöglicht eine leichte Visualisierung von Netzwerkverbindungen. Diese Art von NoSQL-Datenbanken wird unter anderem für soziale Netzwerke und Logistik-Anwendungen eingesetzt.
- Beispiele: Neo4J und OrientDB
Anwendungsbereiche NoSQL-Datenbanken
NoSQL-Datenbanken eignen sich hervorragend für Anwendungen, welche große Datenmengen und geringe Latenzzeiten erfordern, wie zum Beispiel E-Commerce-Anwendungen. Auf der anderen Seite können NoSQL-Datenbanken keinen jederzeit konsistenten Zustand der Daten garantieren, sodass beispielsweise für Anwendung aus dem Finanzbereich relationale Datenbanksysteme zu bevorzugen sind.
P wie:
P wie: Palantir Foundry
Einführung Palantir
Foundry wurde neben Gotham und Apollo von Palantir Technologies entwickelt, einem amerikanischen Unternehmen, das sich auf Datenanalyse und -integration spezialisiert hat. Die Plattform wurde ursprünglich für Regierungsbehörden entwickelt, ist aber heute auch bei großen Unternehmen in verschiedenen Branchen wie Finanzen, Gesundheitswesen und Logistik im Einsatz.

Was ist Palantir Foundry?
Foundry ist eine leistungsstarke Datenplattform. Sie bietet Funktionen wie z.B.
- Datenintegration,
- Informationsmanagment und
- quantitative Analysen.
Mit Foundry können sie ihre Daten modellieren, analysieren und visualisieren, um wertvolle Erkenntnisse zu gewinnen und datengetriebene Entscheidungen zu treffen. Es unterstützt unter anderem auch die Integration von KI/ ML Modelle, um präzise Vorhersagen und komplexe Analyseprobleme zu lösen. Darüber hinaus hat Foundry die Fähigkeit zur Operationalisierung von Entscheidungen. Dieses ermöglicht das Modellieren von verschiedenen Szenarien und vergleichen von Optionen, bevor sie sich für eine Strategie entscheiden.
Trotz der Komplexität ist Foundry dennoch intuitiv und benutzerfreundlich gestaltet.
P wie: Plotly Dash
Einführung Plotly Dash
Plotly bietet mit ihrer eigens entwickelten Open-Source-Python-Bibliothek Dash eine Möglichkeit zur Erstellung interaktiver und webbasierter Dashboards. Was Dash genau ist, wie es funktioniert und wie ein konkreter Use-Case für die Erstellung eines interaktiven, webbasierten Dashboards aussehen kann wird in dieser Impulsreihe erläutert.
Was ist Dash?
Dash ist eine von Plotly entwickelte Open-Source-Python-Bibliothek die als Low-Code-Framework für die schnelle Erstellung von Datenanwendungen in Python, R, Julia, F# und MATLAB genutzt werden kann. Durch eine Reihe einfacher Muster abstrahiert Dash alle Technologien und Protokolle, die für die Erstellung einer vollständigen Webanwendung mit interaktiver Datenvisualisierung erforderlich sind. Die Dash App Galerie veranschaulicht, was alles mit Dash möglich ist.
Neben der freiverfügbaren, lokal-laufenden Open-Source-Version bietet Plotly zusätzlich mit Dash Enterprise eine kostenpflichtige Version an. Mit Dash Enterprise unterstützt Plotly die sichere interne Nutzung einer Dash-Anwendung mittels eines Deployment-Servers sowie weitere Services zur Wartung, Fehlerbehebung und multiplen Nutzung der Anwendung.
P wie: (Microsoft) Power Apps

Einführung Power Apps
Physische Ordner voller Dokumente, Datensilos mit unüberschaubaren Excel-Listen, versunkene E-Mails, in der Zeile verrutschte Einträge in Tabellen. Klingt nach Alltag? Hoffentlich nicht, denn genau das muss jetzt nicht mehr sein. Mit Microsoft Power Apps können Business Applikationen gebaut werden, die auf iOS, Android oder auf allen weiteren gängigen OS funktionieren – also ja, auch am Rechner.
Nutzen Power Apps
Wie in allen Power Platform Applikationen, ist es auch in Power Apps möglich, Projekte gemeinsam zu bearbeiten und zu teilen. Power Apps ermöglicht die Einbindung von KI-Elementen, darunter Spracherkennung oder die Erfassung von Daten aus Scans oder Fotos von wichtigen Dokumenten. Der Vorteil der Power Apps: Die Benutzung auf allen gängigen Geräten und Betriebssystemen. Zu Beginn der Entwicklung einer App wird das Format festgelegt, also ob eine Mobile App oder eine Desktop- bzw. Tablett App entwickelt werden soll. Auch gibt es Unterschiede in der Art der Applikation. Je nach Use-Case können drei verschiedene Applikationstypen erstellt werden.
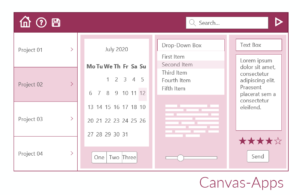
(1) Canvas-Apps stellen eine wie weiter oben bereits beschriebene „Fusion+“ aus Excel und PowerPoint dar. Durch Drag and Drop können, Formen, Tabellen, Eingabefelder und viele weitere nützliche Items auf einer weißen Fläche positioniert, mit ein wenig Code belebt und direkt einsatzfähig gemacht werden. Hierbei wird die User-Experience ins Zentrum gestellt, da das App Design vollkommen in der Hand des Entwicklers oder der Entwicklerin liegt. Die Datenanbindung kann über das Microsoft Dataverse, als auch über andere (Cloud)-Datenquellen erfolgen.
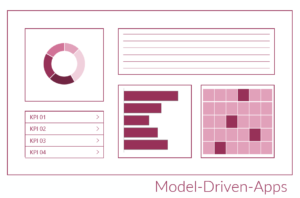
(2) Model-Driven-Apps bieten die Möglichkeit, ein datengetriebenes Modell als unterliegende Basis für die zu bauende Applikation zu erstellen. Anders als in der Canvas-App, werden bei Model-Driven-Apps relationale Datenbanken verwendet, die in Relation gesetzt werden – Power BI lässt grüßen. Das bedeutet, dass bei der Entwicklung einer solchen Applikation zunächst ein Datenmodell erstellt werden muss. Sobald dies geschehen ist, können Funktionen der App per Drag and Drop hinzugefügt und modifiziert werden. Hierbei ist kein Schreiben von Code notwendig. Und der Name ist Programm: Eine benutzerdefinierte optische Anpassung ist hierbei nicht im gleichen Rahmen wie bei Canvas-Apps möglich. Applikationen dieser Art stellen das Datenmodell (da die Apps eben um dieses aufgebaut werden) und die Features, die mit diesem ermöglicht werden in den Fokus – ganz nach der Devise „Form-Follows-Function“. Ein weiterer gravierender Unterschied liegt auf der Abhängigkeit zum Dataverse. Im Vergleich: Canvas-Apps können auch ohne Dataverse-Konnektoren entwickelt werden.
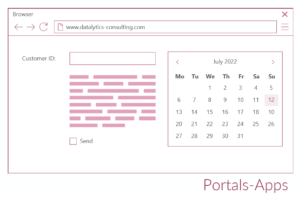
(3) Portal-Apps: Apps dieser Art, bieten die Möglichkeit mit externen Akteuren wie Kunden und Klienten über eine Webseite zu interagieren. Beispiele: Tickets ziehen, Anfragen stellen oder den Bearbeitungsstand einsehen. Durch Portal-Apps, also webbasierte Applikationen, können so auch außerhalb der eigenen Organisation, interne Daten angezeigt, hinzugefügt oder modifiziert werden. Wie bei den Model-Driven-Apps ist die Datenanbindung zum Dataverse erforderlich. Modifiziert wird die App per Drag and Drop, folglich ist die Entwicklung auch ohne Code möglich. Für individualisierte Features kommt man jedoch ohne ein wenig Code nicht herum.
Aufbau und Lizenzmodelle
Power Apps läuft über den Webbrowser. Entwickeln, Testen, Teilen, Löschen, Bearbeiten – die volle Funktionalität Power Apps ist Online aufzufinden. Das ist schön, aber wie steht es um das Thema Lizensierung? Jeder Nutzer benötigt eine Lizenz, um Apps zu entwickeln und zu konsumieren. Die Ausnahme bilden hier lediglich die Portal-Apps, welche auch von externen Usern ohne Lizenz genutzt werden können. Wichtig: Lediglich die Nutzung ist möglich, nicht die Entwicklung. Wie auch sonst, können je nach Use-Case hierbei unterschiedliche Lizenzmodelle in Frage kommen. Unterschieden wird zwischen Pro-App-Plänen und Pro-Benutzer-Plänen (bzw. subscription- und pay-as-you-go-plans).
Pro-App-Plan: Diese Lizenz ist für Nutzer geeignet, die nur wenige Apps entwickeln oder konsumieren. Pro Anwendung und Benutzer wird eine Lizenz verwendet. Wenn sich Anforderungen ändern, kann die Lizenz „aufgestapelt“ werden. Kostenpunkt: 4,20€/Benutzer/Monat.
Pay-as-you-go-Plan (Azure): Besitzt man ein Azure-Abonnement kann man den Pro-App-Plan mit einem Azure Abonnement „erweitern“ bzw. ersetzen. Genauer gesagt, zahlt man bei dieser Version nur bei der Erstellung oder dem Konsum von Apps (pro Monat und pro Benutzer). Für Organisationen mit schwankenden Anforderungen könnte diese Option am attraktivsten sein. Kostenpunkt: 8,43€/Benutzer/Monat + Nutzungskosten.
Pro-Benutzer-Plan: Bei dieser Lizenz können eine unbegrenzte Anzahl von Anwendungen und Portalen pro Benutzer zu einem monatlichen Pauschalpreis ausgeführt werden. Folglich ist dieser Plan oft in großen Organisationen vorzufinden. Kostenpunkt: 16,90€/Benutzer/Monat.

P wie: (Microsoft) Power Automate

Einführung Power Automate
Power Automate ist die dritte Einheit im Bunde der Microsoft Power Platform. Wie der Name bereits andeuten lässt, dient Power Automate der Automatisierung. Und zwar nicht weniger der von Geschäftsprozessen. Angenehme Überraschung: Der Begriff „Geschäftsprozess“ ist extrem weit gefächert. Das heißt, dass Power Automate in einer Vielzahl von verschiedenen Kontexten eingesetzt werden kann. Darunter finden sich Tasks wie die Erinnerungen an überfällige Aufgaben und die automatische Versendung von Nachrichten wieder, das Verschieben von Geschäftsdaten nach Zeitplan zwischen Systemen oder das Herstellen von Verbindungen zu mehr als 500 Datenquellen und allen öffentlich zugänglichen APIs. Es können sogar Flows erstellt werden, die automatisiert das Berechnen von lokalen Excel-Dateien durchführen. Also, die Möglichkeiten sind schier grenzenlos.
Doch wie funktioniert das Ganze nun? Die Antwort ist simpel – über sogenannte Trigger. Trigger werden über Events „getriggert“, sie fungieren somit als Auslöser. Trigger rufen nach Auslösung eine Aktion aus, zum Beispiel das Ablegen von Dokumenten aus einer Mail in einem bestimmten Ordner. Diese Aktionen können weitere Auslöser/Trigger triggern und so weiter und so fort. Betrachtet man diese Kette zeichnet sich ein „Event-Flow“ ab, daher lässt sich auch der ursprüngliche Name erahnen: Power Flows. Da inzwischen aber neben der Flows, wie eben erwähnt, noch viel mehr möglich ist, ist der Name Power Automate doch ein wenig passender.
Nutzen Power Automate
Power Automates Nutzen ist groß. Sehr groß. Mit einer riesigen Auswahl an Konnektoren (500+) stellt Microsoft Schnittstellen zu SAP, LinkedIn, Google Drive und vielen mehr. Dadurch ist Power Automate so vielfältig wie nur erdenklich einzusetzen. Power Automate kann also für jegliche Automatisierungen genutzt werden, um Tasks, die keine große kognitive Anstrengung erfordern „outsourcen“ zu können. Dabei wird Power Automate durch KI unterstützt, indem diese beispielsweise Informationen aus Rechnungen in PDF-Format extrahieren und direkt in Tabellen speichern oder Kommentare nach positiver oder negativer Gesinnung filtern und unterscheiden kann.
Jetzt mal im Detail. Es gibt fünf verschiedene Arten von Flows:
- Automatisierte Flows aka „Durch Ereignisse ausgelöste Flows“
- Geplante Flows aka „Zeitlich abgestimmte Flows“
- Direktflows aka „Manuell getriggerte Flows“
- Geschäftsprozessflows aka „Durchleiten eines mehrstufigen Prozesses“
- Benutzeroberflächenflows aka (RPA) Aufnehmen von Arbeitsschritten und diese anschließend abspielen lassen
Aufbau und Lizenzmodelle
Zwei Lizenzmodelle
Power Automate kommt mit sechs verschiedenen Lizenzmodellen auf den Markt. Diese lassen sich entweder den „Subscription plans“ oder den „Pay-as-you-go plans“ zuordnen. Subscription plans, also abonnementorientierte Pläne, bitten sie monatsweise zur Kasse, dafür erhalten Sie je nach Plan eine unbestimmte Anzahl an Flow-Ausführungen. Bei den Pay-as-you-go plans, wird lediglich die Ausführung eines Flows bepreist, dafür kein monatlicher Festbetrag.
Welches Lizenzmodell für wen?
Okay, soweit so gut. Doch für wen ist welches Lizenzmodell am besten geeignet? Diese Frage beantwortet Microsoft mit der Unterteilung der zwei Zahlungsmodelle. Organisationen, die eine fixe bzw. fest berechenbare Kostenstruktur präferieren können mit einem Subscription-Plan ihre Ziele am besten erreichen.
Andererseits sind Pay-as-you-go plans die Lösung für Organisationen, die Flexibilität präferieren und nur dann zahlen wollen, wenn sie einen Flow benutzen. Generell lässt sich aber sagen, dass in den meisten Fällen eine Mischung aus beiden Lizenztypen, die beste Lösung darstellt.
P wie: (Microsoft) Power BI
Einführung PBI
Datenbasierte empirische Entscheidungen sind von essenzieller Bedeutung für Handlungsmaßnahmen in einem Unternehmen. Ob technische Daten wie Ausfallraten bestimmter Maschinen oder Finanzdaten zur Bestimmung von Konsumententrends, eine Entscheidung auf Bauchgefühl ist nicht mehr zeitgemäß und riskiert maßgeblich den Erfolg eines Unternehmens. Um diese Brücke zu schließen, wird Reporting benötigt. Und hier kommt Microsofts Power BI ins Spiel:
Power BI ist studienbelegt, die führende interaktive self-service Reporting-Plattform, welche für Business- als auch Data Analytics genutzt wird. Grundsätzlich kann man Power BI als Tool beschreiben, welches dazu dient Daten schnell, effizient und vor allen Dingen, einfach zu Analysieren und zu Visualisieren. Allerdings richtet sich Power BI nicht nur an Entwickler, Analysten oder verwandte Rollen, sondern auch an Konsumenten der erstellten Dashboards und Reports. Ein großer Vorteil der Power BI Applikation ist somit neben der klassischen Offline-Version, die von Microsoft bereitgestellte Cloud-Plattform welche lokalisationsübergreifend/ortsübergreifend die Zusammenarbeit verschiedener Akteure einer oder sogar unterschiedlicher Organisationen vereinfacht. Power BIs Handlungsraum spielt sich in einem breiten Spektrum von Daten ab. Angefangen bei kleinen Excel-Files bis hin zu Big Data wird die Applikation als Datenverarbeitungstool in einer Reihe von Unternehmen und Industrien eingesetzt.
Nutzen Power BI
Der Nutzen Power BIs lässt sich anhand einiger ausgewählter Punkte darstellen.
- Microsofttypisch bietet Power BI eine Vielzahl von (1) Schnittstellen zu diversen Datenquellen. Excel, SQL-Datenbanken, Cloudquellen, APIs und SharePoint-Listen sind nur ein kleiner Ausschnitt aus welchem Power BI Daten beziehen kann.
- (2) Datensäuberung und Datentransformation nehmen in der Datenanalyse eine zentrale Rolle ein. Eben dieser Punkt wird auf Basis der Programmiersprache Power Query M durch ein intuitives Userinterface vereinfacht, indem Spalten und Reihen von Datensätzen schnell modifiziert werden können, ohne tatsächlich programmieren zu müssen. Selbstverständlich können fortgeschrittenere User:innen dennoch auf Power Query M zurück greifen.
- Darauf aufbauend, können in Power BI Datensätze durch (3) Datenmodellierung in Relationen gesetzt, und anschließend optimiert werden. Der hervorstechendste Punkt hierbei ist DAX. DAX steht für Data Analysis & Expression und ist in der einfachsten Form lediglich eine Sammlung von Funktionen, Operatoren und Konstanten die durch bestimmte Ausdrücke/Formeln Werte berechnen oder zurückgeben kann. Vereinfacht gesagt: DAX hilft neue Informationen aus sich bereits im Modell befindenden Daten zu generieren.
- Letztlich kann ein fertiger Report, der zur Veröffentlichung bereitsteht, durch (4) Power BI Service in Microsoft Teams, Webseiten oder schlichtweg als alleinstehender Report publiziert, und von berechtigten Akteuren konsumiert werden.
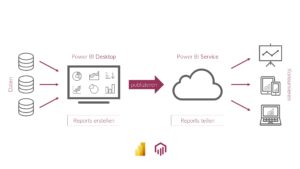
Lizenz- und Kostenmodelle
Power BI ist nicht gleich Power BI. Es gibt im Wesentlichen zwei „Versionen“ von Power BI: Desktop und Service. Der Unterschied zwischen den beiden Applikationen liegt im Use-Case. Während PB Desktop darauf ausgelegt ist, Reports zu bauen, komplexe Datenmodelle aus diversen Datenquellen zu erstellen und weitere datenintensive Operationen durchzuführen, ist Power BI Service mehr auf den Konsum und die Verteilung der Reports ausgelegt. Dashboards bauen, Workspaces erstellen und teilen oder paginierte Reports exportieren, all das sind exklusive Service Features. Dennoch gibt es auch einige Gemeinsamkeiten zwischen den beiden Versionen. Grundsätzlich können beide Versionen Reports erstellen und sich Visuals und Filter zu eigen machen. Kurz um: Desktop ist für die Entwicklung gedacht, Service für den Konsum. Weitere Unterschiede und Gemeinsamkeiten erläutert die Abbildung.
Welches Lizenzmodell für Ihre Organisation am effizientesten ist, kann mit unserer kompetenten Beratung erörtert werden – vereinbaren Sie dazu einfach einen kostenlosen und unverbindlichen Termin.

P wie: Power BI Performance Analyzer
Mithilfe des „Performance Analyzer“ in Power BI Desktop kann die Leistung für jedes Berichtselemente bei der Benutzerinteraktion gemessen werden, um festzustellen, welche Aspekte die meisten (oder wenigsten) Ressourcen verbrauchen. So können Engpässe im Power BI Bericht erkannt und die generelle Berichtsleistung verbessert werden. Folgendes ermöglicht der Performance Analyzer:
- Ladezeit-Analyse: Der Performance Analyzer ermöglicht es, die Ladezeit von Daten und Visualisierungen in einem Bericht zu überwachen. Dadurch können Engpässe und langsame Bereiche identifiziert werden.
- Detaillierte Zeitmessungen: Es erfasst detaillierte Zeitmessungen für jede Datenquelle, Abfrage und Visualisierung im Bericht. Dies hilft dabei, den Datenfluss und die Verarbeitungszeit genau zu verstehen.
- Visualisierungs-Performance: Der Analyzer ermöglicht es, die Leistung einzelner Visualisierungen zu überprüfen. Dies ist besonders nützlich, um festzustellen, welche Teile des Berichts optimiert werden müssen.
- Filterleistung: Es bietet Einblicke in die Leistung von Filtern und Slicern, damit man verstehen kann, wie sie sich auf die Abfrage- und Anzeigezeit auswirken.
- Analyse von DAX-Ausdrücken: Der Performance Analyzer kann auch die Leistung von DAX-Ausdrücken und -Formeln im Bericht bewerten, um Engpässe zu identifizieren und zu optimieren.
- Export von Messungen: Es ermöglicht das Exportieren von Leistungsmessungen, um sie extern zu analysieren oder mit anderen zu teilen.
- Echtzeitüberwachung: Der Performance Analyzer ermöglicht eine Echtzeitüberwachung der Leistung während der Interaktion mit dem Bericht.
P wie: (Microsoft) Power Virtual Agents

Einführung Power Virtual Agents
Kundenservice. Was kommt bei diesem Wort zuerst in Ihre Gedanken? Lange Warteschleifen und Telefonate? Genervte Mitarbeiter, genervte Kunden, unzureichende Ergebnisse? Okay, vielleicht nicht ganz so schlimm. Inzwischen gibt es ja auch die Möglichkeit, ihre Organisation über Chat zu erreichen. Aber eben nur zwischen 9 Uhr und 12 Uhr. Die Mitarbeiter müssen schließlich auch mal in die Pause. Und nur auf Anfragen zu warten, das würde einfach zu viel potentielle Arbeitskraft und Geld kosten.
Naja, also doch zurück zum Telefon?
Nein. Natürlich nicht. Inzwischen gibt es Chat Bots. Intelligente Chat Bots. Chat Bots, die kaum vom Menschen unterschieden werden können und mit ihrer 24 Stunden Verfügbarkeit, ihrer Geschwindigkeit und Akkuratheit glänzen.
Und man hätte es kaum ahnen können, Microsoft macht wie immer kurzen Prozess und kommt mit einer Lösung auf den Markt die es in sich hat. Wir stellen vor: Microsoft Power Virtual Agents.
Nutzen Virtual Agents
So weit so gut. Was PVA ist, ist jetzt klar. Doch welchen Nutzen birgt das einfach zu bedienende KI-Tool? Die Kurzform: es spart Ressourcen. Die einfache Bedienung, die auch von Nicht-Experten schnell und einfach angeeignet werden kann, schließt den Graben zwischen IT- und Domainexperten. Dadurch wird viel Zeit in der Entwicklung gespart- und somit auch Geld. Wartung und Bereitstellungszeiten werden verkürzt und somit kommen Anwender schneller zum Ziel.
Der Nutzen von PVA spiegelt sich neben den Bots selbst in der einfachen Handhabung wider. Das zeigt sich bereits bei der unkomplizierten und schnellen Integrierung eines Bots in Ihre Website, oder sogar bei internen Angelegenheiten in Ihr Microsoft Teams. Hier werden weder externe Tools noch jegliche andere komplexe Systeme herangezogen.
Zudem können nun Domainexperten ohne die Zusammenarbeit mit IT-Experten ihre eigenen Lösungen bauen und so den Graben zwischen fachlicher und technischer Expertise schließen.
Durch die Fähigkeit der Bots, sich bei so gut wie jeder Frage helfen zu wissen, entstehen natürlich klingende Konversationen mit vielschichtigen Konversationsverläufen. Die ist wie zuvor bereits beschrieben auf die von Microsoft vortrainierten Modelle zurückzuführen. „Trainiert“ werden die Bots, in dem sie ihnen einfach einige Wörter nennen, die im Zusammenhang mit ihrer Frage stehen et voilà, das Modell steht.
Lizenz- und Kostenmodelle
Der Kostenplan von PVA ist ziemlich simpel. Hierbei ist lediglich wichtig zu wissen, dass PVAs Kostenmodell über sogenannte Sitzungen läuft. Eine Sitzung kann quasi als beantwortete Anfrage eines Fragenstellers oder einer Fragestellerin gesehen werden. Grundsätzlich beginnt eine Sitzung, sobald ein Thema ausgelöst, sprich eine Konversation zielführend und themaorientiert startet, aber auch wieder terminiert wird. Terminiert wird eine Sitzung entweder durch das Beantworten der Frage durch den Bot, eine Zeitüberschreitung des Gesprächs von 60 Minuten oder dem Überschreiten von 100 Wortwechseln.
Und jetzt Tacheles: Stand November 2022 kostet PVA in seiner Grundform 168,70€ pro Monat. Inbegriffen sind hierbei 2000 Sitzungen. Weitere Sitzungen können über sogenannte „Sitzungs-Add-On(s)“ bereitgestellt werden. Der Kostenpunkt liegt bei 84,40€ pro Monat für weitere 1000 Sitzungen.
Fassen wir also nochmal zusammen. PVA ist ein kostengünstiges SaaS-Angebot von Microsoft, das schnell und intuitiv entwickelt, implementiert und gepflegt werden kann. PVA kann sich mit Kunden, Mitarbeitern oder sonstigen Akteuren zielführend unterhalten und in Kombination mit Microsoft Power Automate auch eigenständig handeln.
Q wie:
Q wie: Qlik Sense

Visualisierungen und Dashboards
Die einzigartige assoziative Technologie von Qlik ermöglicht branchenführende Analysen mit unübertroffener Leistung. Mit Qlik Sense können alle Benutzer Daten uneingeschränkt untersuchen, indem sie blitzschnelle Berechnungen durchführen, den jeweiligen Kontext berücksichtigen und beliebig skalieren. Dies ist ein einzigartiges Merkmal, das die Grenzen von abfragebasierten Analysen und Dashboards anderer Mitbewerber von Qlik weit hinter sich lässt.
Anwendungsfälle
- Self-Service Visualisierungen
- Interaktive Dashboards
- Such- un ddialogorientiert
- Alerting und Maßnahmen
- Reporting
- Maßgeschneidert und eingebettet
- Erweiterte Analysen
Leistungsfähige AI
Dank der integrierten AI-Technologie von Qlik Sense können Anwender Daten schneller und effizienter verstehen und nutzen, wodurch die kognitiven Verzerrungen vermieden werden, die menschliche Entscheidungen beeinflussen können. Mit Qlik Sense können Sie Ihre Datenkompetenz erweitern und die Auswertung und Untersuchung von Daten optimieren. Darüber hinaus bietet Qlik Sense umfangreiche Funktionen für Augmented Analytics:
- AI-basierte Analysen und Erkenntnisse
- Automatisiertes Daten-Scraping und -Aufbereitung
- Natürlichsprachliche Suche und Interaktion
- Machine Learning und Predictive Analytics
Aktive Analysen
Unternehmen müssen heutzutage schnell auf sich ändernde Informationen reagieren können, um im Wettbewerb zu bestehen. Herkömmliche Business Intelligence-Systeme, die nur statische Berichte und Dashboards bereitstellen, sind dazu oft nicht in der Lage. Qlik bietet eine Lösung, die eine Echtzeit-Datenpipeline mit handlungsorientierten Analysefunktionen kombiniert, um Active Intelligence zu schaffen. Damit erhalten Sie stets aktuelle Ergebnisse und können sofortige Maßnahmen ergreifen.
Das intelligente Alerting-System informiert Sie über Veränderungen in Ihren Daten, die Ihre Aufmerksamkeit erfordern. Durch leistungsfähige Funktionen zur Zusammenarbeit können Sie Ihre Erkenntnisse schnell und einfach mit anderen teilen und Entscheidungen gemeinsam treffen. Mit mobilen Anwendungen können Sie von überall aus auf Ihre Daten zugreifen und mit ihnen interagieren. Außerdem können automatisch angestoßene Aktionen Ihnen helfen, schneller auf Veränderungen in Ihren Daten zu reagieren und schneller Entscheidungen zu treffen.
Hybrid-Cloud-Plattform
Sichern Sie sich überzeugende Leistung und Flexibilität mit Qlik Sense auf Qlik Cloud®. Implementieren Sie eine komplette SaaS-Unternehmenslösung oder nutzen Sie die Bereitstellungsoptionen für Hybrid Clouds, um Analysen überall dort zu ermöglichen, wo sich Ihre Daten befinden.
Mit Qlik Sense auf Qlik Cloud® haben Sie die volle Kontrolle über Ihre Daten und Analysen. Unsere Plattform unterstützt jede Kombination von Public Cloud, Private Cloud und On-Premises-Standorten, um Ihnen maximale Flexibilität zu bieten. So können Sie Ihre Daten und Analysen jederzeit und überall dort nutzen, wo es für Ihr Unternehmen am besten passt. Und das alles mit der Leistung und Zuverlässigkeit, die Sie von Qlik gewohnt sind.
S wie:
S wie: SAP Analytics Cloud

SAP Analytics Cloud (SAC) ist eine cloudbasierte Plattform, die speziell für Datenanalyse, Planung und Vorhersage entwickelt wurde. SAC wurde 2015 von SAP eingeführt, und sie wurde in den letzten Jahren kontinuierlich weiterentwickelt.
SAC ist neben Power BI, Tableau oder Qlik eines der wichtigsten Tools im Bereich Business Intelligence. Die Entscheidung zwischen diesen Tools hängt von den Bedürfnissen des jeweiligen Unternehmens, seiner bestehenden Architektur, seiner Strategie und seinen Ressourcen ab.
Was ist die SAC?
SAP Analytics Cloud ermöglicht es Unternehmen, ihre Daten zu importieren, zu modellieren und zu visualisieren, alles innerhalb einer benutzerfreundlichen, cloudbasierten Umgebung. Es integriert Funktionen wie Natural Language Processing (NLP) für intuitive Interaktion mit Daten und maschinelles Lernen für fortschrittliche Analysen.

Wofür wird SAP Analytics Cloud verwendet?
Dieses Tool wird verwendet, um datengesteuerte Entscheidungen zu fördern. Unternehmen nutzen SAP Analytics Cloud, um Daten aus verschiedenen Quellen zu kombinieren, umfassende Analysen durchzuführen und strategische Planungen vorzunehmen. Es dient als zentrale Plattform, um Teams bei der Zusammenarbeit, Kommunikation und dem Teilen von Erkenntnissen zu unterstützen.
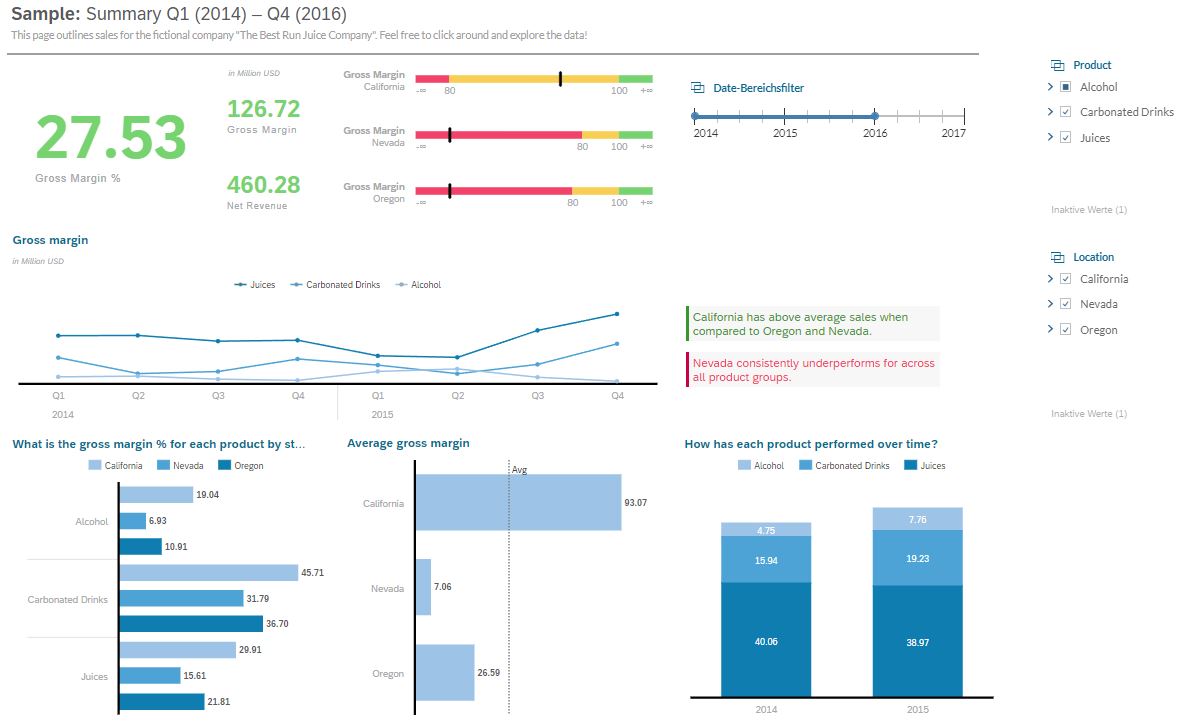
Highlights des Tools
- Intuitive Benutzeroberfläche: Die Plattform bietet eine intuitive Benutzeroberfläche, die Benutzern ermöglicht, Daten auf einfache und ansprechende Weise zu analysieren.
- Advanced Analytics: Mit Funktionen wie maschinellem Lernen und Predictive Analytics können Unternehmen tiefe Einblicke in ihre Daten gewinnen und fundierte Prognosen treffen.
- Collaboration-Tools: SAP Analytics Cloud fördert die Zusammenarbeit im Team durch Funktionen wie Diskussionen, Kommentare und gemeinsame Planung.
- Cloudbasierte Flexibilität: Als cloudbasierte Lösung bietet SAP Analytics Cloud die Flexibilität, von überall auf Daten zuzugreifen und Analysen durchzuführen.
S wie: Self-Service BI
Einführung
Damit Sie und Ihre Mitarbeiter auch selbstständig Analysen sowie Visualisierungen von Daten vornehmen können, helfen wir bei der Einführung der Software, bieten Schulungen in den eingeführten Business Intelligence Tools an und sind bei Support-Anfragen jederzeit für Sie da.
Inhalte:
- Schulung
- Softwareeinführung
- Wissenstransfer & Support
- BI-Community
S wie: Spark
Apache Spark ist ein Open Source-Framework für die parallele Verarbeitung großer Datenmengen und Analysen. Spark bietet eine leistungsstarke, verteilte Datenverarbeitungsumgebung für große Datensätze und komplexe Rechenoperationen. Spark unterstützt verschiedene Programmiersprachen, wie Java, Scala, Spark R, Spark SQL und PySpark (eine Spark-spezifische Variante von Python). Zudem ist Spark auf mehreren Plattformen verfügbar, darunter Databricks, Azure Synapse Analytics und Microsoft Fabric.
Resilient Distributed Datasets
Die fundamentale Datenstruktur in Spark sind Resilient Distributed Datasets (RDDs). Sie sind verteilte, unveränderliche Datensätze, die über ein Cluster von Computern hinweg parallel verarbeitet werden können. RDDs ermöglichen es Spark, Daten effizient zu speichern und zu verarbeiten.
Vorteile von Apache Spark
- Apache Spark bietet eine breite Palette von Datenverarbeitungsmöglichkeiten, einschließlich Batch-Verarbeitung, Streaming Operationen, interaktiven Abfragen und maschinellem Lernen.
- Spark setzt stark auf In-Memory-Computing, was bedeutet, dass Daten im Arbeitsspeicher gehalten werden, um schnelleren Zugriff und schnellere Verarbeitung zu ermöglichen. Dies verbessert die Leistung im Vergleich zu traditionellen Systemen, bei denen Daten von der Festplatte geladen werden.
- Spark unterstützt die Erstellung komplexer Datenpipelines, bei denen mehrere aufeinanderfolgende Datenverarbeitungsschritte miteinander verbunden werden. Dies erleichtert die Entwicklung von Dataflows und ermöglicht eine effiziente Verarbeitung großer Datenmengen.
- Spark kann in verschiedenen Programmiersprachen verwendet werden, darunter Scala, Java, Python und R. Spark SQL ermöglicht zudem die Verarbeitung strukturierter Daten mithilfe einer SQL-Schnittstelle. Dies erleichtert die Integration von Spark in bestehende SQL-basierte Datenanalysesysteme.
- Spark enthält eine Bibliothek für maschinelles Lernen, die als MLlib bekannt ist. Diese Bibliothek bietet Implementierungen verschiedener maschineller Lernalgorithmen und Tools für die Modellentwicklung.
- Spark enthält auch eine Bibliothek namens GraphX, welche die Analyse von Graphen basierten Daten ermöglicht.
T wie:
T wie: Tableau
Einführung Tableau
Die neuste Lösung von Tableau heißt Tableau Cloud und ersetzt Tableau Online. Es handelt sich um eine vollständig gehostete Cloud-basierte Plattform, die auf einer der weltweit führenden Analytics-Plattformen läuft und für Unternehmen geeignet ist. Mit Tableau Cloud können Sie Daten schnell, flexibel und benutzerfreundlich bearbeiten und analysieren sowie Entscheidungen an jedem beliebigen Ort schneller und zuverlässiger treffen. Die Plattform ist anpassungsfähig an die Unternehmensarchitektur und fördert die Zusammenarbeit.
Anwendungen von Tableau Cloud
Schnelle und intelligente Entscheidungen
Schaffen Sie eine sichere Grundlage für Ihre Entscheidungsfindung und nutzen Sie das volle Potenzial Ihrer Daten mit intelligenten Analysewerkzeugen wie Datenstorys, Frag die Daten und Erklär die Daten. Sie sparen Zeit und vereinfachen Analytics für alle, indem Sie automatisch erstellte und leicht verständliche Erzählungen – Datenstorys – zu Ihren Dashboards hinzufügen. Durch die Nutzung von Frag die Daten können Sie in natürlicher Sprache Antworten auf zentrale geschäftliche Fragen finden und mit Erklär die Daten das „Warum“ hinter KI-gestützten Erkenntnissen erkunden und vertiefen. Mit Tableau Blueprint können Sie Ihre Datenstrategie strukturieren und ein datengesteuertes Unternehmen aufbauen.
Einbindung von Datenerkenntnissen direkt in den Workflow
Wenden Sie Erkenntnisse direkt in Ihrem Workflow an, indem Sie Tableau für Slack nutzen. Diese digitale Analytics-Zentrale ermöglicht es Ihnen, Daten in jedes Gespräch einzubinden und überall datengesteuerte Erkenntnisse zu gewinnen. Mithilfe von eingebetteten Analytics können Daten und Erkenntnisse nahtlos in Ihre Produkte und Anwendungen integriert werden, um Benutzer und Kunden mit datengesteuerten Erkenntnissen zu unterstützen. Beschleuniger, Connectoren, Erweiterungen und mehr bieten Ihnen Einstiegsangebote in die Analyse.
Skalierung mit benutzerfreundlicher Analytics
Integrieren Sie Analytics nahtlos in Ihre Unternehmensarchitektur und treiben Sie die digitale Transformation voran. Durch die Nutzung von Tableau Cloud müssen Sie keine Server konfigurieren, keine Software-Upgrades verwalten und keine Hardwarekapazitäten skalieren. Dadurch sparen Sie Zeit und Geld. Fördern Sie Teamarbeit, indem Sie Daten ermitteln, teilen und erkunden und die Zusammenarbeit auf dieser Basis mit Ihrem Mobilgerät, Tablet oder Computer in Tableau Cloud fördern. Erstellen und skalieren Sie erfolgsentscheidende Analytics einfach und behalten Sie mit der bald verfügbaren erweiterten Verwaltung die Kontrolle über Tableau Cloud. Die erweiterte Verwaltung bietet unbegrenzte Skalierbarkeit, optimale Effizienz und einfach handhabbare Sicherheitsfunktionen.
Vertrauen durch Data Governance
Sorgen Sie für zentrale Governance, Transparenz und Kontrolle, um sicherzustellen, dass Ihre Daten nur für autorisierte Benutzer verfügbar sind. Mit automatischer Authentifizierung und einem Berechtigungsmanagement wird die Sicherheit Ihrer Daten in Tableau Cloud gewährleistet. Sie können Tableau Cloud einfach mit Single Sign-On (SSO) oder Ihrem Identitätsanbieter integrieren und die Nutzung in nur einer Umgebung überwachen, um die Compliance sicherzustellen. Tableau Cloud bietet eine moderne Infrastruktur, die branchenführende Sicherheits- und Zertifizierungsstandards wie SOCII und ISO erfüllt. Das in die Plattform integrierte Data Management ermöglicht eine einfache und reproduzierbare Skalierung von vertrauenswürdigen Daten.
T wie: TensorFlow
TensorFlow ist ein Open-Source Python-Framework zum maschinellen Lernen. Die Plattform wurde von Google entwickelt, um die Entwicklung, das Training und den Einsatz von Machine Learning Modellen und neuronalen Netzen zu erleichtern. TensorFlow kann zur Entwicklung tiefer neuronaler Netze in den Bereichen Computer Vision, Natural Language Processing oder Time Series Forecasting eingesetzt werden. So eignet sich TensorFlow beispielsweise zur Bildung von Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) oder Long Short-Term Memory (LSTMs).
Den Grundbaustein stellen dabei Tensoren dar, welche als multidimensionale Arrays zur Repräsentation von Daten in maschinellen Lernalgorithmen verwendet werden. Sie können Skalare, Vektoren oder Matrizen beliebiger Größe umfassen. Zum Training von Deep Learning Modellen unterstützt TensorFlow die Verteilung und Skalierung von Berechnungen auf mehreren Rechenknoten, um große Datenmengen mit einer hohen Rechenleistung zu verarbeiten. Die Ausführung von TensorFlow-Anwendungen ist auf verschiedenen Plattformen und Geräten, einschließlich CPUs, GPUs, TPU-Chips, Servern, mobilen Geräten und IoT-Geräten sowohl lokal als auch in der Cloud möglich. TensorFlow kann auch in Kombination mit anderen Frameworks zum maschinellen Lernen und zur Datenverarbeitung, wie Scikit-learn oder Apache Spark, genutzt werden. Zudem ist die Deep-Learning-Bibliothek Keras in TensorFlow integriert und ermöglicht eine benutzerfreundliche und leistungsstarke Entwicklung von Deep Learning Modellen.
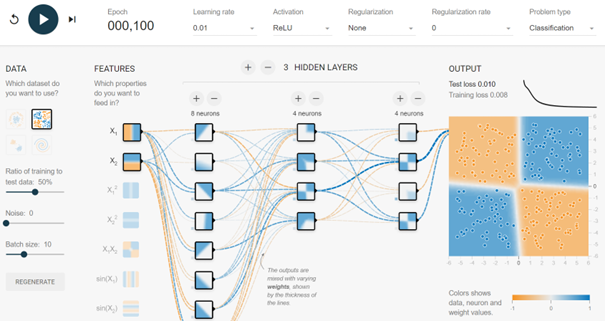
T wie: Terraform
Terraform ist ein Infrastructure-as-Code Tool zur Verwaltung von Cloud-Infrastruktur. Mithilfe der deklarativen Konfigurationssprache HCL (HashiCorp Configuration Language) können die einzelnen Komponenten einer Cloud-Infrastruktur definiert und bereitgestellt werden. Die Definition der Infrastruktur in Terraform-Konfigurationsdateien macht diese reproduzierbar, da die Konfigurationsdateien im Gegensatz zu Klicks in einer Cloud-Umgebung jederzeit neu ausgeführt und wie der Quellcode eines Softwareprogramms verwaltet werden können. Diese Dateien beschreiben dabei, welche Ressourcen erstellt werden sollen und wie sie miteinander verbunden sind.
Terraform unterstützt eine Vielzahl von Cloud-Providern (z. B. AWS, Azure, Google Cloud), Datenzentren (z. B. VMware, OpenStack) und Diensten (z. B. Docker, Kubernetes). Jeder Provider ermöglicht die Definition von Ressourcen in der jeweiligen Umgebung. Mit Terraform können auch Ressourcen über verschiedene Cloud-Plattformen hinweg verwaltet und sogar hybride Umgebungen erstellt werden, die lokale und Cloud-Ressourcen kombinieren.
U wie:
U wie: Unity Catalog
Einführung Unity Catalog
Unity Catalog bietet eine einheitliche Governance-Lösung für Daten und KI-Ressourcen in Databricks. Dazu gehören zentralisierte Funktionen zur Zugriffssteuerung, Überwachung und Herkunftsermittlung von Daten in Databricks Umgebungen.
Objektmodell von Unity Catalog
Die Hierarchie der Datenobjekte im Unity Catalog besteht aus vier Schichten:
- Der Metastore ist ein Container mit Metadaten über Objektressourcen und Berechtigungen, die den Zugriff auf diese Ressourcen steuern. Die Datenobjekte eines Metastores können über den 3-leveligen Namespace (catalog.schema.table) angesprochen werden.
- Ein Katalog ist die erste der drei Ebenen im Namespace von Unity Catalog und dient zur Organisation der Datenressourcen.
- Ein Schema, welches auch als Datenbank bezeichnet wird, eignet sich zur Verwaltung von Tabellen und Sichten.
- Auf der untersten Ebene der Objekthierarchie befinden sich Tabellen, Sichten und Funktionen.
Vorteile von Unity Catalog
- Mit Unity Catalog können die Datenzugriffsrichtlinien zentral definiert werden, sodass diese für alle Arbeitsbereiche gelten.
- Unity Catalog bietet eine Schnittstelle zur Suche nach Datenobjekten. Zudem können Datenressourcen markiert und dokumentiert werden.
- Unity Catalog erfasst Herkunftsdaten, um nachzuverfolgen, wie Datenressourcen erstellt und verwendet werden.
- Unity Catalog funktioniert mit vorhandenen Datenkatalogen, Datenspeichersystemen und Governance-Lösungen, sodass keine hohen Migrationskosten nötig sind.