
Serie | Data Integration (Migration & ETL) – Einführung & Anwendungsbeispiele in Microsoft Fabric
Microsoft Fabric ist eine End-to-End Datenplattform für Datenintegration, Data Engineering, Data Science, Data Warehousing, Echtzeitanalysen und Business Intelligence. Somit bietet Microsoft Fabric eine All-in-One Lösung zur Erfassung, Verarbeitung, Speicherung und Analyse von Daten in einer einheitlichen Umgebung.
Komponenten von Fabric – ADF, Power BI, Synapse & Data Activator
Die Basis für die Software-as-a-Service-Plattform (SaaS) in der Azure Cloud bildet der OneLake. OneLake ist die Lake-basierte Architektur, welche ähnlich wie OneDrive als zentraler Datenspeicher fungiert. Durch die Verbindung verschiedener Speicherstandorte zu einem einzigen Lake, müssen die Daten nicht mehr zwischen unterschiedlichen Systemen verschoben oder kopiert werden. OneLake basiert auf Azure Data Lake Storage (ADLS), sodass Daten in jedem Dateiformat gespeichert werden können. Für Tabellendaten wird dabei das Delta-Parquet-Format genutzt.
Durch die Integration verschiedener Azure Dienste bietet Fabric eine umfassende Plattform zur Datenanalyse. Dazu gehören die
- Azure Data Factory zur Datenintegration,
- Power BI zur Datenanalyse und
- Azure Synapse für Data Warehousing, Datentransformationen mit Spark, Data Science mit Azure Machine Learning sowie Echtzeitanalysen von großen Datenmengen.

Lakehouse als skalierbarer Datenspeicher
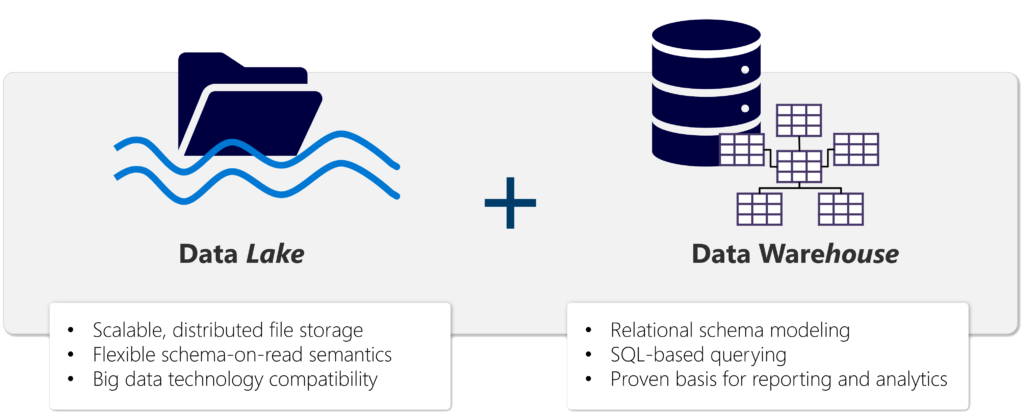
Die Grundlage von Microsoft Fabric ist ein Lakehouse, das auf der skalierbaren Speicherschicht von OneLake basiert und die Apache Spark- und SQL-Compute-Engines für die Big-Data-Verarbeitung verwendet. Ein Lakehouse ist eine vereinheitlichte Plattform, die Elemente sowohl von Data Warehouses als auch von Data Lakes kombiniert. Durch diese Kombination stellt das Lakehouse in Fabric einen skalierbaren und flexiblen Datenspeicher für Dateien und Tabellen bereit, der mit SQL abgefragt werden kann.
Ein Data Warehouse ist traditionell darauf ausgerichtet, strukturierte Daten aus verschiedenen Quellen zu integrieren und für die Analyse in einer optimierten, leistungsstarken Umgebung bereitzustellen. Data Lakes hingegen sind flexiblere Speicherumgebungen, die eine breite Palette von strukturierten, unstrukturierten und halbstrukturierten Daten in ihrem nativen Format aufnehmen können.
Lakehouses kombinieren die SQL-basierten Analysefunktionen eines relationalen Data Warehouse mit der Flexibilität und Skalierbarkeit eines Data Lake. Ein Lakehouse ermöglicht es Unternehmen, sowohl strukturierte als auch unstrukturierte Daten in einem zentralen Repository zu speichern und sie für Analysezwecke zu nutzen, unabhängig von der Datenform oder -quelle. Mithilfe von Delta Lake-formatierten Tabellen unterstützen Lakehouses dabei ACID-Transaktionen, sodass bei Datenänderungen die Atomarität (Transaktionen werden als eine einzelne Arbeitseinheit abgeschlossen), Konsistenz (Transaktionen verlassen die Datenbank in einem konsistenten Zustand), Isolation (laufende Transaktionen können sich nicht gegenseitig beeinträchtigen) und Dauerhaftigkeit (wenn eine Transaktion abgeschlossen ist, werden die vorgenommenen Änderungen dauerhaft gespeichert) gewährleistet wird.
Data Governance in Microsoft Fabric
Durch die zentrale Speicherung im OneLake können Governance– und Sicherheitsrichtlinien für alle Komponenten einfach erstellt und kontrolliert werden. Im Admin Center können
- Nutzergruppen und Berechtigungen verwaltet,
- Datenquellen und Gateways konfiguriert sowie
- die Nutzung und Leistung überwacht werden.
Zudem verwendet Fabric die Vertraulichkeitsbezeichnungen von Microsoft Purview Information Protection zum Klassifizieren und Schutz vertraulicher Daten.
ETL-Prozess in Fabric
MS Fabric bietet verschiedenste Möglichkeiten zur Datenintegration. Der einfachste Weg, kleinere Datensätze in Fabric zu laden, besteht im Upload von Ordnern oder einzelner Dateien, beispielsweise im CSV, Parquet oder JSON-Format. Anschließend können diese Dateien in Delta Tabellen umgewandelt werden. Zudem können Daten mithilfe von SQL in Fabric geladen und aufbereitet werden.
Professionelle ETL-Strecken können mit Azure Data Factory und Dataflows Gen2 innerhalb der Fabric Umgebung entwickelt werden. Damit können Daten aus zahlreichen Quellen angebunden, transformiert und in ein Lakehouse geladen werden. Durch die Erstellung eines Zeitplans zur regelmäßigen Ausführung von Data Factory Pipelines und Dataflows können ETL-Prozesse automatisiert werden.
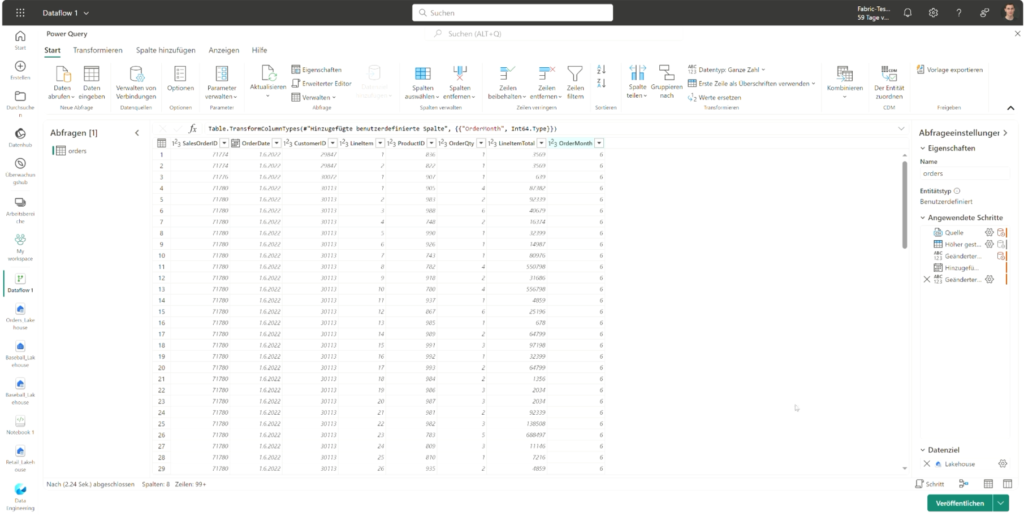
Zudem können Verknüpfungen (Shortcuts) zu anderen Datenquellen hergestellt werden, sodass auf Daten außerhalb von MS Fabric zugegriffen werden kann, ohne die Daten verschieben oder kopieren zu müssen. Die Daten können dabei an einem anderen Ort innerhalb von OneLake liegen oder sich auf einer externen Quelle, wie Azure Data Lake Storage, Databricks oder AWS S3, befinden.
Datenanalyse in Microsoft Fabric
Die Lakehouse Architektur ermöglicht es, in Fabric integrierte Daten aus unterschiedlichen Formaten mit SQL abzufragen. Die SQL-Abfragen werden dabei automatisch von Fabric gespeichert, sodass diese jederzeit wiederverwendet werden können.
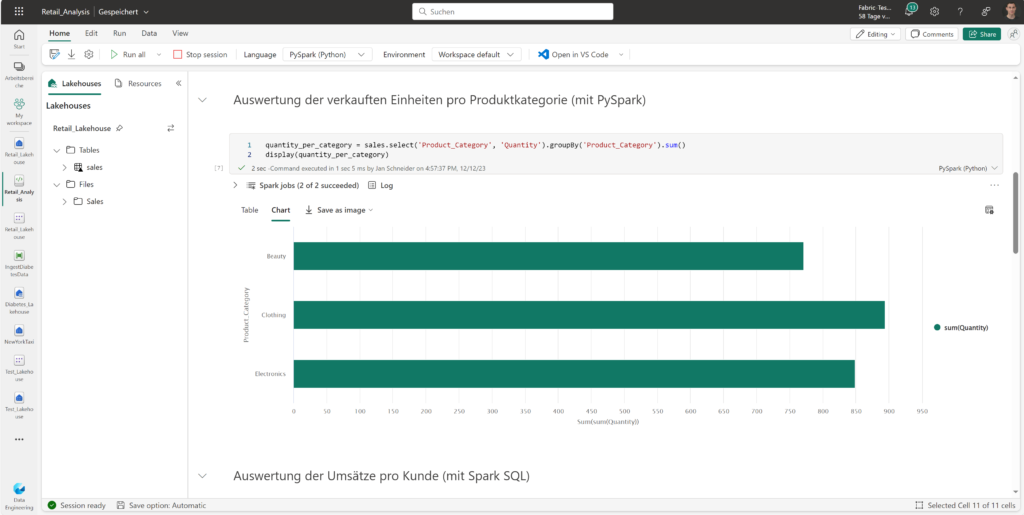
Für komplexe Analysen können in Fabric Notebooks erstellt werden, welche die Programmierung in
- PySpark,
- Spark SQL,
- Spark R und
- Scala unterstützen.
Durch die Verwendung von Spark können auch große Datensätze effizient verarbeitet werden. Innerhalb der Notebooks können die Daten beliebig transformiert, analysiert und visualisiert werden.
Des Weiteren ist es in Fabric sehr einfach, Power BI Reports an die Daten im OneLake anzubinden. Dazu kann Power BI direkt in Fabric oder als Desktop Applikation genutzt werden. Mit Direct Lake können Dateien im Parquet-Format direkt aus einem Data Lake geladen werden, ohne einen Endpunkt von einem Data Warehouse oder Lakehouse abfragen und Daten in ein Power BI Modell importieren oder duplizieren zu müssen. Dies ermöglicht das Analysieren sehr großer Datenmengen in Power BI.
Lizenzen und Kosten von Microsoft Fabric
Microsoft Fabric verfügt über Kapazitäts- und Einzelbenutzerlizenzen. Für die Zusammenarbeit und Freigabe von Inhalten wird eine F- oder P-Kapazitätslizenz und mindestens eine Einzelbenutzerlizenz benötigt.
Die Kapazitätslizenzen sind in Stock Keeping Units (SKUs) aufgeteilt. Jede SKU stellt dabei mehrere Fabric-Ressourcen bereit. In der folgenden Tabelle werden die Microsoft Fabric-SKUs aufgeführt. Kapazitätseinheiten (Capacity Units, CU) messen für jede SKU die verfügbare Computeleistung. Die F64-Kapazität entspricht einer PowerBI Premium Lizenz (P1).
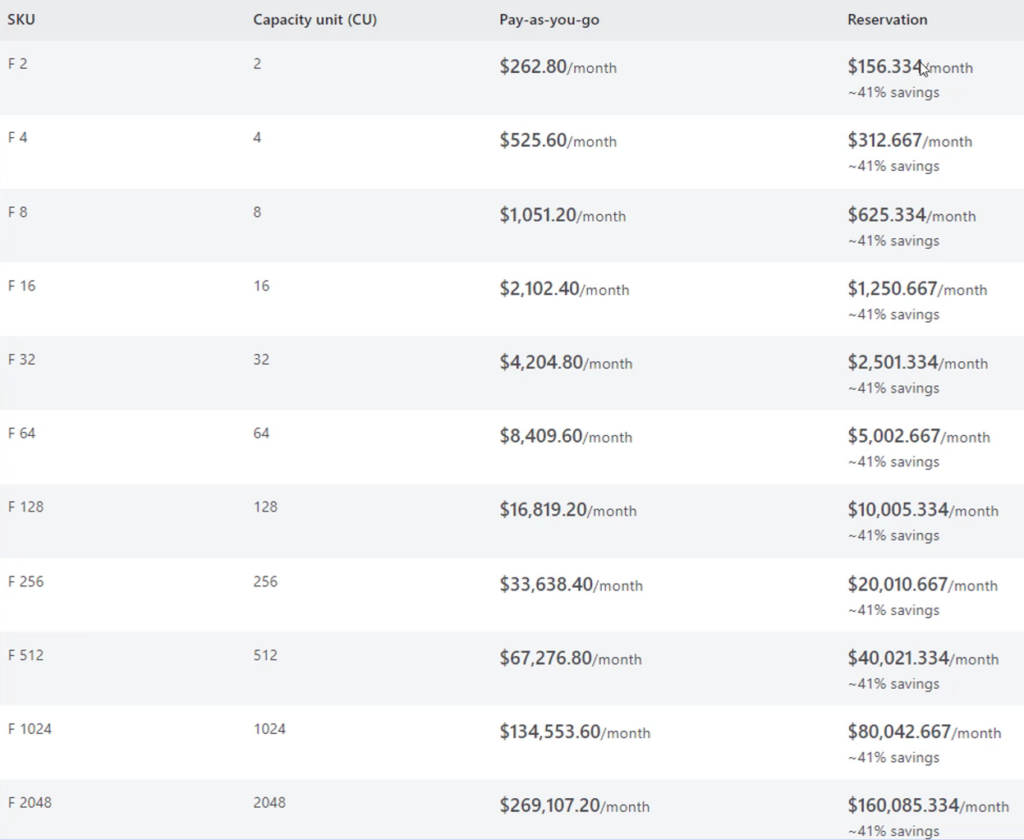
Einzelbenutzerlizenzen können in Microsoft Fabric-Kapazitäten erstellt werden und bestimmen darüber, welche Funktionen verfügbar sind. Es gibt drei Arten von Einzellizenzen:
- Kostenlos: Mit einer kostenlosen Lizenz können Sie Fabric-Inhalte (mit Ausnahme von Power BI-Elementen) in Microsoft Fabric erstellen und freigeben, wenn Sie Zugriff auf eine Fabric-Kapazität (entweder eine Test- oder eine kostenpflichtige Version) haben.
- Pro: Mit einer Pro-Lizenz können Sie Power BI-Inhalte für andere Benutzer freigeben. Jede Organisation benötigt mindestens einen Benutzer mit einer Pro- oder einer Premium-Einzelbenutzerlizenz (Premium Per User, PPU), wenn sie Power BI in Fabric verwenden möchte.
- Premium-Einzelbenutzerlizenz (Premium Per User, PPU): PPU-Lizenzen gewähren Organisationen den Zugriff auf Premium-Features von Power BI, indem jeder Benutzer eine PPU-Lizenz erhält, anstatt eine Power BI-Premium-Kapazität zu erwerben. PPU kann kostengünstiger sein, wenn Power BI Premium-Features für weniger als 250 Benutzer benötigt werden.
Fazit Microsoft Fabric
Microsoft Fabric ist eine Software-as-a-Service-Plattform für Datenintegration, Data Engineering, Data Science, Data Warehousing, Echtzeitanalysen und Business Intelligence. Die Komponenten und Funktionen von Fabric sowie die Lakehouse Architektur bieten vielfältige Möglichkeiten zur Erfassung, Verarbeitung, Speicherung und Analyse von Daten.
Weitere Informationen mit Praxisbeispielen finden Sie in unserem Showcase zu Microsoft Fabric.
Interessiert an Fabrics? Schauen Sie sich unser Microsoft Fabric Einführung oder Data Strategy & Analytics Assessment an.
Übersicht der Data Integration (Migration & ETL) Serie:
- Einführung in Microsoft Azure Data Factory
- Einführung in Azure DevOps
- Schritte zur erfolgreichen Umsetzung eines DevOps-Projekts: Tools, Techniken und Best Practices
- Einführung & Anwendungsbeispiel in Databricks
- Einführung & Anwendungsbeispiele in Microsoft Fabric
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns!
Ihr Ansprechpartner





