Fortgeschritten

Serie | Data Science – Maschinelles Lernen in Databricks mithilfe von MLlib
Serie | Data Science – Maschinelles Lernen in Databricks mithilfe von MLlib Einführung In den letzten Jahren hat maschinelles Lernen die Art und Weise, wie Unternehmen Daten analysieren und nutzen, erheblich verändert. Die MLlib-Bibliothek, bereitgestellt von Databricks, einer Multi-Cloud-Lakehouse-Plattform basierend auf Apache Spark, bietet eine Vielzahl an Werkzeugen für maschinelles Lernen. Eines dieser Werkzeuge ist die binäre Klassifikation, mit der

Serie | BI-Plattformen – Aufbau der MicroStrategy Plattform
Serie | BI-Plattformen – Aufbau der MicroStrategy Plattform MicroStrategy zählt zu den führenden Plattformen für Business Intelligence und Analytics und bietet innovative Lösungen für Unternehmen jeder Größe und Branche, um fundierte Entscheidungen auf Basis ihrer Daten zu treffen. Wie bereits im letzten Impuls-Bericht unserer BI-Plattformen-Serie „Einführung in MicroStrategy“ erwähnt, besteht die Plattform aus verschiedenen Komponenten, wie beispielsweise dem Intelligence Server,

Serie | BI-Plattformen – Einführung in MicroStrategy
Serie | BI-Plattformen – Einführung in MicroStrategy Einführung in die MicroStrategy BI-Anwendung MicroStrategy ist eine führende Business-Intelligence- und Analytics-Plattform, die Unternehmen dabei unterstützt, fundierte Entscheidungen auf Basis von Daten zu treffen. Gegründet im Jahr 1989 hat sich das Unternehmen zu einem wichtigen Akteur im Bereich der Unternehmensanalytik entwickelt. Mit seinem umfangreichen Produktportfolio und seiner innovativen Technologie bietet MicroStrategy Lösungen für
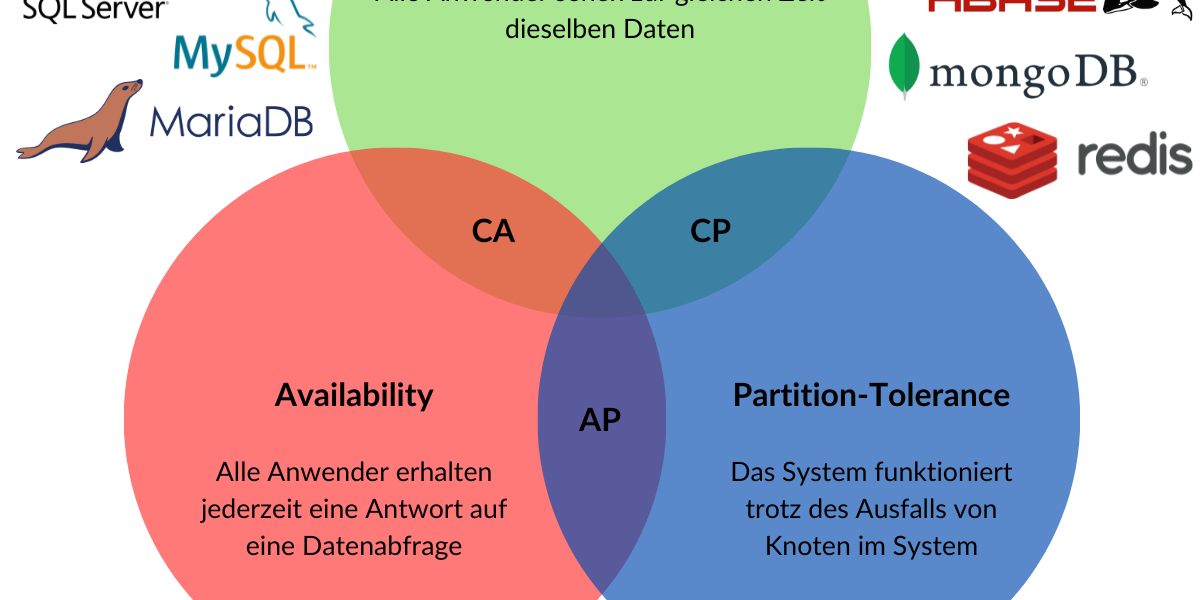
Serie | Database, Data Warehouse & Data Lake – Einführung in NoSQL-Datenbanken
Serie | Database, Data Warehouse & Data Lake – Einführung in NoSQL-Datenbanken NoSQL (englisch für „Not only SQL“) bezeichnet Datenbanken mit einem nicht-relationalen Ansatz zur Speicherung von Daten in einem flexiblen Schema. Dadurch können sowohl strukturierte als auch unstrukturierte Daten effizient gespeichert und genutzt werden, ohne diese in ein bestimmtes Format zu transformieren. Weitere Vorteile von NoSQL-Datenbanken sind eine hohe
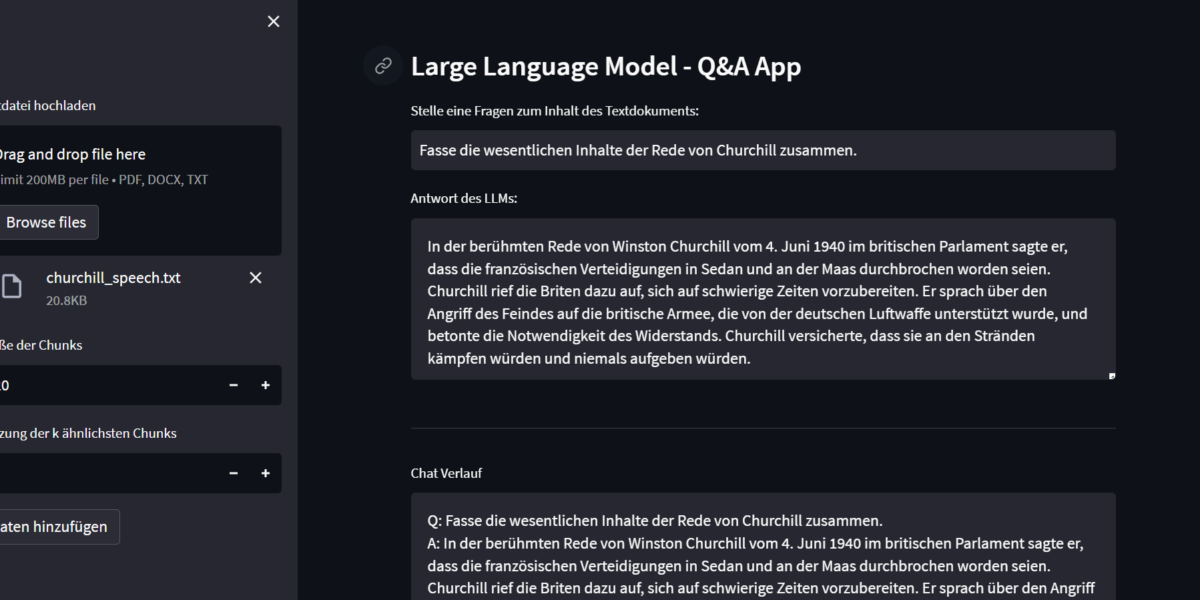
Serie | Data Science – Entwicklung eines Large Language Modells mit LangChain & OpenAI
Serie | Data Science – Entwicklung eines Large Language Modells mit LangChain & OpenAI Large Language Modelle, wie Chat-GPT, verstehen und generieren menschenähnliche Texte in unterschiedlichen Kontexten. Sie können komplexe Aufgaben wie Übersetzungen, Texterstellung und Problembehandlung bewältigen. Ihr adaptives Lernen ermöglicht es, vielfältige Anfragen zu verstehen und präzise Antworten zu liefern. Allerdings kann beispielsweise Chat-GPT nur die Informationen zur Generierung

Serie | Data Science – Prompt Engineering in ChatGPT
Serie | Data Science – Prompt Engineering in ChatGPT Einführung Die rasante Entwicklung künstlicher Intelligenz (KI) und natürlicher Sprachverarbeitung (NLP) hat neue Möglichkeiten eröffnet, wie wir mit Technologie interagieren können. Ein Schlüsselelement dieser Interaktion ist das sogenannte „Prompt Engineering„, eine Methode, die entscheidend für die Effizienz und Effektivität von Large Language Models (LLMs) wie ChatGPT geworden ist. Was sind Prompts?

Serie | Data Science – Das Large Language Model GPT-4
Serie | Data Science – Das Large Language Model GPT-4 OpenAI’s GPT-4-Modell Wie bereits im vorherigen Impuls-Bericht „Large Language Models“ unserer Data Science-Serie erläutert, ist OpenAI’s GPT-Modell ein leistungsstarkes KI-Modell, die auf umfangreichen Textdaten mittels selbst-überwachtem (self-supervised), überwachtem (supervised) und verstärkendem (reinforcement) Lernen trainiert wird. Es ist dazu in der Lage, natürliche Sprache zu verstehen sowie zu generieren und wird

Serie | Data Science – Large Language Models
Serie | Data Science – Was sind Large Language Models? Was sind Large Language Models? Large Language Models (LLMs) sind leistungsstarke KI-Modelle, die auf umfangreichen Textdaten trainiert werden. Sie haben die Fähigkeit, natürliche Sprache zu verstehen und zu generieren. LLMs werden für verschiedene Natural Language Processing (NLP)-Aufgaben eingesetzt, darunter zum Beispiel: Traditionelle Ansätze zur Verarbeitung natürlicher Sprache Traditionelle Ansätze zur
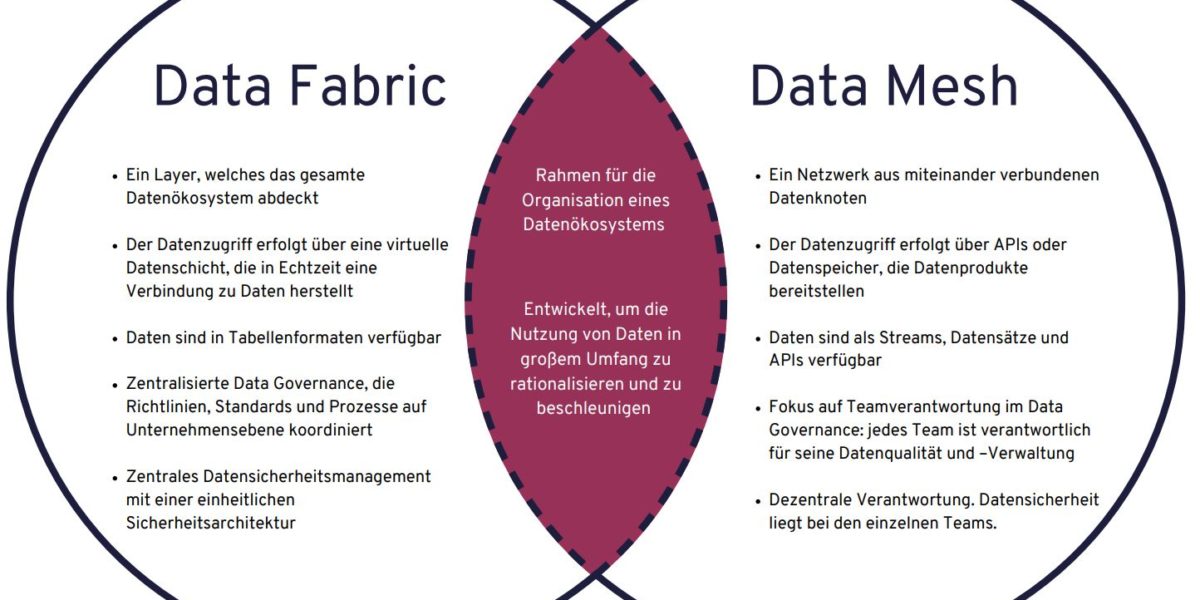
Serie | Data Governance – Data Mesh vs. Data Fabric: Welche Lösung ist besser für Ihr Unternehmen?
Data Mesh vs. Data Fabric: Welche Lösung ist besser für Ihr Unternehmen? Daten sind das Herzblut jedes modernen Unternehmens, aber sie effektiv zu verwalten, kann eine echte Herausforderung sein. Aufgrund des zunehmenden Volumens, der Vielfalt und der Geschwindigkeit der Daten haben herkömmliche Datenarchitekturen oft Schwierigkeiten, mit den Anforderungen der Datenkonsumenten und -Produzenten zurechtzukommen. Wie können Sie sicherstellen, dass Ihre Daten
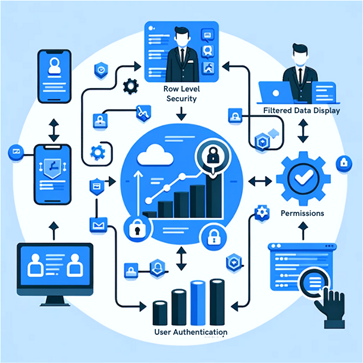
Serie | Microsoft Power Platform – Die passenden Daten für den passenden Datenkonsument
Serie | Microsoft Power Platform – Die passenden Daten für den passenden Datenkonsument Was steckt hinter der Sicherheit auf Zeilenebene (RLS) in Power BI? In der Welt der Datenanalyse und -berichterstattung ist die Datensicherheit von entscheidender Bedeutung. Insbesondere in einem Business Intelligence-Tool wie Power BI, das von Unternehmen weltweit genutzt wird, um wertvolle Einblicke in ihre Daten zu gewinnen. Ein


Seiten Links
Social
Adresse
DE-80797 München
