Serie | Data Science – Entwicklung eines Large Language Modells mit LangChain & OpenAI
Large Language Modelle, wie Chat-GPT, verstehen und generieren menschenähnliche Texte in unterschiedlichen Kontexten. Sie können komplexe Aufgaben wie Übersetzungen, Texterstellung und Problembehandlung bewältigen. Ihr adaptives Lernen ermöglicht es, vielfältige Anfragen zu verstehen und präzise Antworten zu liefern.
Allerdings kann beispielsweise Chat-GPT nur die Informationen zur Generierung von Texten nutzen, zu denen das Modell während des Trainingsprozesses Zugang hatte. Dadurch werden später erschienene Artikel nicht berücksichtigt. Ziel dieses Impulses ist die Entwicklung eines Large Language Modells, welches individuelle Textdokumente analysiert und es Anwendern über eine Webapp ermöglicht, Fragen zum Inhalt des Dokuments zu formulieren.
Funktionsweise des Large Language Modells
Large Language Modelle können neues Wissen auf zwei Wegen lernen. Die erste Möglichkeit besteht darin, ein Fine-Tuning des Modells auf einem Trainingssatz durchzuführen. So wird das neue Wissen vom Modell im Langzeitgedächtnis gespeichert, was jedoch nicht immer notwendig ist. Zudem ist der Trainingsprozess zeitaufwändig und mit hohen Rechenkosten verbunden.
Bei der zweiten Möglichkeit wird dem Modell neues Wissen durch eine Input-Nachricht vermittelt. Beispielsweise kann ein PDF-Dokument oder ein komplettes Buch als Input-Nachricht an das Modell gesendet werden. Auf diese Weise baut das Modell ein Kurzzeitgedächtnis auf und es können Fragen zum Inhalt des Textdokuments an das LLM gestellt werden. Bei einem großen Textdokument kann die Methode Schwierigkeiten bereiten, da die Input-Nachricht an ein Modell auf eine bestimmte Anzahl an Tokens limitiert ist, welche in den meisten Fällen bei etwa 4.000 Tokens liegt. Daher ist es ratsam, die Input-Nachricht mit einer Embedded-basierten Suche zu verwenden. Embeddings sind einfach zu implementieren und funktionieren besonders gut bei Fragen.
Entwicklung des LLMs
Der erste Schritt zur Nutzung des Large Language Modells besteht darin, das zu analysierende Textdokument vorzubereiten. Dazu werden die Daten in ein LangChain Dokument geladen und in einzelne Chunks aufgeteilt. Chunks sind dabei kurze, in sich geschlossene Textabschnitte. Danach werden die Chunks mithilfe eines Embedding-Modells in numerische Vektoren umgewandelt. Abschließend werden die Chunks und Embeddings in einer Vektor-Datenbank, wie Pinecone oder Chroma DB, gespeichert. Dieses Vorgehen muss für jedes Textdokument, welches der Nutzer hochlädt, einzeln durchgeführt werden.
Nach der Vorbereitung des Textdokuments können Fragen formuliert werden. Für jede Anfrage wird ein Embedding mit dem gleichen Embedding-Modell generiert. Das Embedding der Frage wird dann mit den Embeddings der einzelnen Chunks des Textdokuments verglichen, indem mithilfe der Kosinus Ähnlichkeit oder der euklidischen Distanz eine Ähnlichkeit zwischen den Vektoren berechnet wird. Die nächsten Vektoren repräsentieren Chunks, welche ähnlich zur Frage sind. Die relevantesten Chunks und die Frage werden dann als Nachricht an das Large Language Modell geschickt, welches eine Antwort generiert und zurückgibt.
Erstellung einer Webapp zur Zusammenfassung von Textdokumenten
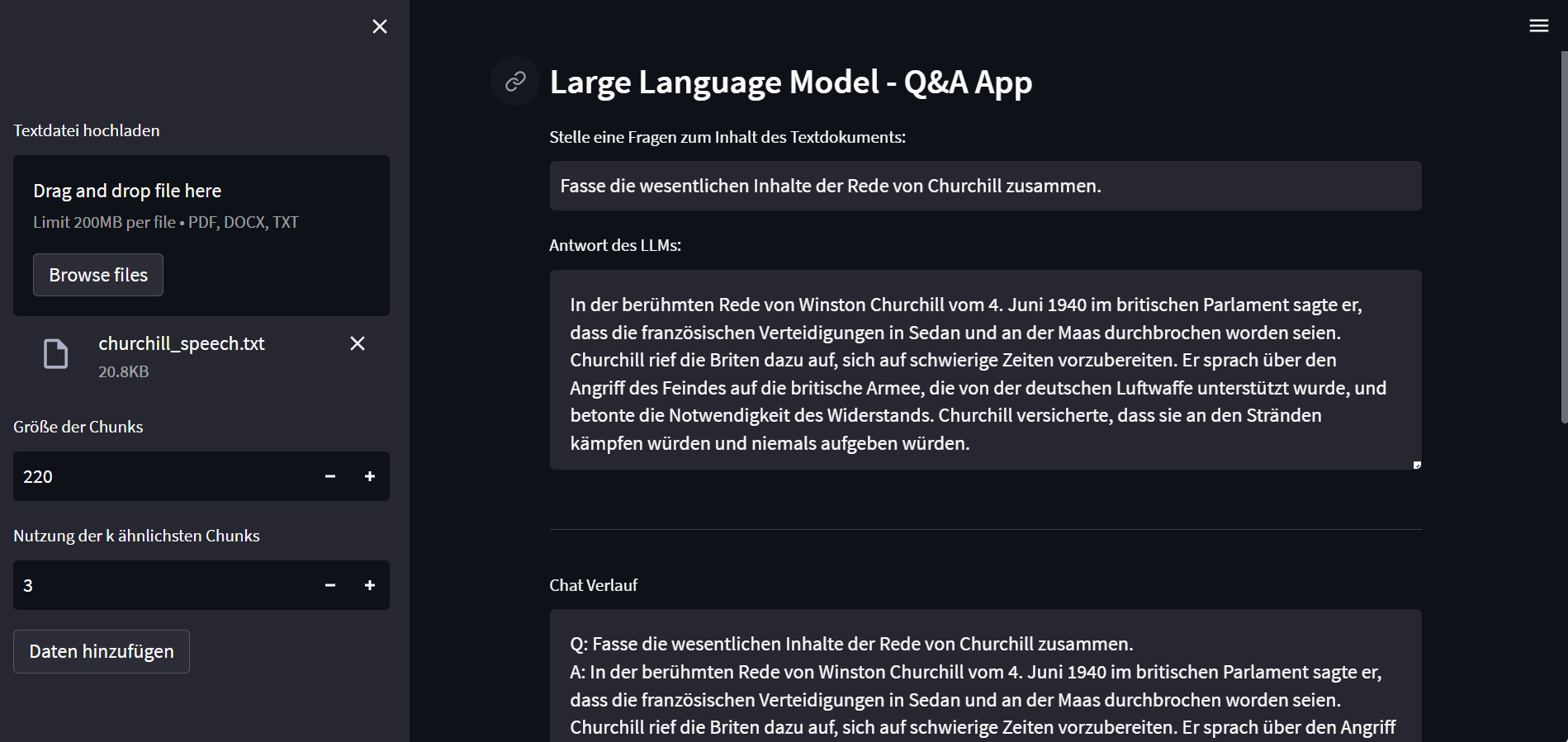
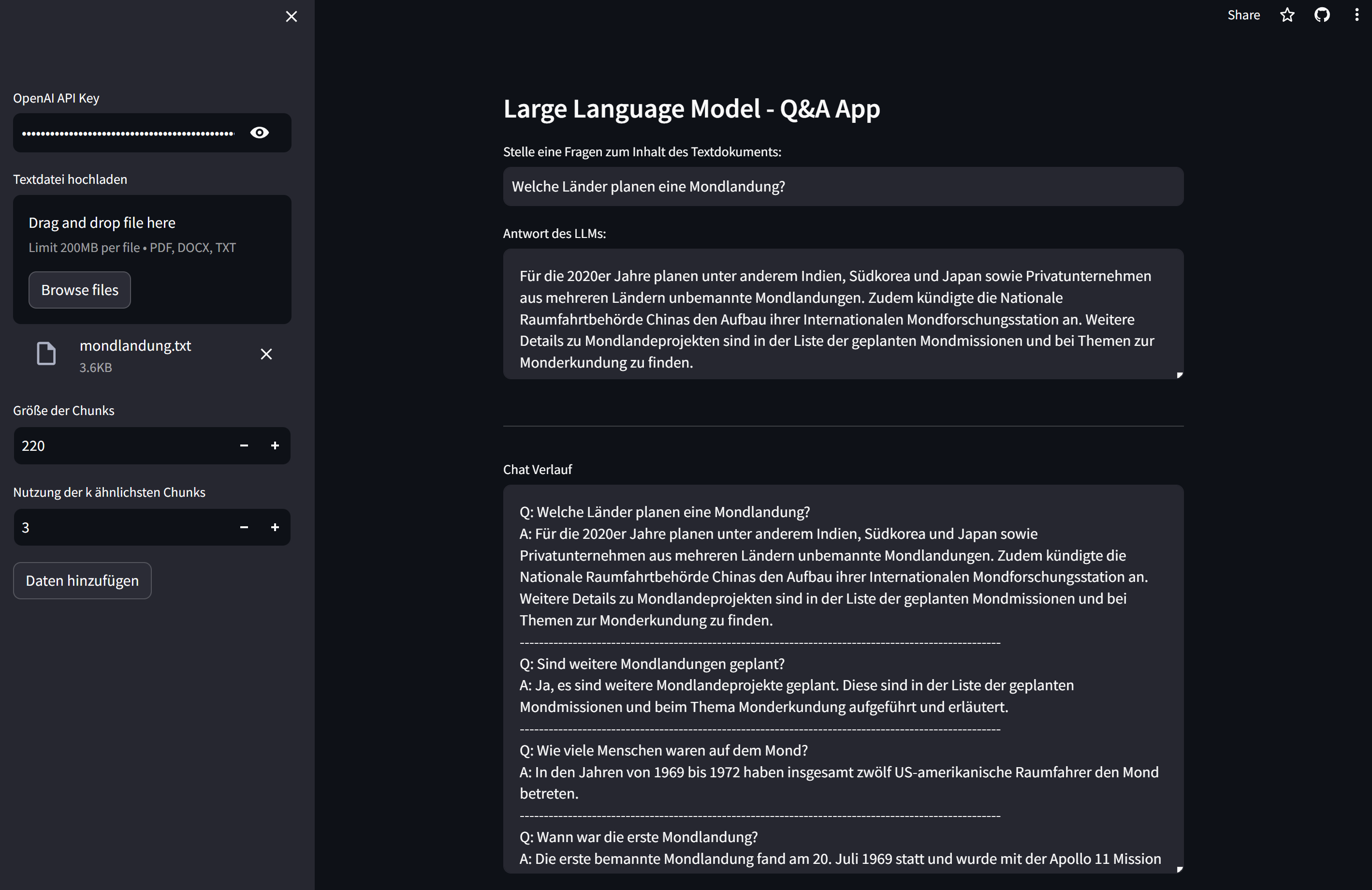
Zur Nutzung des Large Language Modells wurde eine Webapplikation mit Streamlit entwickelt. Dort können Nutzer Textdokumente als PDF, Word oder Textdatei hochladen und die Parameter für die maximale Größe der einzelnen Chunks bei der Aufteilung des Dokuments in mehrere Textabschnitte und die Anzahl der Chunks mit der höchsten Ähnlichkeit festlegen, welche zur Beantwortung von Fragen genutzt werden. Danach können Fragen zum Inhalt des Textdokuments formuliert werden, woraufhin eine vom Large Language Modell generierte Antwort ausgegeben wird. Dabei wird auch der Verlauf des Chats mit angezeigt und vom Large Language Modell bei anschließenden Fragen mitberücksichtigt.
Fazit
Mithilfe des entwickelten Large Language Modells können individuelle Textdokumente analysiert werden. Die Webapp bietet Nutzern die Möglichkeit, Fragen zum Inhalt eines Textdokuments an das Large Language Modell zu stellen und die Antworten im Chat-Verlauf einzusehen.
Falls Sie das Large Language Modell mit eigenen Textdokumenten testen wollen, finden Sie die Webapp hier: https://llm-showcase.streamlit.app/
Eine detaillierte Erläuterung zur Funktionsweise, zum Training, zu Einsatzmöglichkeiten und Zugriff sowie zu den Vorteilen und Herausforderungen von LLMs wie GPT-4 kann in unseren vorherigen Impuls Berichten Large Language Models und Das Large Language Model GPT-4 nachgelesen werden.
Sie möchten mehr über die Möglichkeiten von LLM erfahren? Dann nichts wie ab zu unserem Data Strategy & Analytics Assessment!
Übersicht der Data Science (ML & AI) Serie:
- AI im Fußball: Entwicklung eines Expected Goals Modells
- Einführung in Deep Learning und PyTorch
- NLP zur Analyse von E-Mails
- Entwicklung eines Machine Learning Modells auf Azure
- Architektur und Funktionsweise von neuronalen Netzen
- Entwicklung eines neuronalen Netzes zur Prädiktion von Airbnb-Preisen
- Architektur und Funktionsweise von baumartigen Regressionsverfahren
- Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
- Was sind Large Language Modelle
- Das Large Language Model GPT-4
- Prompt Engineering in ChatGPT
- Entwicklung eines Large Language Modells mit LangChain & OpenAI
- Überblick zu Künstlicher Intelligenz, Machine Learning und Deep Learning
- Maschinelles Lernen in Databricks mithilfe von MLlib
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns!
Ihr Ansprechpartner



