
Serie | Data Science (ML & AI) – Entwicklung eines Machine Learning Modells auf Azure
Was ist Azure Machine Learning?
Azure Machine Learning ist ein Cloud Service zum Management des Workflows von Machine Learning Projekten. Dazu gehört die Datenvorbereitung, das Training und Deployment von Modellen sowie MLOps zur Überwachung und Verwaltung der Modelle.
Azure Machine Learning Studio bietet mehrere Optionen zur Entwicklung von Machine Learning Modellen:
- Notebooks: Hier können Jupyter Notebooks direkt in Azure Machine Learning Studio implementiert und ausgeführt werden
- Automated Machine Learning: mit automatisierten ML-Experimenten können Modelle über eine Benutzeroberfläche erstellt werden
- Azure Machine Learning Designer: mit dem Designer ist das Training und Deployment von Machine Learning Modellen möglich, ohne eigenen Code zu schreiben. Per Drag & Drop werden Datensätze und Komponenten zu einer Machine Learning Pipeline zusammengesetzt.
Im Folgenden werden diese drei Methoden ausgewertet und die Ergebnisse der jeweils resultierenden Modelle miteinander verglichen. Dabei soll ein Modell trainiert werden, welches die Kreditwürdigkeit eines Kunden für einen Hauskredit vorhersagt. So kann ein Unternehmen auf Basis der Angaben von Kunden automatisiert feststellen, welche Kunden sich für die Vergabe eines Kredits eignen.
Upload eines Datensatzes
Zum Training des Modells wird ein Datensatz von kaggle zur Vergabe von Hauskrediten verwendet. Der Datensatz enthält 614 Einträge mit Angaben zum Geschlecht, Ehestand, Kinderanzahl, Bildungsgrad, Selbstständigkeit, Einkommen, Kreditsumme, Kreditdauer, Kredithistorie, Grundstücksfläche sowie zum Status der Kreditvergabe, welche entweder freigegeben oder abgelehnt wurde und als Zielvariable für das Modell dient.
Zur Verwendung des Datensatzes in Azure wählen wir in Azure Machine Learning Studio unter dem Tab „Data“ die Option „Create“, um ein neues Data Asset hinzuzufügen. Dort benennen wir den Datensatz als „HomeLoanApproval“ und setzen den Typ auf „Tabular“. Als Datenquelle wählen wir eine lokale Datei und nach der Auswahl des Datastores laden wir die csv-Datei hoch.
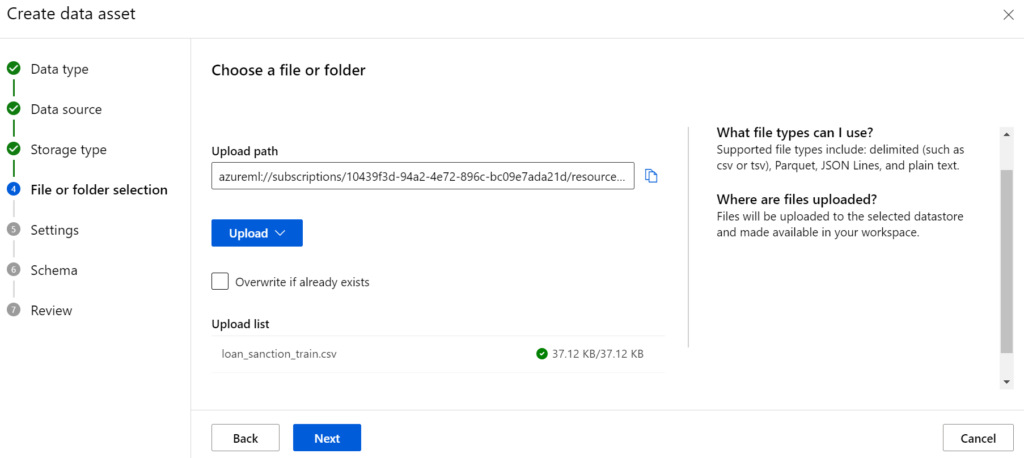
Im nächsten Schritt setzen wir die Einstellungen wie folgt und prüfen die Daten in der Preview Ansicht.
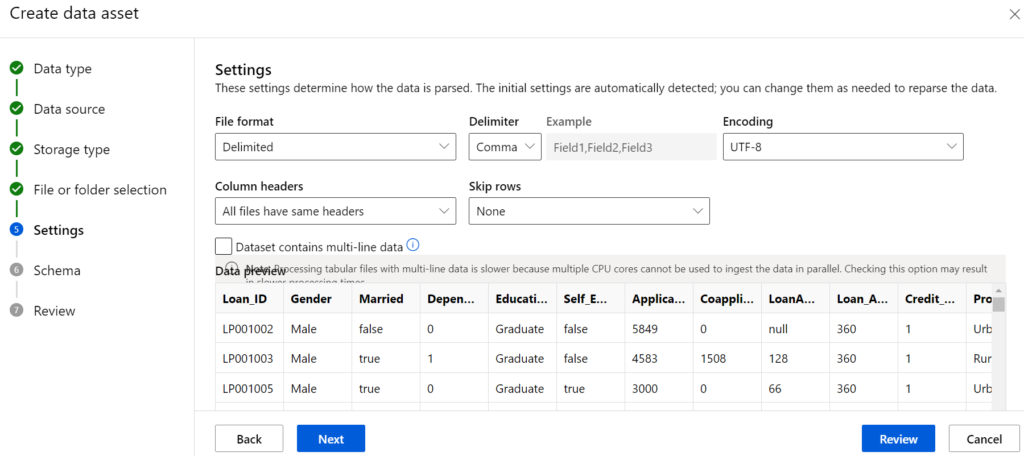
Anschließend überprüfen wir das Schema und passen gegebenenfalls die Datentypen an.
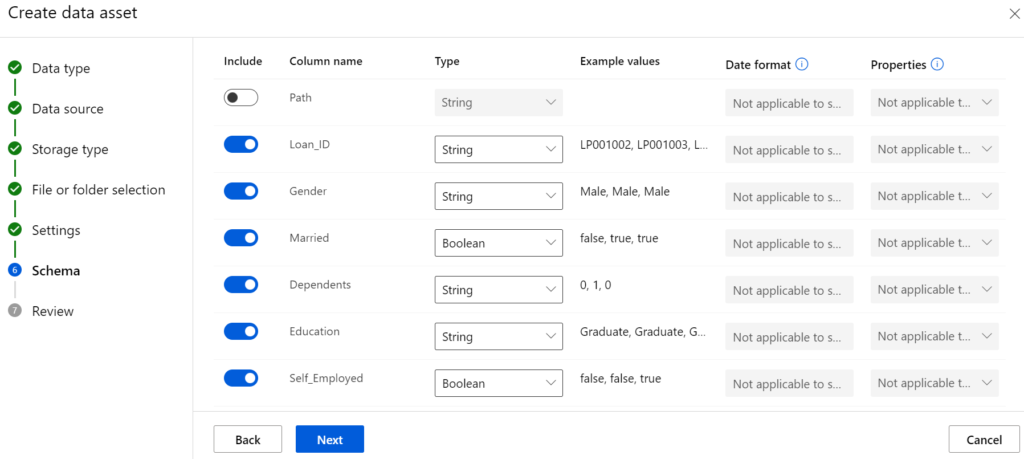
Nach Abschluss der Erstellung des Datensatzes kann dieser zum Training der Modelle genutzt werden.
Erstellung eines Compute Clusters
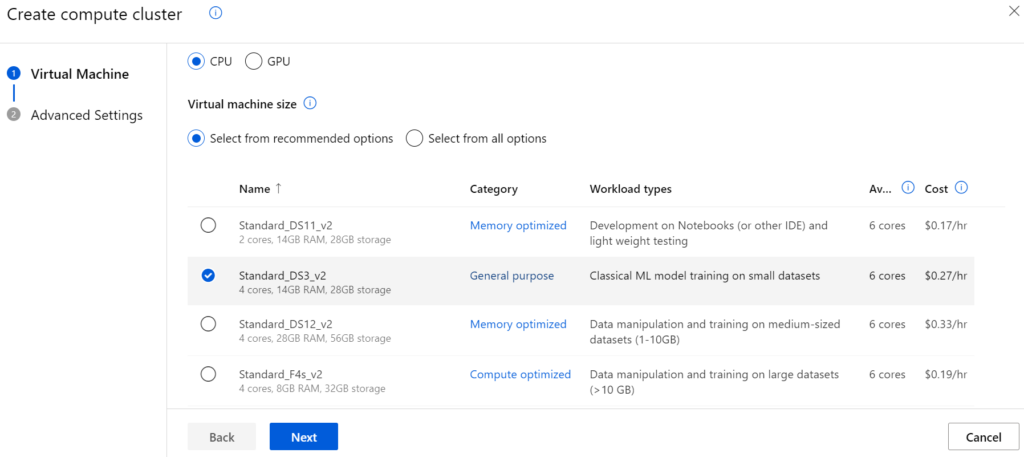
Zusätzlich zum Trainingssatz benötigen wir auch ein Compute Cluster zur Ausführung des Trainings der Machine Learning Modelle. Dazu wählen wir unter „Compute“ den Tab „Compute clusters“ aus und klicken auf „New“. Als Virtuelle Maschine verwenden wir für diesen Anwendungsfall die „Standard_DS3_v2“.
Automatisiertes Machine Learning auf Azure
Als Erstes wird ein automatisiertes Machine Learning Experiment in Azure Machine Learning Studio durchgeführt, um ein Modell zur Kreditvergabe zu erhalten. Dazu klicken wir im Tab „Automated ML“ auf die Schaltfläche „New Automated ML job“ und wählen dort den gerade erstellten Datensatz aus.
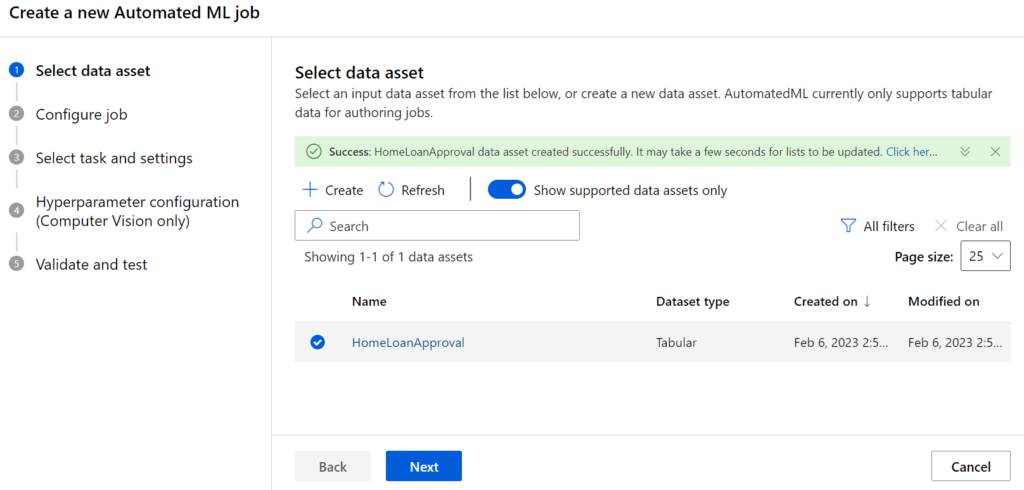
Im nächsten Schritt legen wir zur Konfiguration des Jobs ein neues Experiment an, wobei wir als Zielvariable die Spalte „Loan_Status“ und als Compute Cluster das zuvor erstellte Cluster nutzen.
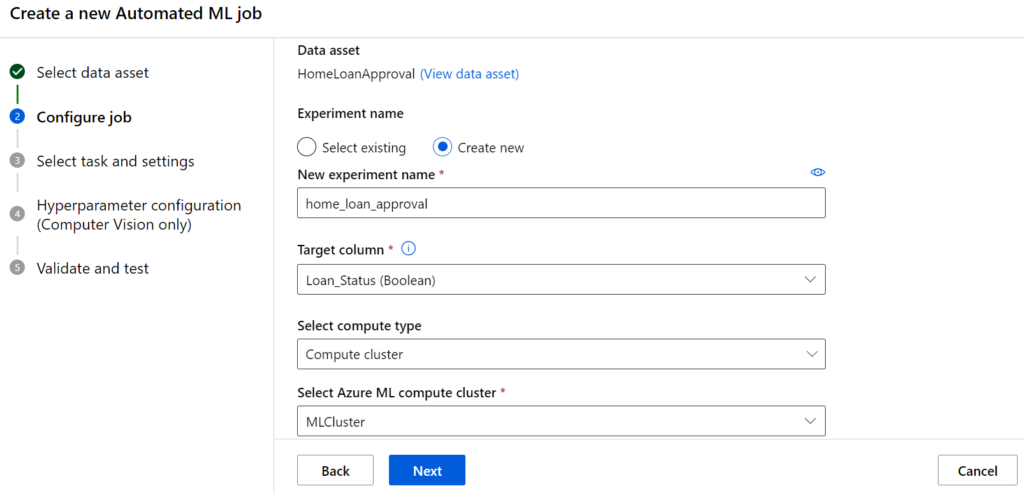
Bei der Wahl des Aufgabentyps klicken wir auf Klassifikation und zur Validierung verwenden wir eine 5-fache Kreuzvalidierung, während wir 15% des Datensatzes als Testsatz nutzen.
Nach einem Klick auf „Finish“ wird das Experiment automatisch gestartet und sobald es abgeschlossen ist, erhalten wir eine Zusammenfassung des besten Modells.
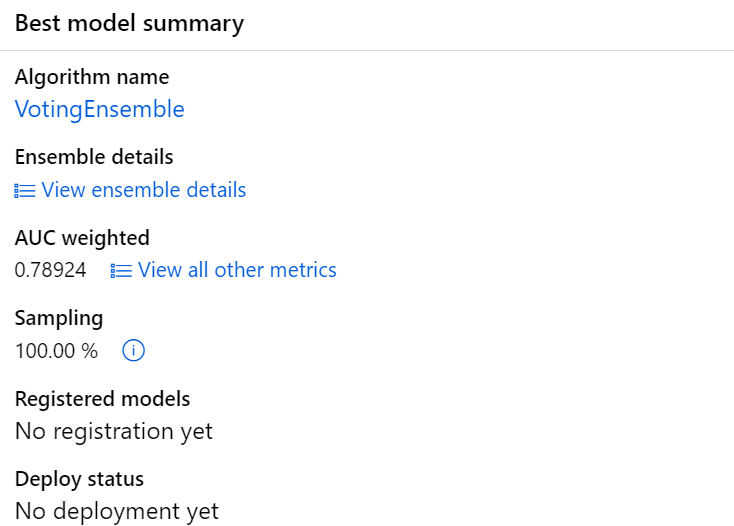
Die primäre Evaluationsmetrik des Modells ist der gewichtete AUC-Wert, welcher in diesem Fall bei 0,789 liegt. Durch einen Klick auf „VotingEnsemble“ bekommen wir weitere Details zum Modell. Beispielsweise können wir unter dem Tab „Explanations“ die Wichtigkeit der einzelnen Features im Modell auswerten.
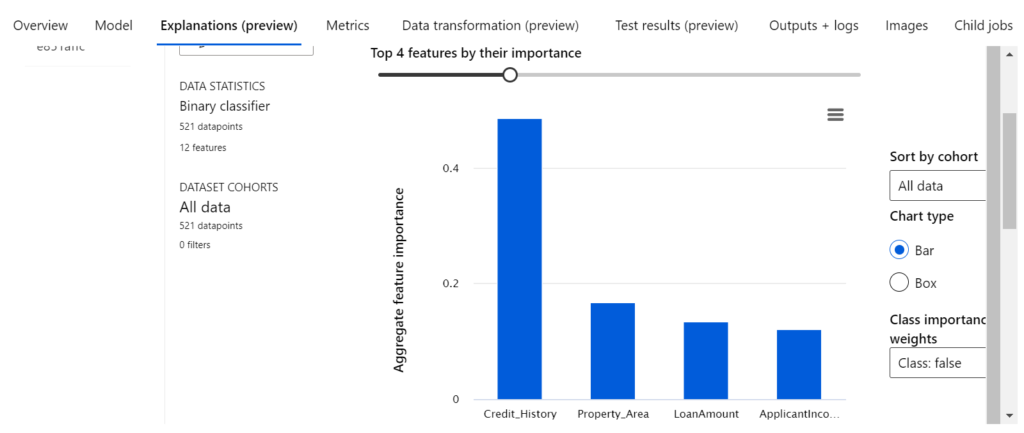
Dabei ist erkennbar, dass die Kredithistorie des Kunden den größten Einfluss auf die Vorhersage der Kreditwürdigkeit des jeweiligen Kunden durch das Modell hat.
Azure Machine Learning Designer
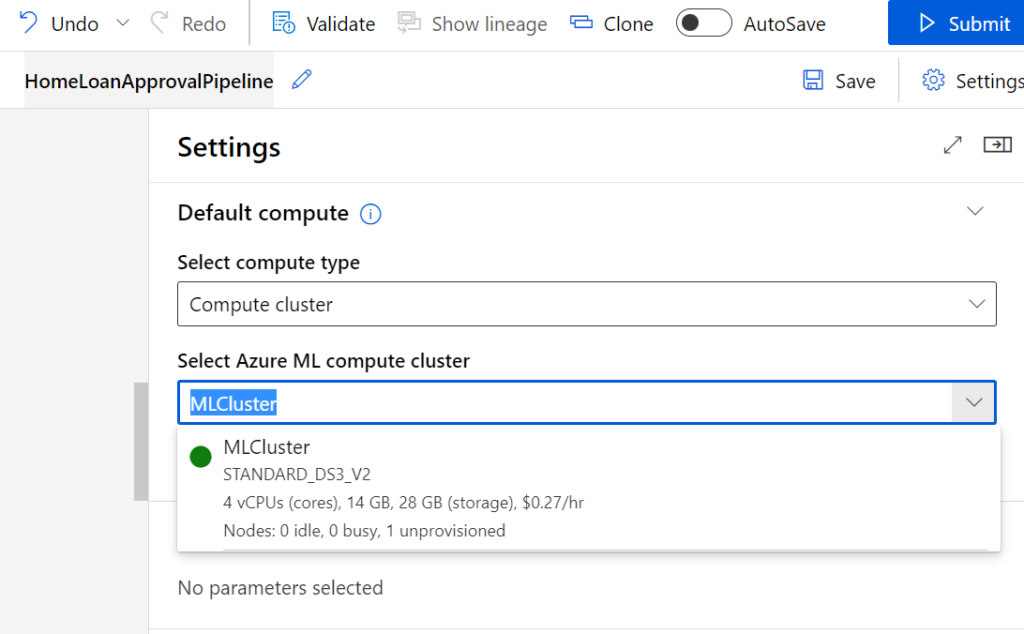
Als nächstes bauen wir das Modell zur Prädiktion der Kreditwürdigkeit mit dem Azure Machine Learning Designer. Hierfür können wir unter „Designer“ eine neue Pipeline anlegen, indem wir auf „Create a new pipeline using classic prebuilt components“ klicken. Anschließend können wir der Pipeline unter Settings das zuvor erstellte Compute Cluster zur Ausführung der Pipeline zuweisen.
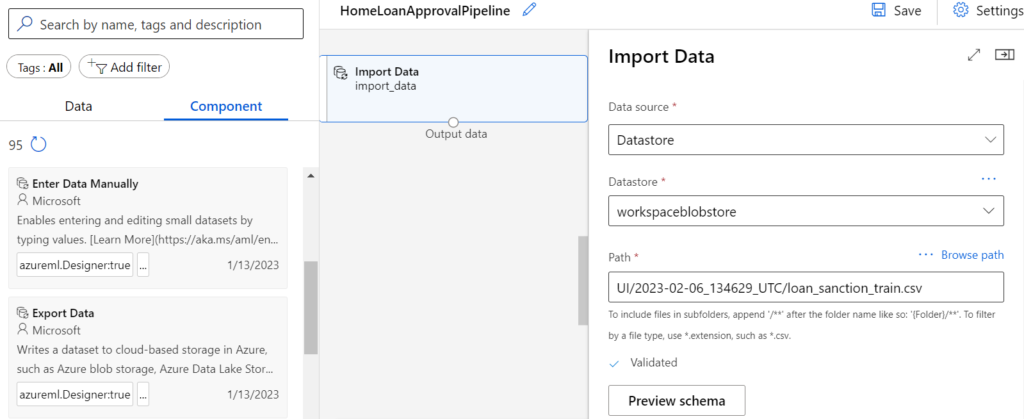
Danach können wir in dem Menü links die Komponenten unserer Pipeline auswählen und per Drag & Drop hinzufügen. Als erstes benötigen wir die Komponente „Import Data“ und geben dort den Pfad zu dem Datensatz an.
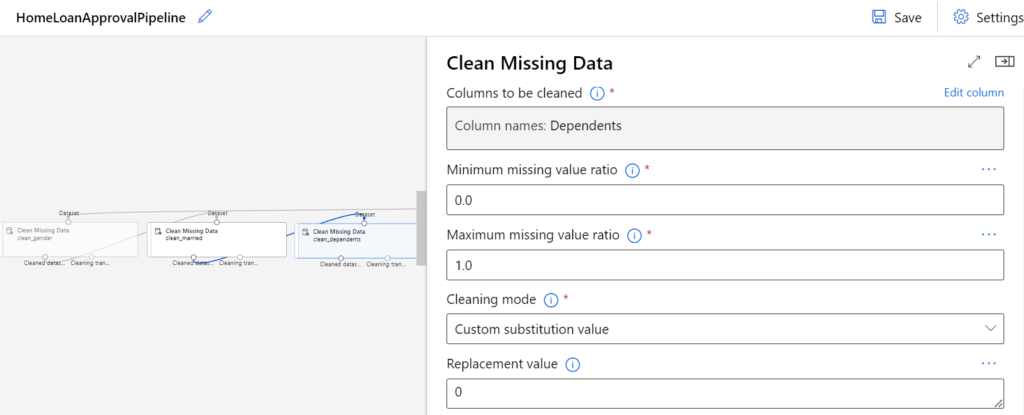
Der nächste Schritt besteht darin, die fehlenden Werte im Datensatz mithilfe der Komponente „Clean Missing Data“ zu ersetzen. Da in dieser Komponente nur ein möglicher Ersatzwert angegeben werden kann, brauchen wir mehrere Komponenten, um jeder Spalte einen passenden Ersatzwert zuzuweisen.

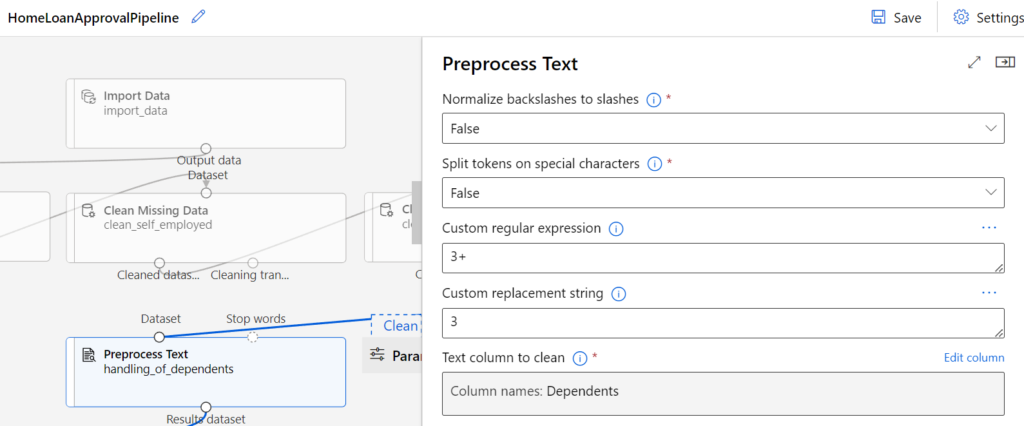
So können wir beispielsweise in der Spalte „Dependents“ die fehlenden Werte durch 0 ersetzen.
Mithilfe der Komponente „Preprocess Text“ können wir in der Spalte „Dependents“ zudem den Wert „3+“ durch „3“ ersetzen, um die Werte der Spalte als numerischen Input für Machine Learning Modelle zu verwenden.
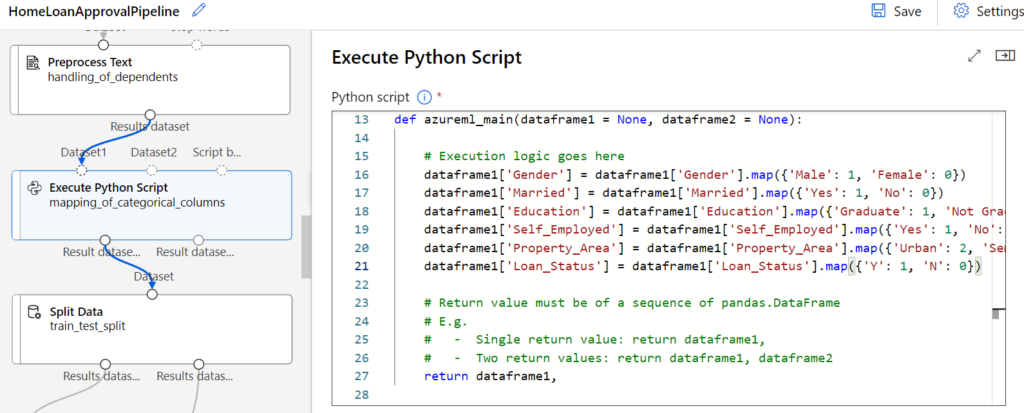
Das Mapping der weiteren kategorischen Spalten in numerische Werte führen wir mit einem Python Skript aus.
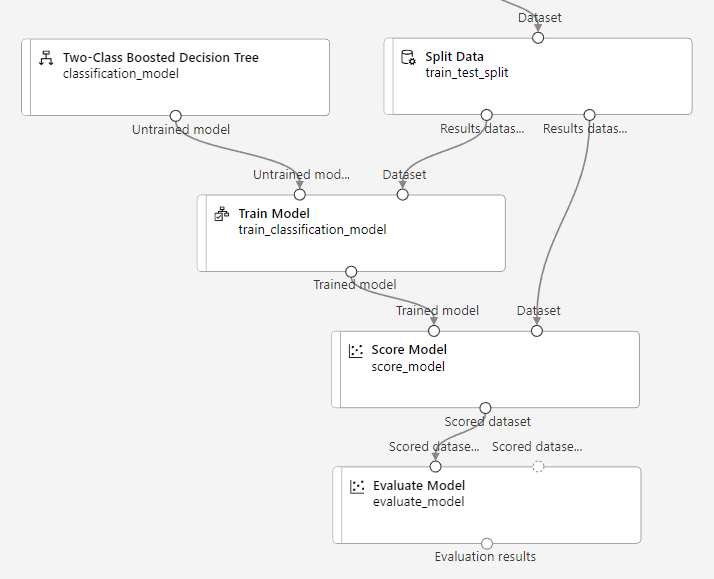
Nach der Vorbereitung der Daten teilen wir den Datensatz mit „Split Data“ in einen Trainingssatz und einen Testsatz auf, wobei der Trainingssatz 80% der Zeilen enthält. Die Komponente „Train Model“ erhält zusätzlich zum Trainingssatz auch ein Klassifikationsmodell zur Unterscheidung von zwei Klassen als Input, wobei wir uns hier für „Two-Class Boosted Decision Tree“ entschieden haben. Als Zielvariable geben wir die Spalte „Loan_Status“ an. Nach dem Training des Modells führen wir ein Scoring auf dem Testsatz durch, um das Modell schließlich zu evaluieren.
Wenn die Pipeline fertiggestellt ist, können wir diese ausführen, indem wir auf „Submit“ klicken und das Experiment zur Pipeline-Ausführung konfigurieren.
Unter „JobDetails“ sind dann die Ergebnisse der Pipeline sichtbar. Beispielsweise sehen wir nach der vollständigen Pipeline-Ausführung durch einen Doppelklick auf die „Evaluate Model“ Komponente die Evaluationsmetriken auf dem Testsatz.
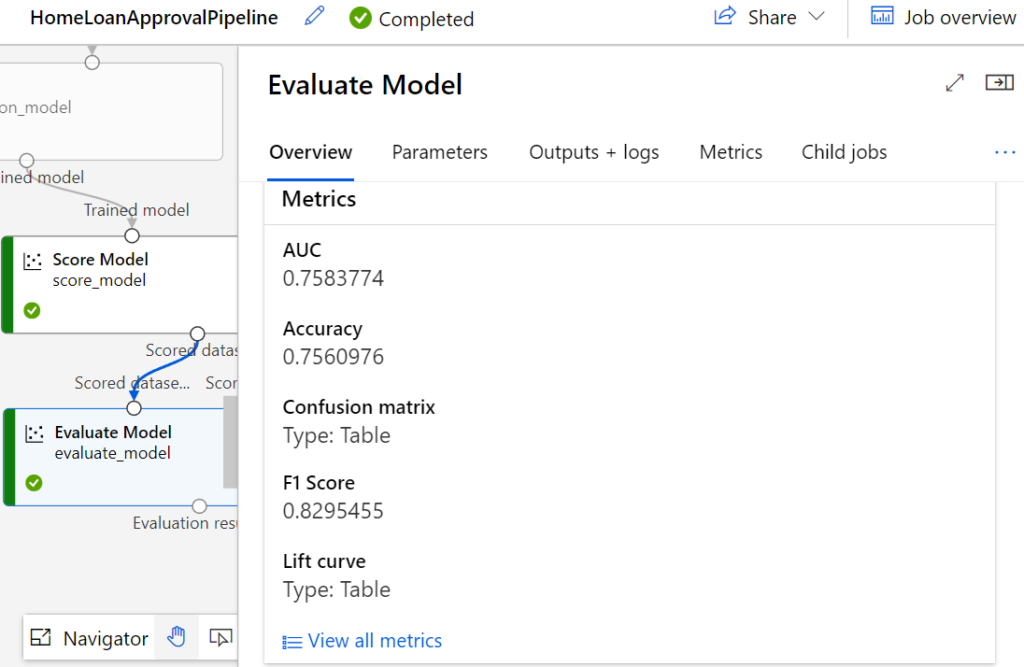
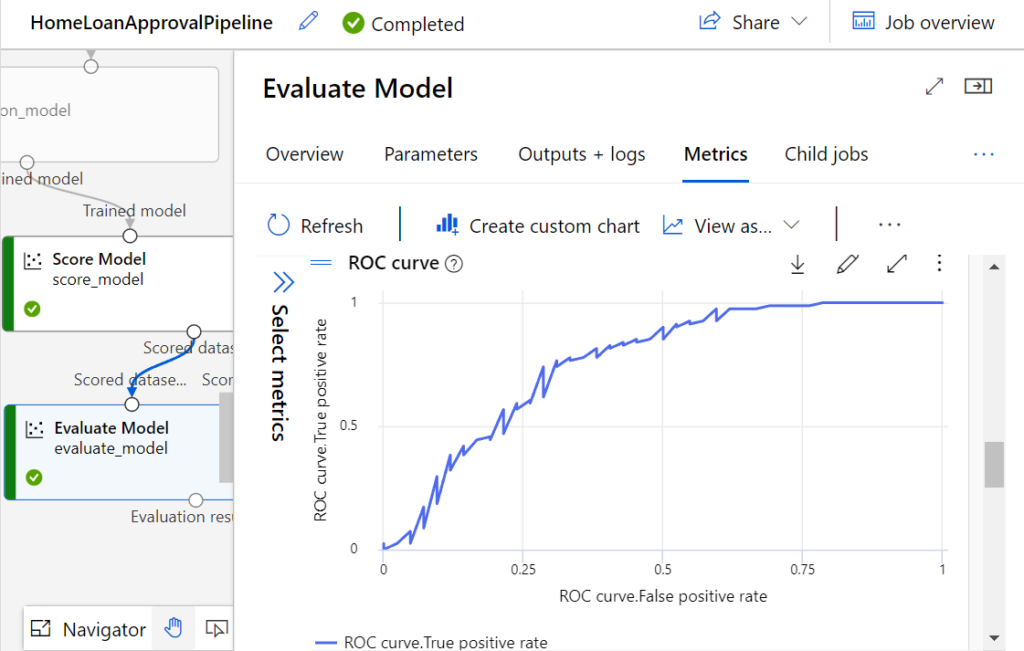
Der AUC-Wert liegt in diesem Fall bei 0,758 und auf dem Tab „Metrics“ können wir die einzelnen Metriken auch visuell betrachten. Dazu zählt beispielsweise auch die zum AUC-Wert gehörige ROC-Kurve.
Notebooks
Zum Vergleich dazu implementieren wir das Machine Learning Modell nun in einem Jupyter Notebooks innerhalb von Azure Machine Learning Studio. Dazu benötigen wir zunächst eine Compute Instance zur Ausführung von Jupyter Notebooks, welche wir unter „Compute“ im Tab „Compute instances“ hinzufügen können. Als virtuelle Maschine wählen wir dabei „Standard_DS11_v2“.
Als nächstes legen wir unter „Notebooks“ ein neues Jupyter Notebook an und weisen diesem die erstellte Compute Instance zu.
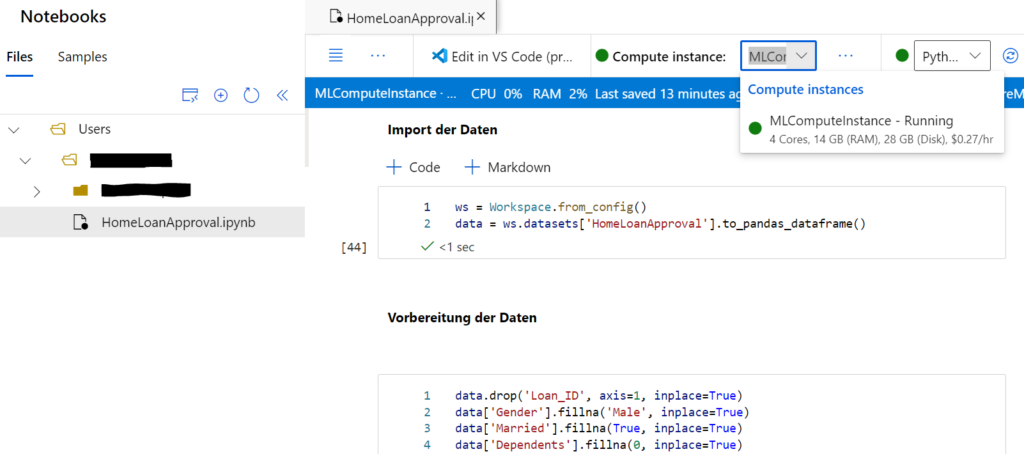
In dem Notebook importieren wir zunächst den Datensatz zur Vergabe von Hauskrediten aus dem Workspace und speichern diesen als Pandas-Dataframe ab. Anschließend werden bei der Datenvorverarbeitung fehlende Werte ersetzt, Spalten mit kategorischen Werten in numerische Werte umgewandelt und Datentypen angepasst. Vor dem Training der Modelle wird der Datensatz aufgeteilt in einen Trainingssatz und einen Testsatz, wobei der Testsatz 20% der Zeilen aus dem gesamten Datensatz enthält. Als Machine Learning Modelle werden eine Random Forest Klassifizierung und eine Gradient Boosting Klassifizierung evaluiert. Zur Hyperparameteroptimierung wird eine Grid-Suche mit 5-facher Kreuzvalidierung durchgeführt, wobei das Ziel in der Maximierung des AUC-Wertes besteht. Danach werden die besten gefundenen Hyperparameter ausgegeben und die AUC-Werte auf dem Testsatz zur Bewertung der Modelle berechnet.
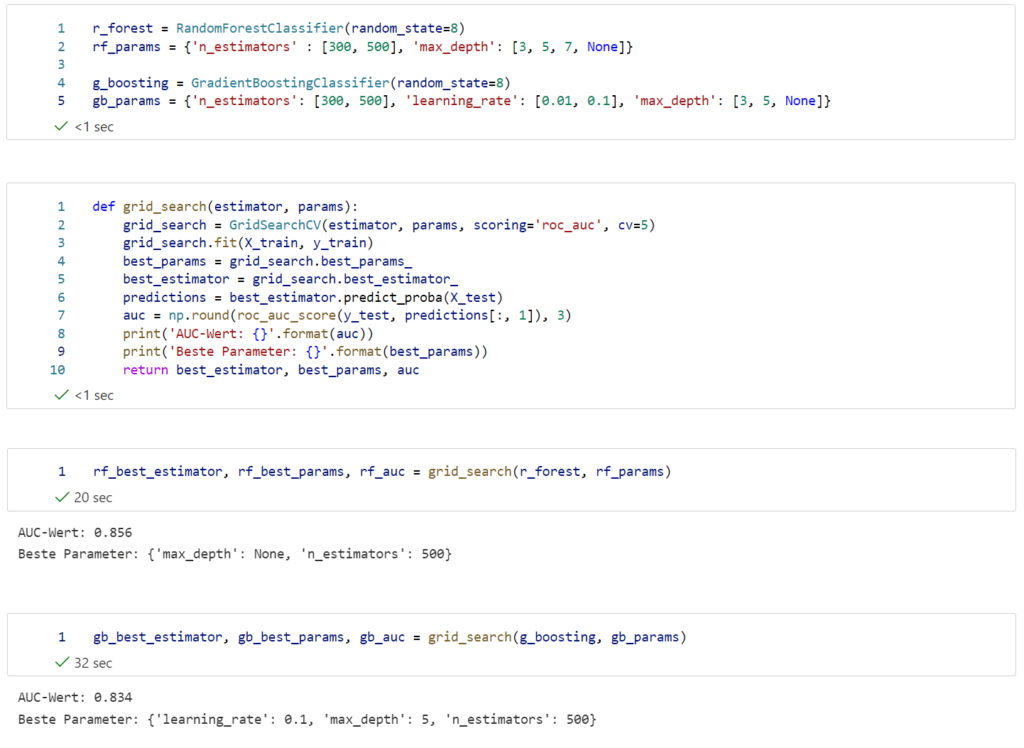
Der Random Forest Klassifizierer liefert hierbei einen AUC-Wert von 0,856 auf dem Testsatz, während der Gradient Boosting Klassifizierer einen AUC-Wert von 0,834 erreicht.
Fazit zu Machine Learning Modellen in Azure
Im Azure Machine Learning Studio gibt es drei unterschiedliche Ansätze zur Entwicklung eines Machine Learning Modells. Den besten AUC-Wert erreichte in unserem Anwendungsbeispiel die Implementierung des Modells im Notebook. Allerdings bieten der Machine Learning Designer und automatisiertes Machine Learning auch einfache Low-Code Optionen zur Erstellung von Machine Learning Modellen in Azure.
| Methode | AUC-Wert |
| Automated Machine Learning | 0,789 |
| Azure Machine Learning Designer | 0,758 |
| Jupyter Notebook | 0,856 |
Als IT-Beratung sind wir darauf spezialisiert, unseren Kunden bei der Nutzung von Maschine Learning zu helfen. Wir unterstützen Sie bei der Einrichtung, Verwaltung und Optimierung von Modellen in und außerhalb von Microsoft Azure. Datalytics steht Ihnen gerne zur Verfügung und wird ihnen helfen, die bestmöglichen Algorithmen für Ihr Unternehmen zu finden und zu implementieren.
Sie möchten mehr über die Möglichkeiten von ML & KI erfahren? Dann nichts wie ab zu unserem Data Strategy & Analytics Assessment!
Übersicht der Data Science (ML & AI) Serie:
- AI im Fußball: Entwicklung eines Expected Goals Modells
- Einführung in Deep Learning und PyTorch
- NLP zur Analyse von E-Mails
- Entwicklung eines Machine Learning Modells auf Azure
- Architektur und Funktionsweise von neuronalen Netzen
- Entwicklung eines neuronalen Netzes zur Prädiktion von Airbnb-Preisen
- Architektur und Funktionsweise von baumartigen Regressionsverfahren
- Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
- Was sind Large Language Modelle
- Das Large Language Model GPT-4
- Prompt Engineering in ChatGPT
- Entwicklung eines Large Language Modells mit LangChain & OpenAI
- Überblick zu Künstlicher Intelligenz, Machine Learning und Deep Learning
- Maschinelles Lernen in Databricks mithilfe von MLlib
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns!
Ihr Ansprechpartner



