
Serie | Data Science (ML & AI) – Einführung in Deep Learning und PyTorch
Die Grundlagen von Deep Learning
Deep Learning ist ein Teilbereich des maschinellen Lernens, welcher von vielen ExpertInnen als die Zukunft dieses Bereichs und künstlicher Intelligenz allgemein angesehen wird. Maßgebliche Durchbrüche in der Forschung basieren auf Deep Learning Architekturen, wie bspw. Google’s „Alphafold 2“, welches eines der größten Probleme und Fragestellungen in der biologischen Forschung „um Jahre beschleunigen könnte“. Doch auch in der Wirtschaft findet Deep Learning viele Anwendungen, wie bpsw. in der Prognose von Absätzen, dem Erlernen von Zusammenhängen in Daten oder in der effizienteren Datenrepräsentation.
Deep Learning basiert dabei auf sogenannten künstlichen neuronalen Netzen, welche dem menschlichen Gehirn nachempfunden sind. Es unterscheidet sich zum traditionellen maschinellem Lernen vor allem dadurch, dass die „Features“, welche entscheidend für den Lernprozess eines Algorithmus sind, hierbei nicht von vornherein von außen festgelegt werden müssen, sondern „automatisch“ vom neuronalen Netz gelernt werden können. Dabei ist ein neuronales Netz im Prinzip in der Lage jede mögliche mathematische Funktion zu approximieren und damit jedes mögliche den Daten zugrunde liegende Modell.
Im Folgenden werden einige wichtige Grundbegriffe erläutert.
Neuron/Perceptron
Diese bilden die Basiseinheit eines neuronalen Netzes. Sie erhalten als Input die Daten oder einen Teil der Daten. Dabei enthalten die Neuronen selber bestimmte Parameter, die „Weights“ bzw. „Weight-Matrix“ und jeweils einen „bias“ Parameter. Diese Parameter verändern den Input durch eine mathematische Operation (z.B. Matrix-Multiplikation oder das „Dot-Product“ bei einer anderen Architektur, der Convolution). Diese Parameter können in den Durchläufen verbessert werden und sich anpassen; so „lernt“ das Neuronale Netz. Nach der mathematischen Operation enthält jedes Neuron eine sogenannte „activation function“, welche auf das Ergebnis der mathematischen Operation angewendet wird. Diese Funktion ist nicht-linear, was den Kern der Vielfältigkeit von Neuronalen Netzen ausmacht, da so prinzipiell alle möglichen Funktionen abgebildet werden können.
Layer
Ein Layer ist eine „Schicht“ des Neuronalen Netzes und besteht daher meist aus mehreren Neuronen. Die grundlegende Struktur lässt sich schematisch wie folgt darstellen:
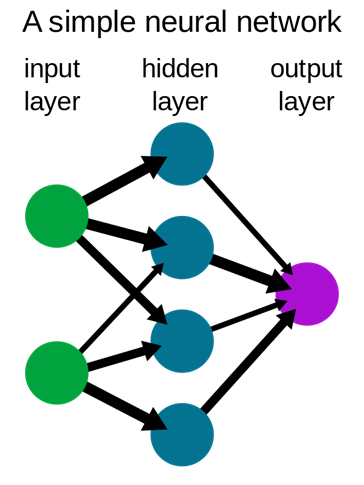
Dabei werden die Layer, welche zwischen dem Input und Output liegen häufig als Hidden Layer bezeichnet, da diese in der Ausführung des Algorithmus nicht gesehen werden.
Forward Propagation
Dabei handelt es sich um den Durchlauf der Daten und den daraus resultierenden Output des Neuronalen Netzes. Wie bereits im Perceptron Teil angesprochen, werden im einfachsten Fall, dem Fully-Connected Network, die Daten mit den Gewichten des ersten Layers multipliziert und ein Bias wird addiert. Auf das Ergebnis wird die “activation function” angewendet und der resultierende Output wird an den nächsten Layer übergeben. Dieser Prozess kann so lange weiter erfolgen, bis die Daten zum letzten Layer, dem Output-Layer gelangen. Dieser kann bspw. Wahrscheinlichkeiten für Klassifizierungen ausgeben, wobei ein Neuron des Output-Layers eine Klasse repräsentiert. Eine andere Möglichkeit wäre die Daten in der gleichen Dimensionalität wie den Input ausgeben zu lassen, bspw. bei Bildern.
Backward Propagation
Die Backpropagation erfolgt nach der Forward Propagation. Hierbei wird der Output verwendet und in eine sogenannte “loss function” gegeben, welche bspw. im überwachten Lernen die Klassifizierungen mit den tatsächlichen Klassen aus den Daten vergleicht und einen Fehler berechnet. Basierend auf einer mathematischen Regel (Chain Rule) kann nun der „Fehler“ des neuronalen Netzes Layer für Layer zurückverfolgt werden. An jedem Neuron wird der Gradient berechnet, welcher die Richtung des steilsten Anstiegs angibt. Geht man nun in die entgegengesetzte Richtung, verändert also die Gewichte des Neurons dahingehend, dass man einen gewissen Teil des Gradienten abzieht, verändern sich diese, sodass sich der gesamte Fehler des Neuronalen Netzes minimiert. Dieser Prozess ist rekursiv und kann Layer für Layer bis zum ersten Layer zurückverfolgt werden. Hierbei gibt es viele Möglichkeiten, wie genau der Gradient an den Gewichten abgezogen wird.
Epoche
Eine Epoche ist dabei der Durchlauf einer Forward und einer Backward Propagation hintereinander. Die Anzahl der Epochen stellt dabei einen Hyperparameter (also nicht lernbaren) Parameter dar. Im Training muss daher von außen bestimmt werden, wie viele Epochen das neuronale Netz trainiert werden soll.
Optimierungen
Es gibt verschiedene Optimierungsalgorithmen, welche alle dafür bestimmt sind, basierend auf den Gradienten, welche durch die Backpropagation berechnet wurden, die Gewichte dahingehend zu verändern, dass der gesamte „Fehler“ des neuronalen Netzes, also die Loss Funktion sinkt. Der einfachste Ansatz ist dabei den erhaltenen Gradienten mit einem kleinen Faktor, der Learning Rate, zu multiplizieren und dann von den Gewichten abzuziehen (siehe Stochastic Gradient Descent). Es existieren allerdings ausgeklügeltere Verfahren, welche zu einer schnelleren Konvergenz zu einem lokalen Minimum der Loss Funktion führen (Generell werden immer nur lokale Minima gefunden, da die Berechnung für globale Minima zu aufwändig oder in vielen Funktionen nicht exakt möglich ist). Vor allem SGD + Momentum, Nestorov Momentum, Adagrad und RMSProp sind hier zu nennen. Der aktuell erfolgreichste Optimierungsalgorithmus, welcher in der Regel zu den besten Ergebnissen führt, ist der ADAM Optimierungsalgorithmus.
Batching
Ein weiterer Aspekt, welcher in folgenden Artikeln noch genauer erläutert werden kann, ist das sogenannte Batching. Hierbei wird in jeder Iteration im Training eine Teilmenge des gesamten Datensatzes verwendet und “auf einmal” verarbeitet, anstatt die gesamte Trainingsepoche, also forward + backward propagation, für jedes Objekt des Datensatzes einzeln durchlaufen zu lassen. Dies verkürzt nicht nur die Trainingsdauer, sondern sorgt auch für weniger Varianz im Trainingsloss über die jeweilgen Epochen, da die Gradienten somit nicht objektweise, sondern batchweise berechnet werden und daher ein Durchschnitt gebildet werden kann.
Deep Learning Anwendungen
Wie bereits im einführenden Paragraphen des Posts erläutert, gibt es unzählige Anwendungen von Deep Learning Verfahren. Am häufigsten werden diese auf spezielle Datentypen angewandt, welche mit anderen Verfahren kaum verarbeitet werden können. Dazu gehören vor allem Bild- und Text-, sowie Audio- und Videodaten. Beispielsweise existieren in der Objekterkennung und –segmentierung spezialisierte Deep Learning Architekturen, die sogenannten “Convolutional Neural Networks”. Ein Anwendungsbeispiel für Text- oder Audiodaten ist die automatische Sprachverarbeitung, welche z.B. für einen verbesserten Kundenservice verwendet werden kann.
Auch für die Daten-/Informationskomprimierung, also das effizientere Abbilden von relevanten Informationen und Features aus Daten können spezielle Deep Learning Architekturen verwendet werden, die sogenannten Autoencoder (was in zukünftigen Posts genauer erläutert werden wird). Doch auch für “klassischere” Anwendungen, wie Prognosen, Zeitreihenanalysen und Regressionen existieren ausgeklügelte Deep Learning Verfahren, welche alle bisherigen Ansätze outperformen. Hier sind vor allem sogenannte “Recurrent Neural Networks” (RNNs), sowie “Transformer” zu nennen.
Des Weiteren ist es möglich neuronale Netze auf Daten zu trainieren, welche dann in der Lage sind eigenständig neue Daten zu erzeugen. So kann ein neuronales Netz z.B. bedingt auf einen “Wunsch” oder ein “Ziel”, welches der Anwender vorgibt, neue Daten als Vorschläge erzeugen. Dies können z.B. neue Bilddateien basierend auf diesen Vorgaben sein, neue Videos, neue Audiodateien und generell jede Art von Daten auf die trainiert wird.
Einführendes Beispiel in Pytorch – Klassifizierung von Bilddaten
Im zugehörigen Jupyter Notebook wird die Pytorch Bibliothek vorgestellt. Hierbei handelt es sich um eine Python Bibliothek, welche sich zum Erstellen von neuronalen Netzen und dem Training dieser sehr gut eignet.
Ihr möchtet mehr über die Möglichkeiten von Deep Learning erfahren? Dann nichts wie ab zu unserem Data Strategy & Analytics Assessment!
Übersicht der Data Science (ML & AI) Serie:
- AI im Fußball: Entwicklung eines Expected Goals Modells
- Einführung in Deep Learning und PyTorch
- NLP zur Analyse von E-Mails
- Entwicklung eines Machine Learning Modells auf Azure
- Architektur und Funktionsweise von neuronalen Netzen
- Entwicklung eines neuronalen Netzes zur Prädiktion von Airbnb-Preisen
- Architektur und Funktionsweise von baumartigen Regressionsverfahren
- Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
- Was sind Large Language Modelle
- Das Large Language Model GPT-4
- Prompt Engineering in ChatGPT
- Entwicklung eines Large Language Modells mit LangChain & OpenAI
- Überblick zu Künstlicher Intelligenz, Machine Learning und Deep Learning
- Maschinelles Lernen in Databricks mithilfe von MLlib
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns gerne.
Ihr Ansprechpartner



