
Serie | Data Science (ML & AI) – Natural Language Processing zur Analyse von E-Mails
Was ist Natural Language Processing?
Natural Language Processing kombiniert Informatik, Linguistik und künstliche Intelligenz zur Verarbeitung natürlicher Sprache durch Computer. Dadurch können Computer menschliche Sprache in Form von Schall oder Zeichenketten erfassen, verstehen und generieren.
Dieser Impuls beschäftigt sich mit der Analyse von E-Mails mithilfe verschiedener Methoden des Natural Language Processings. Dazu werden die E-Mails zunächst mit Python geladen und in ihre einzelnen Bestandteile zerlegt. Nach der Bereinigung der Texte können dann die NLP-Methoden zur Auswertung der E-Mails angewendet werden.
Extraktion der Informationen zu den E-Mails?
Das Ziel beim Einlesen und Zerlegen der E-Mails besteht darin, eine Tabelle mit den wesentlichen Informationen zu jeder E-Mail zu erstellen. Microsoft Outlook verwendet als Dateiformat PST zur Speicherung von E-Mails, Terminen oder Aufgaben. Zum Einlesen der PST-Dateien in Python kann die Bibliothek Pypff genutzt werden, welche die Informationen der E-Mails als HTML-Texte darstellt. Der Inhalt der E-Mails kann aus den HTML-Texten extrahiert und mit Beautiful Soup in lesbare Texte umgewandelt werden. Zudem ist es einfach mithilfe von Pypff, den Betreff, Sender und das Datum jeder E-Mail herauszufinden. Die Empfänger der E-Mails können aus dem HTML-Text extrahiert und in CC- bzw. BCC-Empfänger unterschieden werden. Die Inhalte und Namen der angehängten Dateien sind ebenfalls im HTML-Text enthalten.
Der HTML-Text zu jeder E-Mail beinhaltet auch den gesamten Verlauf. Um eine Dopplung der E-Mails aus dem Sendeverlauf zu vermeiden, wird nur die aktuelle E-Mail atomar in der Tabelle abgespeichert. Durch einen Verweis auf die ID der vorherigen E-Mail im Verlauf ist es möglich, die Konversation bei Bedarf wiederherzustellen.
Bereinigung der Inhalte von E-Mails
Vor der Anwendung von NLP-Methoden ist es hilfreich, alle Wörter in den Texten der E-Mails in die jeweilige Grundform zu bringen. So würde beispielsweise aus dem Wort „angenommen“ die Grundform „annehmen“. Dadurch kann bei einer Volltextsuche nach der Grundform eines Wortes gesucht und sichergestellt werden, dass alle Wörter, die zu dieser Grundform gehören, auch gefunden werden. Außerdem erscheinen die Wörter auf diese Weise bei Wordclouds oder anderen NLP-Techniken nicht mehrfach in verschiedensten Formen, was die Häufigkeit des Auftretens bestimmter Wörter teilweise deutlich verzerren würde. Bei den meisten NLP-Techniken ist es auch nützlich, die Satzzeichen, Sonderzeichen und Ziffern aus den Texten zu entfernen sowie alle Buchstaben in Kleinbuchstaben umzuwandeln.
Zur Analyse von E-Mails soll zusätzlich das Impressum extrahiert und vom Inhalt der E-Mail separat abgespeichert werden, da das Impressum in der Regel keinen Mehrwert bei der Auswertung der E-Mails liefert und die Ergebnisse negativ beeinträchtigen kann. Die einfachste Möglichkeit zur Trennung des Impressums vom Text der E-Mail stellt die Suche nach Schlagwörtern wie „Mit freundlichen Grüßen“ oder „Besten Gruß“ dar, um den Beginn der Signatur zu identifizieren. Allerdings beginnt nicht jedes Impressum mit einer solchen Grußformel und teilweise können übliche Grußformeln auch im E-Mail-Text vorkommen, sodass in diesem Fall der nachfolgende Teil des Textes als Impressum erkannt und abgeschnitten würde.
Daher besteht ein besserer Ansatz darin, ein Machine Learning Modell zur Erkennung der Signatur zu entwickeln. Hierzu wird ein Datensatz von E-Mails benötigt, für die der Beginn der Signatur manuell vorgegeben wurde. Auf Basis diese Datensatz kann das ML-Modell darauf trainiert werden, jede Zeile einer E-Mail als Teil des Textes oder der Signatur zu klassifizieren. Mögliche Features sind die Grußformeln, verschiedene Satzzeichen sowie die Anzahl an Zeichen und Wörtern in einer Zeile. Wenn das Modell dann in einer E-Mail vier aufeinander folgende Zeilen als Signatur klassifiziert, kann die erste dieser vier Zeilen als Beginn der Signatur definiert werden.
Spracherkennung
Wenn die E-Mails in unterschiedlichen Sprachen verfasst wurden, muss zunächst die Sprache jeder E-Mail erkannt und abgespeichert werden. Denn einige NLP-Techniken, wie die Sentimentanalyse, können nur auf einer einheitlichen Sprache durchgeführt werden oder benötigen die Sprache des Textes als Input-Parameter. Durch die Spracherkennung können diese NLP-Techniken beispielsweise auf den E-Mails, die in der am häufigsten verwendeten Sprache geschrieben sind, oder für verschiedene Sprachen einzeln ausgeführt werden. Mithilfe der Python-Bibliothek Langdetect kann die Sprache von Texten erkannt werden.
Anwendung der NLP-Methoden
Nach der Extraktion und Bereinigung der E-Mails können nun NLP-Techniken eingesetzt werden.
E-Mail-Flussdiagramm
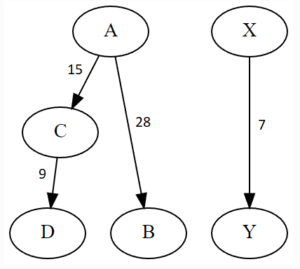
Ein Flussdiagramm zeigt, wie häufig eine bestimmte Person eine E-Mail an eine andere Person verschickt hat. Dazu wird ein Graph erzeugt mit Knoten zur Repräsentation der Personen und Pfeilen zwischen den Personen, deren Richtung den Fluss der E-Mails und deren Dicke oder Beschriftung die Häufigkeit angibt. Dies hilft dabei, einen Überblick über den Kommunikationsfluss und die Häufigkeit der Kommunikation zu erhalten. Durch die Darstellung der E-Mails einer Organisation in einem Flussdiagramm können die internen Prozesse und Kommunikationswege leicht verstanden werden. Da in einem großen Unternehmen mehrere Tausend E-Mails verschickt werden, lohnt es sich, die E-Mails zur Übersichtlichkeit auf einen Fachbereich, Personenkreis oder Zeitabschnitt einzugrenzen. In Python können solche Flussdiagramme mit der Bibliothek Graphviz dargestellt werden.
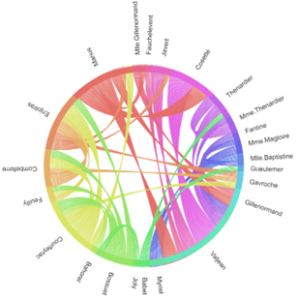
Chord-Diagramm
Das Chord-Diagramm bieten ebenfalls eine Übersicht, zwischen welchen Parteien und in welchem Umfang die Kommunikation stattgefunden hat. Im Vergleich zum Flussdiagramm liefert es eine gröbere Sicht auf das Gesamtbild, sodass zur Generierung des Chord-Diagramms ein größerer Datensatz verwendet werden kann. Eine Möglichkeit zur Visualisierung von Chord-Diagrammen in Python liefert die Bibliothek Bokeh.
Sentimentanalyse
Die Sentimentanalyse dient der Auswertung eines Stimmungsbildes mithilfe von Texten und Bildern. Bei der Analyse von E-Mails eines Unternehmens kann so die Stimmung innerhalb der Organisation ermittelt werden. Zudem sind Anzeichen für Krisen oder Konflikte im Unternehmen in der Sentimentanalyse erkennbar. Die Sentimentanalyse weist jeder E-Mail einen Wert für die Subjektivität zwischen 0 und 1 und für die die Polarität zwischen -1 und 1 zu. Die Subjektivität gibt an, ob es sich beim Inhalt der E-Mail um objektive Fakten oder eine subjektive Meinung handelt. Die Polarität beschreibt die Negativität oder Positivität des Geschriebenen. Durch die Visualisierung der Polarität im zeitlichen Verlauf kann die Entwicklung der Stimmung veranschaulicht werden und es wird erkennbar, welche Zeiträume eine besonders aggressive oder euphorische Stimmung aufweisen und daher genauer betrachtet werden sollten.
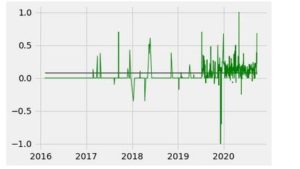
Entwicklung der Polarität im zeitlichen Verlauf
Wordclouds
Wordclouds stellen auf einen Blick die am meisten verwendeten Wörter in einer definierten Auswahl von E-Mails dar. Dabei ist es sinnvoll, die E-Mails zur Generierung einer Wordcloud auf eine einzelne Abteilung oder einen bestimmten Kunden einzugrenzen. Dabei sollten die Texte entsprechend bereinigt und Stoppwörter, wie Artikel oder Präpositionen, sowie Satzzeichen und Ziffern entfernt werden. Zudem ist es sinnvoll, die Wörter in ihre Grundform und Großbuchstaben in Kleinbuchstaben umzuwandeln. Eine weitere Möglichkeit besteht darin, die Wordcloud ausschließlich auf Basis der Betreffzeile von E-Mails zu generieren.

Topic Modeling
Topic Modeling ist eine NLP-Methode zur Aufdeckung von Themen innerhalb von Dokumenten. Dadurch ist es möglich, ähnliche E-Mails in verschiedene Themengebiete zu gruppieren. Die bekannteste Methode zum Topic Modeling ist die latente Dirichlet-Allokation (LDA). Die Anzahl der zu erkennenden Themen muss hierbei vom Nutzer vorgegeben werden. Dann geht der LDA-Algorithmus die einzelnen E-Mails durch und weist jedes Wort einem zufälligen Thema zu. LDA ordnet alle E-Mails den Themen so zu, dass die Wörter in jeder E-Mail größtenteils von diesen imaginären Themen erfasst werden. Anschließend ordnet der Algorithmus iterativ jedes Wort erneut einem Thema zu, wobei die Häufigkeit des Auftretens vom Thema in der E-Mail und die Häufigkeit vom Auftreten des Wortes in dem Thema berücksichtigt werden. Diese Wahrscheinlichkeiten werden mehrmals berechnet, bis der Algorithmus konvergiert. Nach Abschluss des Algorithmus liefert LDA zu jedem Thema eine Liste von Schlüsselwörtern, die zur Interpretation der Themen genutzt werden können. Im Gegensatz zum harten Clustering, wie zum Beispiel bei K-Means, ordnet LDA jede E-Mail einer Mischung von Themen zu, sodass eine E-Mail beispielsweise zu 70% von Thema A, zu 20% von Thema B und zu 10% von Thema E beschrieben werden kann.
Ähnlichkeitsanalyse von Texten
Im Gegensatz zum Menschen ist es für den Computer nicht so einfach zu erkennen, welche Sätze sich ähnlich sind und welche nicht. Ein Ansatz ist das Umwandeln von Texten in Vektoren. So kann für eine Sammlung von E-Mails ein „Bag of Words“ erstellt werden, welcher eine Matrix mit den einzelnen E-Mails als Zeilen und allen vorkommenden Wörtern als Spalten darstellt. Die Zahlen innerhalb der Matrix beschreiben dann, wie häufig das entsprechende Wort in der jeweiligen E-Mail vorkommt. Anschließend kann die Kosinus-Ähnlichkeit zwischen zwei Vektoren bestimmt werden, sodass die Ähnlichkeit jeder Kombination von zwei E-Mails ermittelt werden kann.
Fazit zu NLP
Bei der Analyse von E-Mails gibt es zahlreiche Möglichkeiten zum Einsatz von NLP-Techniken. Dabei können die Kommunikationswege sowie die Stimmung innerhalb einer Organisation oder einzelner Abteilung ausgewertet werden. Zudem können die E-Mails in verschiedene Themengebiete eingeteilt werden, um einen schnellen Überblick zu erhalten und die relevanten E-Mails zu gruppieren.
Sie möchten mehr über die Möglichkeiten von Data Science erfahren? Dann nichts wie ab zu unserem Data Strategy & Analytics Assessment!
Übersicht der Data Science (ML & AI) Serie:
- AI im Fußball: Entwicklung eines Expected Goals Modells
- Einführung in Deep Learning und PyTorch
- NLP zur Analyse von E-Mails
- Entwicklung eines Machine Learning Modells auf Azure
- Architektur und Funktionsweise von neuronalen Netzen
- Entwicklung eines neuronalen Netzes zur Prädiktion von Airbnb-Preisen
- Architektur und Funktionsweise von baumartigen Regressionsverfahren
- Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
- Was sind Large Language Modelle
- Das Large Language Model GPT-4
- Prompt Engineering in ChatGPT
- Entwicklung eines Large Language Modells mit LangChain & OpenAI
- Überblick zu Künstlicher Intelligenz, Machine Learning und Deep Learning
- Maschinelles Lernen in Databricks mithilfe von MLlib
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns!
Ihr Ansprechpartner



