Serie | Data Integration (Migration & ETL) – Einführung & Anwendungsbeispiel in Databricks
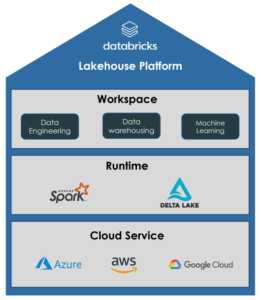
Databricks ist eine Multi-Cloud Lakehouse Plattform basierend auf Apache Spark, welche den gesamten Prozess der Datenverarbeitung abdeckt: Data Engineering, Data Science und Machine Learning.
Databricks wird auf den größten Cloud-Plattformen Microsoft Azure, Google Cloud und Amazon AWS angeboten. Die Databricks Umgebung übernimmt dabei die Verwaltung von Spark Clustern und bietet interaktive Notebooks zur Verarbeitung, Analyse und Visualisierung von Daten in mehreren Programmiersprachen. Die Aufsetzung und Steuerung von Jobs und Pipelines ermöglichen zudem die Automatisierung der Datenverarbeitung.
Apache Spark
Durch den Einsatz von Apache Spark als Framework zur Datenverarbeitung eignet sich Databricks zur Analyse von Big Data und Entwicklung von Machine Learning Modellen, da Spark Cluster mit einer Vielzahl an Servern zur Datenverarbeitung nutzt, welche durch Skalierung eine fast unbeschränkte Rechenleistung bieten. Spark bietet zudem eine Schnittstelle zur Programmierung in verschiedenen Sprachen, wie Java, Scala, Python, R oder SQL.
Delta Lake
Delta Lake ist eine Open-Source Speicherschicht, die für die Verwaltung von Big Data in Data Lakes entwickelt wurde. Delta Lakes erhöhen die Zuverlässigkeit von Data Lakes, indem sie die Datenqualität und Datenkonsistenz von Big Data steigern und Funktionen aus traditionellen Data Warehouses hinzufügen. Delta Lakes unterstützen ACID-Transaktionen, skalierbare Metadaten und Time Traveling durch das Logging aller Transaktionen. Zudem sind Delta Lakes Spark kompatibel und nutzen standardisierte Datenformate, wie Parquet und Json.
Dadurch ermöglichen Delta Lakes die Bildung von einem Lakehouse, welches die Vorteile von Data Lakes und Data Warehouses kombiniert.

MLflow
MLflow ist eine Open-Source-Plattform zur Verwaltung des gesamten Machine-Learning-Lebenszyklus. Es wurde entwickelt, um den Prozess des Trainings, der Verwaltung und der Bereitstellung von Machine-Learning-Modellen zu vereinfachen. MLflow ermöglicht das Protokollieren und Verfolgen von Machine Learning Experimenten während des Modelltrainings und die einfache Bereitstellung von trainierten Modellen als Docker-Container, Python-Funktionen und RESTful API-Endpunkte. MLflow ist kompatibel mit verschiedenen Machine-Learning-Frameworks wie TensorFlow, PyTorch, Scikit-Learn und XGBoost. Es kann unter anderem in Jupyter Notebooks, Apache Spark, Databricks und AWS SageMaker genutzt werden.
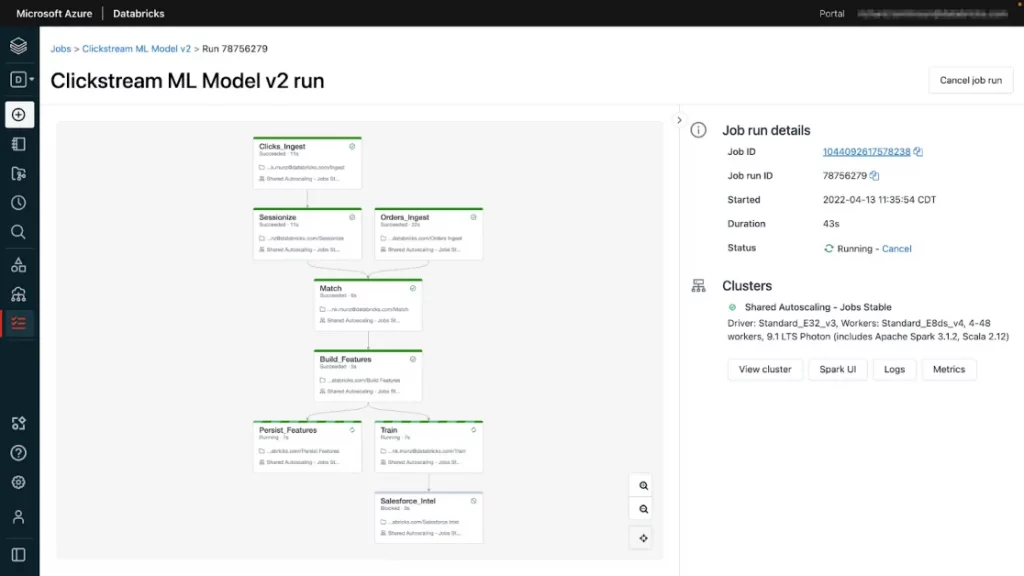
Worksflows
Databricks Workflows dienen zur Orchestrierung mehrerer Aufgaben, welche als ETL-, Analytics- oder ML-Pipelines definiert, verwaltet und überwacht werden können. Die einzelnen Aufgaben innerhalb eines Workflows können Databricks Notebooks, SQL-Abfragen oder Delta Live Table Pipelines ausführen. Durch die Festlegung vordefinierter Zeiten oder Trigger zur Ausführung von Batch-Jobs können wiederkehrende Aufgaben automatisiert werden und die Implementation von Echtzeit-Datenpipelines ermöglichen die kontinuierliche Ausführung von Streaming-Jobs. Die Nutzung eines Job-Clusters reduziert die Rechenkosten, da diese nur dann ausgeführt werden, wenn ein Workflow geplant ist. Der Databricks Arbeitsbereich bietet eine vollständige Übersicht zu den ausgeführten Workflows und optionale Benachrichtigungen per E-Mail, Slack oder Webhooks.
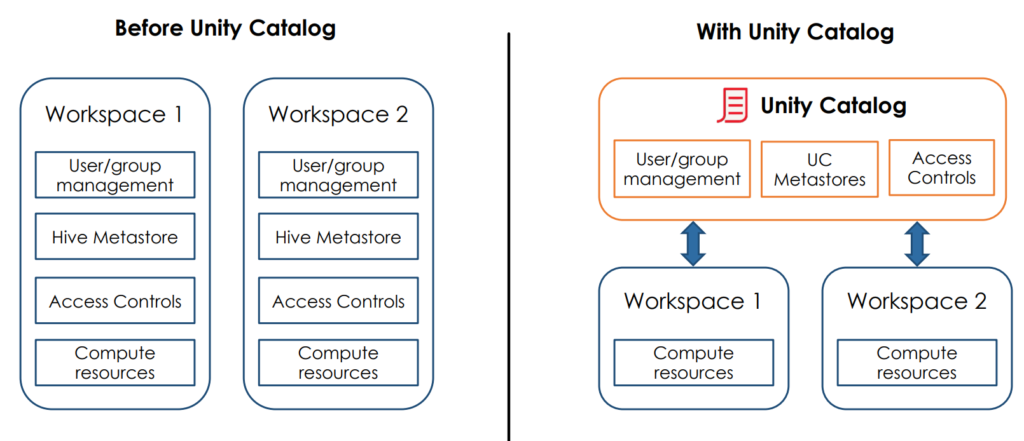
Unity Catalog
Unity Catalog bietet eine einheitliche Governance-Lösung für Daten und KI-Ressourcen in Databricks. Dazu gehören zentralisierte Funktionen zur Zugriffssteuerung, Überwachung und Herkunftsermittlung von Daten in Databricks Umgebungen. Mit Unity Catalog können die Datenzugriffsrichtlinien zentral definiert werden, sodass diese für alle Arbeitsbereiche gelten. Unity Catalog bietet auch eine Schnittstelle zur Suche nach Datenobjekten und erfasst Herkunftsdaten, um nachzuverfolgen, wie Datenressourcen erstellt und verwendet werden.
Anwendungsbeispiel: Analyse von Daten aus dem Online-Einzelhandel
Jeder Databricks Arbeitsbereich verfügt über ein verteiltes Dateisystem, welches auf Databricks Clustern vorinstalliert ist. Dieses Databricks File System (DBFS) bietet eine Abstraktionsschicht zur Speicherung der Daten in darunter liegenden Cloud-Speicher. Dadurch können Objekte aus dem Cloud-Speicher mit relativen Pfaden in der Semantik eines Dateisystems angesprochen werden, ohne dass die Cloud-spezifischen API-Befehle benötigt werden. Zudem enthält das DBFS einige Testdatensätze, wie zum Beispiel einen Datensatz mit Verkaufsdaten aus dem Online-Einzelhandel.
Mithilfe des Magic-Befehls %fs kann auf das DBFS zugegriffen werden, um sich die verfügbaren Dateien anzeigen zu lassen.

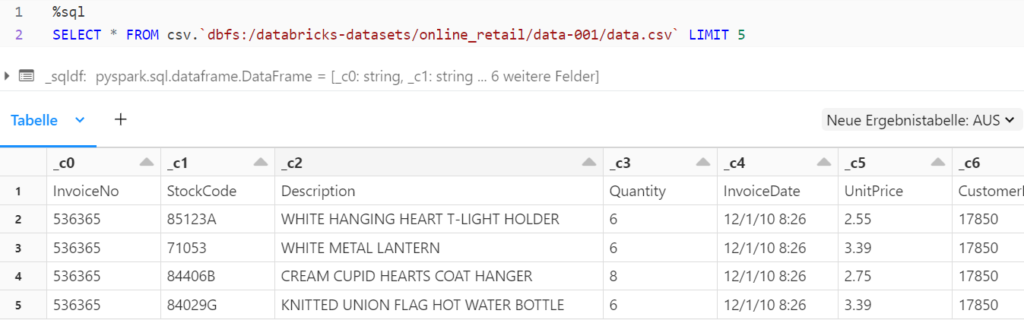
Durch eine SQL-Abfrage können die Daten einer Datei ausgelesen werden. Zur Anzeige der Rohdaten direkt aus der Datei dient folgender SQL-Befehl:
SELECT * FROM dateiformat.`dateipfad`
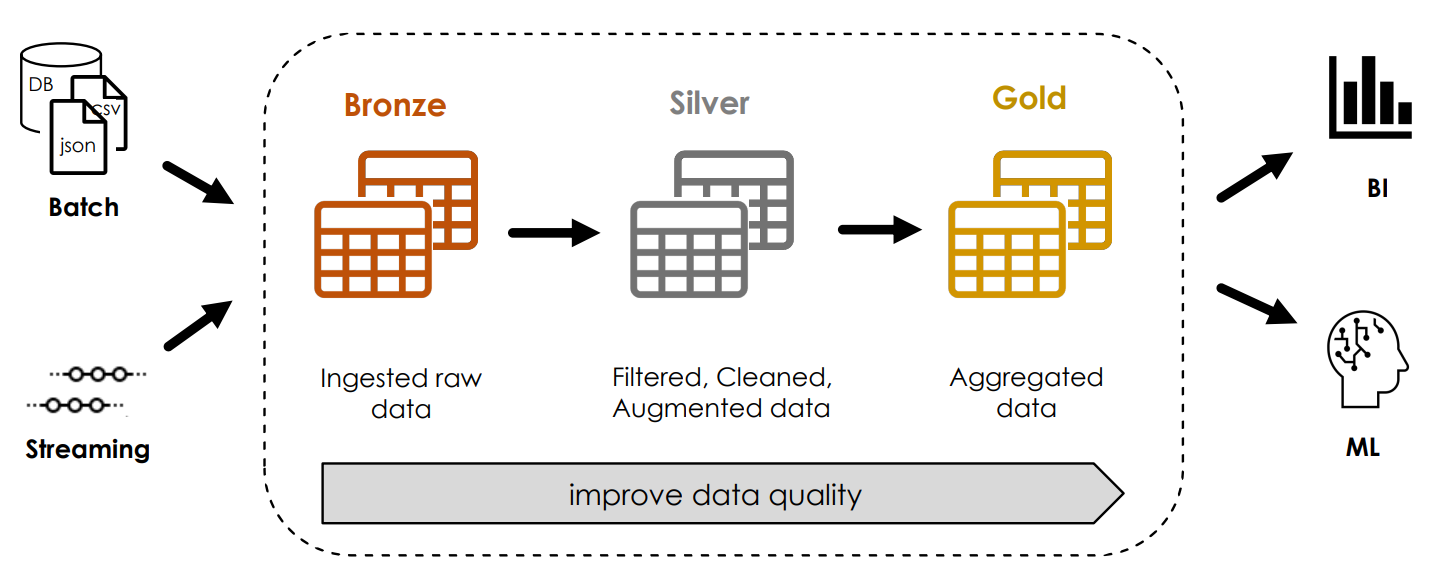
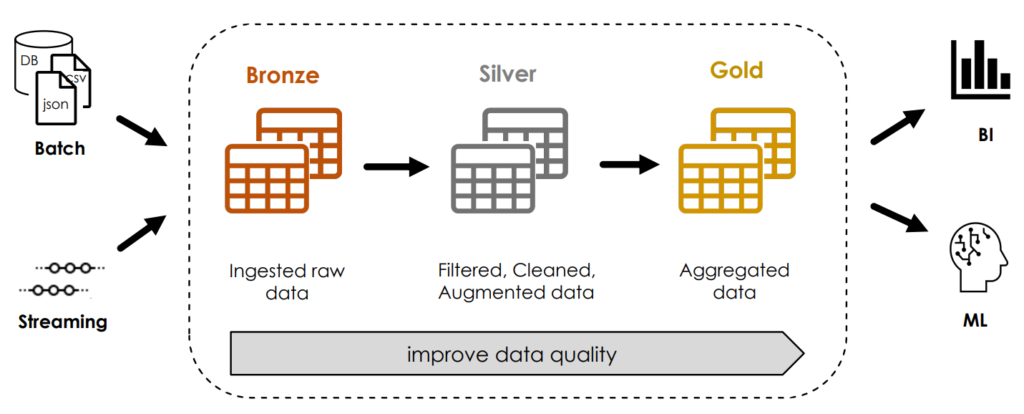
Aufbau einer Multi-hop Architektur
Bei einer Multi-hop Architektur, welche auch als Medallion-Architektur bezeichnet wird, werden die Struktur und Qualität der Daten inkrementell verbessert. Dazu wird zunächst eine Bronze-Tabelle mit den Rohdaten erzeugt, sodass eine Neuverarbeitung der Originaldaten jederzeit möglich ist, ohne die Daten erneut aus dem Quellsystem lesen zu müssen. Die Silber-Tabelle enthält dann die bereinigten Daten, auf deren Basis schließlich mehrere Gold-Tabellen mit aggregierten Daten zum Machine Learning oder Business Intelligence erstellt werden können.
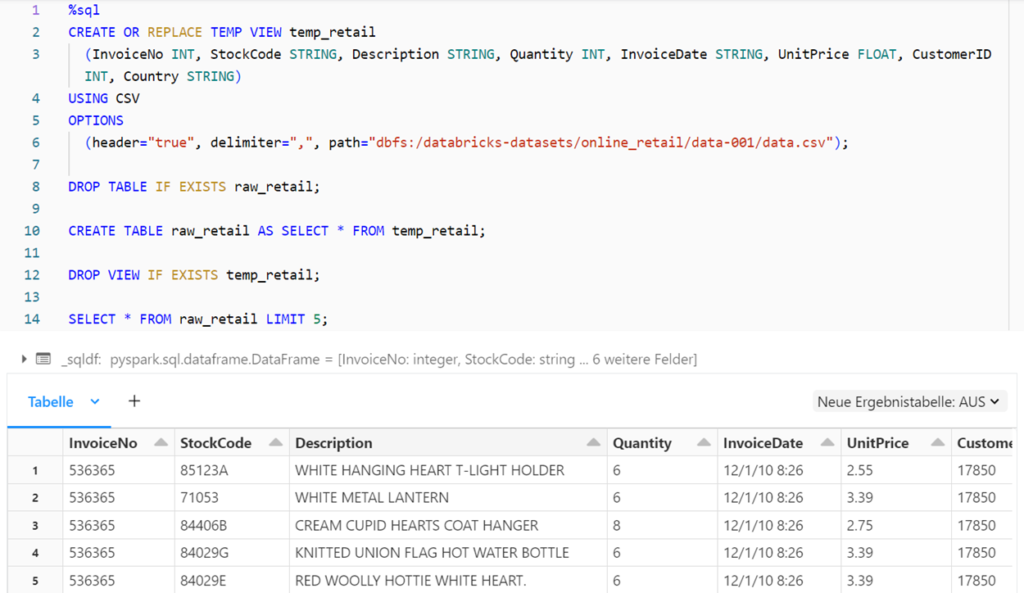
Bei der obigen Methode zum Lesen der Rohdaten (SELECT * FROM dateiformat.`dateipfad`) wird das Schema der Tabelle automatisch erschlossen und es gibt keine Möglichkeit, weitere Dateioptionen anzugeben. Zur Erstellung einer Delta-Tabelle mit einem definierten Schema und der Spezifizierung von Dateioptionen wird daher eine temporäre Sicht und darauf basierend eine Tabelle mit dem CTAS-Befehl (CREATE TABLE AS SELECT) erzeugt.
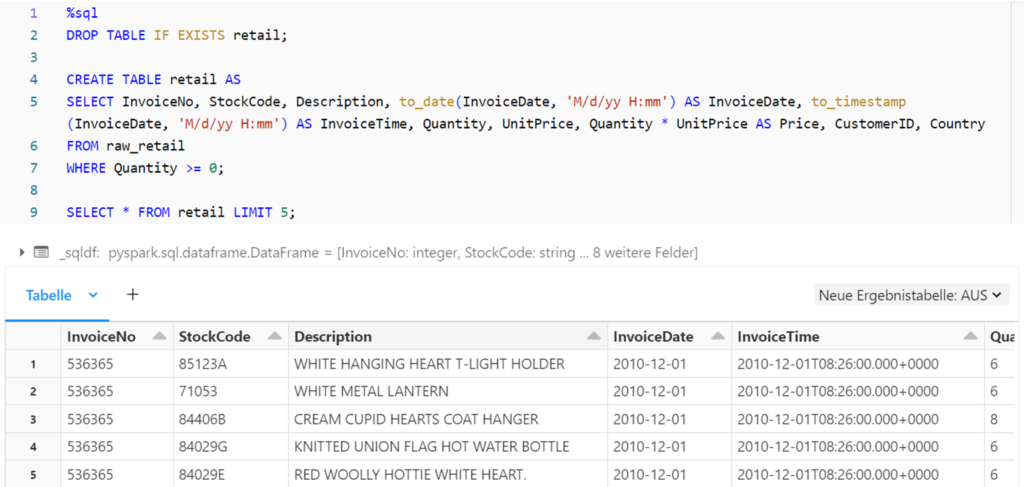
Anschließend wird ausgehend von der Bronze-Tabelle mit dem CTAS-Befehl die Silber-Tabelle generiert. Dabei werden die Datumsangaben formatiert, eine neue Preis-Spalte aus der Multiplikation des Stückpreises mit der Menge erstellt und die Daten gefiltert, sodass nur Zeilen mit einer Verkaufsmenge von mindestens null berücksichtigt werden.
Für die Gold-Schicht wird eine Sicht erstellt, wobei die Daten nach der Rechnungsnummer gruppiert sind und für jede Rechnung der Gesamtpreis ermittelt wird. Zudem wird das Rechnungsdatum aufgeteilt in den Tag sowie die Stunde und Minute der Rechnungsstellung.
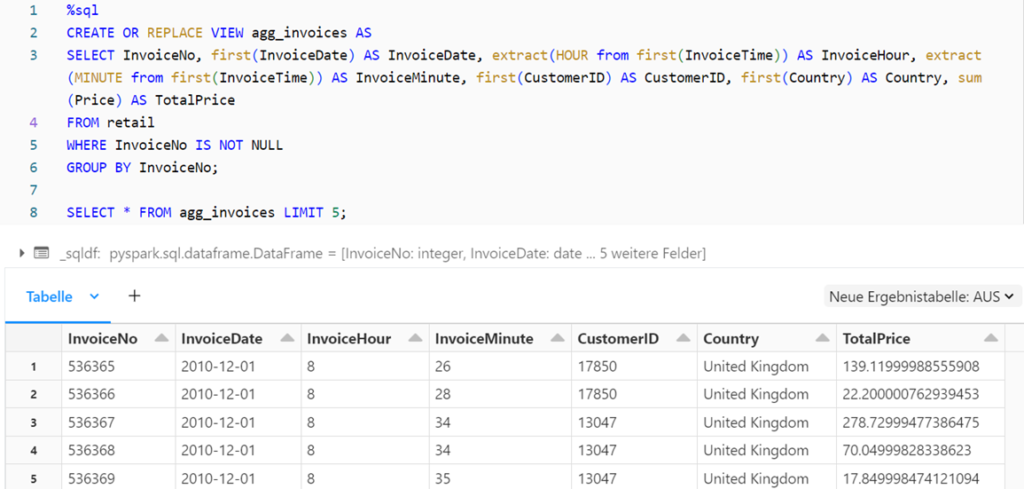
Visualisierung der Daten in Databricks
Die Silber-Tabelle sowie die aggregierten Daten aus der Gold-Schicht können nun zur Analyse und Visualisierung genutzt werden. Databricks Notebooks bieten dazu die Möglichkeit, die Resultat einer SQL-Abfrage mithilfe eines Editors zu visualisieren.
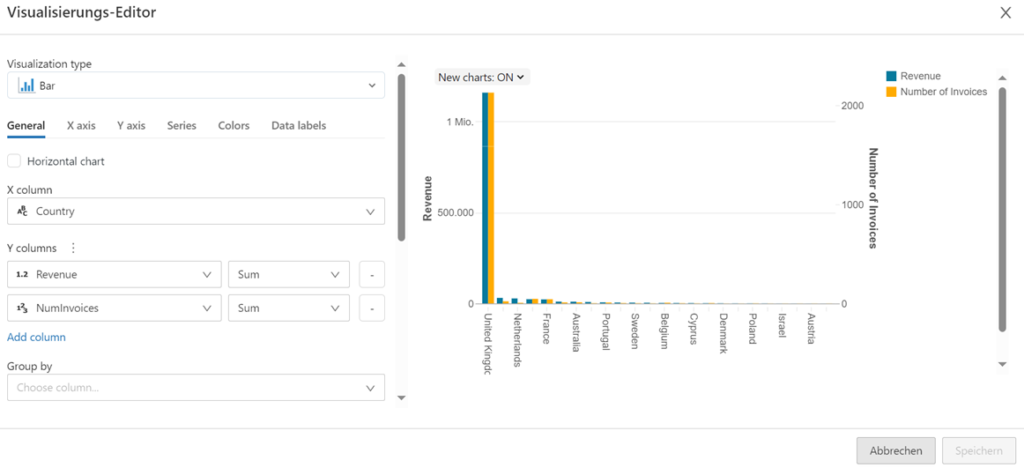
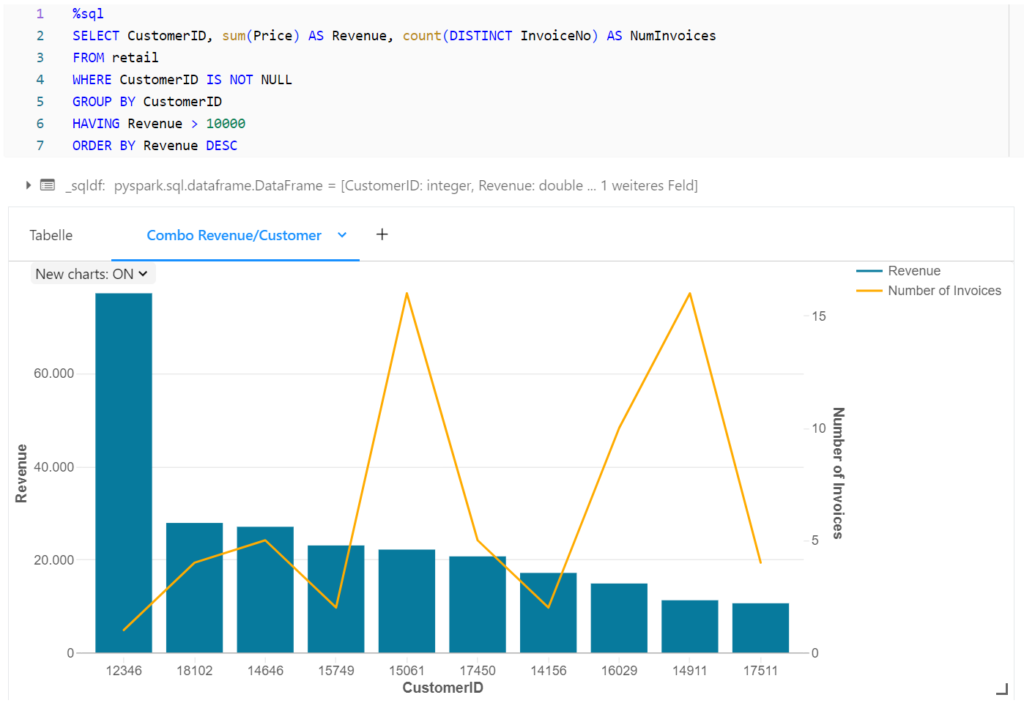
Beispielsweise werden in der nächsten Abbildung die Rechnungen nach Kunden gruppiert, um den Gesamtumsatz und die Anzahl an Rechnungen für die umsatzstärksten Kunden zu visualisieren.
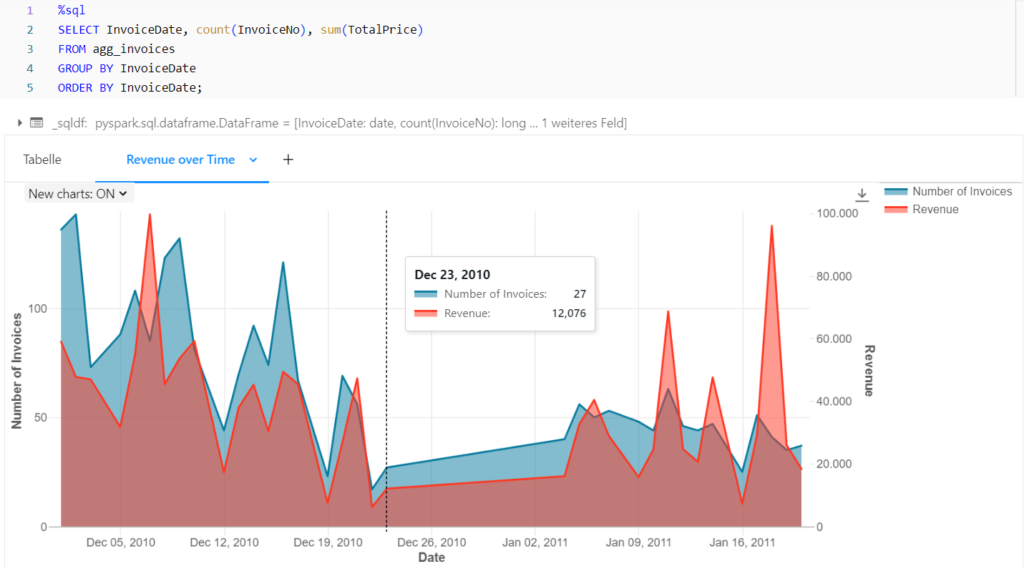
Auf Basis der nach Rechnungen aggregierten Gold-Tabelle, kann auch der Umsatz sowie die Anzahl an Rechnungen pro Tag im zeitlichen Verlauf dargestellt werden.
Fazit Databricks
Databricks eignet sich durch die Nutzung von Spark Clustern und interaktiven Notebooks zur Integration, Verarbeitung, Analyse und Visualisierung großer Datenmengen. Die Lakehouse Architektur ermöglicht den Aufbau eines flexiblen Data Warehouses und mithilfe von MLflow können Machine Learning Modelle in Databricks entwickelt werden. Zudem dienen Workflows zur Orchestrierung und Automatisierung der Datenverarbeitung, während Unity Catalog eine einheitliche Governance-Lösung für Databricks Umgebungen bietet.
Interessiert an Databricks? Schauen Sie sich das Data Strategy & Analytics Assessment oder den Databricks Showcase an.
Übersicht der Data Integration (Migration & ETL) Serie:
- Einführung in Microsoft Azure Data Factory
- Einführung in Azure DevOps
- Schritte zur erfolgreichen Umsetzung eines DevOps-Projekts: Tools, Techniken und Best Practices
- Einführung & Anwendungsbeispiel in Databricks
- Einführung & Anwendungsbeispiele in Microsoft Fabric
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns!
Ihr Ansprechpartner



