
Serie | Database, Data Warehouse & Data Lake – Data Vault Basics
Was ist ein Data Vault?
Um die Frage nach dem Data Vault beantworten zu können, starten wir mit einem kleinen Ausflug in die Grundlagen der Datenbanken.
Data Warehouse Basics
Ein Data Warehouse ist eine zentralisierte Datenbank, welche viele heterogene Datenquellen zusammenführt. Im Gegensatz zum Data Lake Konzept werden die Rohdaten hier allerdings vorverarbeitet, zusammengeführt und homogenisiert, sodass die Extraktion für weitere Analysezwecke einfacher wird, allerdings ein größerer Aufwand als bei einem Data Lake besteht. Dadurch hält ein Data Warehouse einen gewissen Grad an Konsistenz vor. Ein Data Warehouse funktioniert nach dem relationalen Schema und führt Abfragen und Analysen durch. Dabei ist das Data Warehouse stark auf den analytischen Aspekt ausgelegt und unterscheidet sich dadurch von der klassischen Datenbank.
Der Gesamtprozess besteht vor allem aus dem Staging (Beschaffung der Daten), der Datenhaltung und langfristigen Speicherung, der Auswertung und Analyse (OLAP, btw unser Datalytics Logo soll einen OLAP Cube darstellen) und den vorgehaltenen Datenbeständen, welche bspw. den Fachbereichen zur Verfügung gestellt werden (Data Marts). Dabei werden die Daten in den Data Marts häufig als Sternschema oder als Schneeflocken- bzw. Galaxy-Schema abgelegt. Was ist ein Stern- oder Snowflake-Schema? Gut, dass du dir diese Frage stellst!
Stern-Schema
Das Sternschema besteht aus einer Faktentabelle, welche die zentralen Geschäftsidentitäten und somit die Primärschlüssel enthält und mehreren Dimensionstabellen, welche in einer 1:n Beziehung zur Faktentabelle stehen und weitere Attribute enthalten.
Schneeflocken-Schema
Das Schneeflocken-Schema ist dabei die Weiterentwicklung des Sternschemas. Hierbei werden die Dimensionstabellen weiter verfeinert, indem sie klassifiziert oder normalisiert werden. Dadurch kann eine Dimensionstabelle auch nur mit einer weiteren Dimensionstabelle verbunden sein. Dies hat den Vorteil, dass die Daten weniger redundant sind, Abfragen durch die Notwendigkeit von mehreren Joins aber aufwändiger werden können.
Vergleichskriterium |
Star Schema |
Snowflake Schema |
| Einfache Wartung/ Änderung | Hat redundante Daten und ist daher weniger leicht zu warten / zu ändern | Keine Redundanz, sodass Schneeflockenschemata einfacher zu warten und zu ändern sind. |
| Benutzerfreundlichkeit | Geringere Abfragekomplexität und leicht verständlich | Komplexere Abfragen und daher weniger leicht zu verstehen |
| Abfrageleistung | Geringere Anzahl von Fremdschlüsseln und damit kürzere Ausführungszeit für Abfragen (schneller) | Mehr Fremdschlüssel und damit längere Abfrageausführungszeit (langsamer) |
| Art des Datawarehouses | Gut für Datamarts mit einfachen Beziehungen (1: 1 oder 1: viele) | Gut geeignet für den Datawarehouse-Kern zur Vereinfachung komplexer Beziehungen (viele: viele) |
| Maßtabelle | Enthält nur eine Dimensionstabelle für jede Dimension. | Kann für jede Dimension mehr als eine Dimensionstabelle enthalten. |
| Wann zu verwenden | Wenn die Dimensionstabelle weniger Zeilen enthält, können Sie das Sternschema auswählen. | Wenn die Bemaßungstabelle relativ groß ist, ist die Schneeflocke besser, da sie Platz spart. |
| Normalisierung/ Denormalisierung | Sowohl Dimensions- als auch Faktentabellen sind in de-normalisierter Form | Dimensionstabellen sind in normalisierter Form, Faktentabelle ist in nicht normalisierter Form |
| Datenmodell | Top-down-Ansatz | Bottom-up-Ansatz |
Gemeinsamkeiten und Unterschiede zum klassischen Data Warehouse
Beim Data Vault handelt es sich im Wesentlichen um eine spezielle Form eines Data Warehouse. Daher sind die grundlegenden Funktionen gleich. Der Unterschied besteht hierbei im Fokus auf Agilität, was der Anforderung eines „Echtzeit Data Warehouse“ entspricht. Dabei ist das Ziel die 3. Normalform (keine transitiven Abhängigkeiten von Schlüsseln) mit dem bereits genannten Sternschema eines Data Warehouses zu vereinen.
Aufbau des Data Vaults
Dabei werden alle Daten in drei Kategorien erfasst und dementsprechend in drei Kategorien von Datenbanktabellen eingeteilt. Dadurch werden Informationen in unterschiedliche Tabellen abgelegt, sind allerdings weiterhin durch einen Schlüssel verbunden. Die erste Kategorie stellen dabei die „Hubs“ dar. Hier werden die Schlüssel, also die Informationen, die ein Geschäftskonzept eindeutig beschreiben, abgelegt. Ein Hub enthält somit eindeutige Geschäftsschlüssel und dient als Integrationspunkt. Die zweite Kategorie stellen die „Links“ dar, wozu alle Arten von Beziehungen zwischen den Geschäftskonzepten und daher zwischen den Hubs gehören. Dabei kann es sich z.B. um Identitätsbeziehungen oder auch um hierarchische Beziehungen handeln. Somit wird jede Beziehung automatisch als m:n Beziehung abgelegt. Wenn die Kardinalität später geändert wird, muss das Datenmodell daher nicht extra angepasst werden. Die dritte Kategorie, die „Satelliten“, enthalten dabei alle Attribute, die ein Geschäftskonzept oder eine Beziehung beschreiben und können dabei sowohl an Hubs, als auch an Satelliten gehangen werden. Ein Satellit ist dabei immer genau einem Hub oder anderen Satelliten zugeordnet.
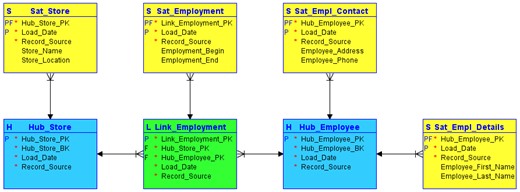
Grundlegende Funktionsweise
Die Satelliten sind dabei für die neben der Agilität relevanteste Eigenschaft des Data Vaults verantwortlich, der sogenannten „unitemporalen Historisierung„. Dabei werden alle zeitlichen Entwicklungen der Daten bei Speicherung in der Datenbank festgehalten. Das Thema der Historisierung eines Data Warehouse kann damit verhältnismäßig einfach umgesetzt werden.
Des Weiteren erlaubt dieses Konzept eine starke Parallelisierung der Beladungsprozesse im Vergleich zum klassischen Data Warehouse, da Hubs und Satelliten beliebig hinzugefügt und entfernt werden können, ohne dass das gesamte Datenmodell von Grund auf erweitert werden muss. Dieser Prozess wird auch als „Insert Only“ bezeichnet. Bei neuen Daten wie bspw. mehr Attributen können einfach weitere Satelliten angefügt werden. Auch die laufende Befüllung der Tabellen kann daher sehr leicht automatisiert werden, da die Befüllung von Links, Hubs und Satelliten nur ein Statement benötigt und nur die Namen bei neuen Tabellen in das Statement eingefügt werden müssen. Daher kann dies mit einer dynamischen SQL Abfrage gewährleistet werden. Da ein Hub nur aus den Schlüsselinformationen besteht, kann er aus jedem System beladen werden und die Beladungen können unabhängig voneinander stattfinden. Die Daten der passenden Satelliten können dann z.B. zu anderen Zeiten oder Zyklen nachgeladen werden.
Die Auswertung eines Data Vaults ist allerdings aufgrund vieler joins nicht empfehlenswert. Stattdessen eignet sich die Darstellung in einem Stern-Schema. Die Transformation in ein Stern-Schema kann über einfache SELECT in SQL geschehen. Hierbei werden die Satelliten und Hubs als Dimensionen verwendet und die Links können als Faktentabelle verwendet werden.
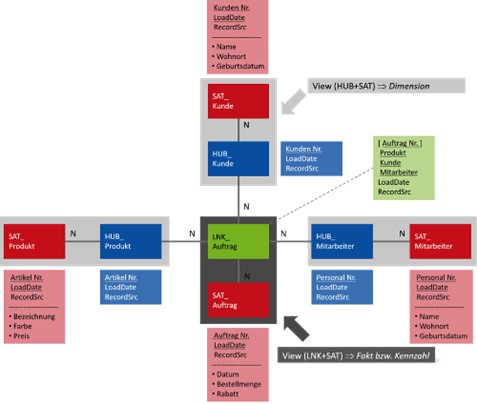
Architektur des Data Vaults
Die Architektur eines Data Vaults besteht dabei aus den folgenden Schritten:
- Kopieren der Daten aus den Quellsystemen in den Staging Bereich
- Beladung des Raw Vaults, welcher komplett aus Quelldaten besteht
- Aufbau des Business Vault, in welchem die Geschäftsregeln angewendet werden. Durch verschiedene Data Cleaning Schritte muss der Business Vault daher nicht aus den Quelldaten bestehen
- Der Business Vault dient als Quelle für die verschiedenen Data Marts
- Raw Data Mart (enthält auch Fehlerdaten)
- Info Mart
- Star Schema
- Berichte
- Metrics Mart (Ausführungsverlauf)
- Fehler Mart (Enthält fehlerhafte Daten)
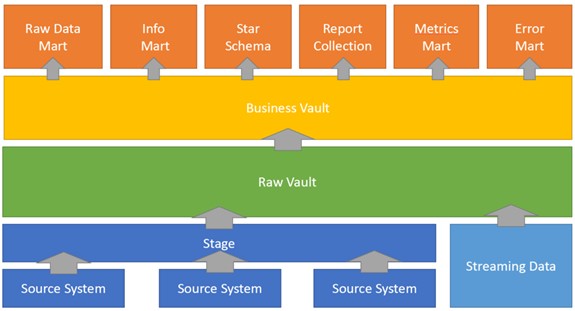
Konsolidierung von Daten
Die Konsolidierung der Daten funktioniert dabei eigenständig im Stern-Schema des Data Marts. Die unkonsolidierten Daten werden dabei im Raw Data Mart abgelegt und die konsolidierten im Information Mart, sodass diese auch gemeinsam ausgewertet werden können. Des Weiteren erfolgt die Manipulation von Daten nur im Business Vault und in der darunterliegenden Schicht des Raw Vaults werden die „hard business rules“ angewandt, also die Regeln, welche sich nur sehr selten ändern. Dadurch sind auch Metainformationen über Daten vorhanden, welche bspw. im Beladungsprozess „steckengeblieben“ sind.
Data Vault Implementierung
MS SQL Server
Ein Data Vault kann wie ein Data Warehouse implementiert werden. Hierbei eignet sich z.B. der Microsoft SQL Server bzw. das Microsoft SQL Server Management System. Hierbei können Beladungsprozeduren erstellt werden, welche ebenfalls automatisiert werden können. Die Hubs, Links und Satelliten können dabei im relationalen Schema angelegt werden. Des Weiteren unterstützt das SSMS die sogenannte Delta-Datenverarbeitung, bei welcher nur aktuelle, sich veränderte Daten neu geladen werden, während der Großteil der Daten somit nicht ständig neu in den Prozeduren verarbeitet werden muss. Auf diesem Weg können sehr kurze Aktualisierungszyklen vorgehalten werden, was bspw. für die Logistik eine große Rollen spielen kann.
Low Code und No Code Plattformen
Neben klassischen Datenbanksystemen können auch Low- oder No-Code Plattformen eingesetzt werden. Hierbei bietet bspw. Wherescape eine Automatisierung des Data Vaults mit Hilfe von built-in wizards und templates an.
Wo geht die Reise hin? (Data Vault 2.0)
Die aktuellste Version des Data Vault Konzepts erweitert die drei Tabellentypten um zwei weitere. Beim ersten handelt es sich um die sogenannten „PIT“ Tabellen. Diese stellen ein Upgrade der Satelliten dar, welches vor allem in Situationen zum Tragen kommen soll, in denen die Queries mehr als eine Satellitentabelle joinen müssen. Die zweite neue Art sind die „Bridge“ Tabellen, welche ebenfalls Satelliten erweitern sollen. Diese sollen vor allem Links erweitern, um Joins zwischen mehreren Hubs und Links zu verbessern.
Dies war ein erster Einstieg in Data Vaults. Für Details kommt am besten auf uns zu oder informiert euch direkt bei den Data Vault Erfindern in:
- Building a scalable data warehouse with data vault 2.0, Daniel Linstedt
- Supercharge your data warehouse, Daniel Linstedt
Ihr benötigt eine Analyse des Daten-Dschungels sowie Empfehlung für eure ideale Datenbank-Architektur? Dann nichts wie ab zu unserem Data Strategy & Analytics Assessment!
Übersicht der Database, Data Warehouse & Data Lake Serie:
- Data Vault Basics
- Einführung in Cloud-basierte Datenbanken
- Einführung in Microsoft Azure Storage Accounts
- Einführung in No-SQL-Datenbanken
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns gerne.
Ihre Ansprechpartner



