Data Engineering

Serie | Data Science – Large Language Models
Serie | Data Science – Was sind Large Language Models? Was sind Large Language Models? Large Language Models (LLMs) sind leistungsstarke KI-Modelle, die auf umfangreichen Textdaten trainiert werden. Sie haben die Fähigkeit, natürliche Sprache zu verstehen und zu generieren. LLMs werden für verschiedene Natural Language Processing (NLP)-Aufgaben eingesetzt, darunter zum Beispiel: Traditionelle Ansätze zur Verarbeitung natürlicher Sprache Traditionelle Ansätze zur
Serie | Data Integration (Migration & ETL) – Einführung & Anwendungsbeispiel in Databricks
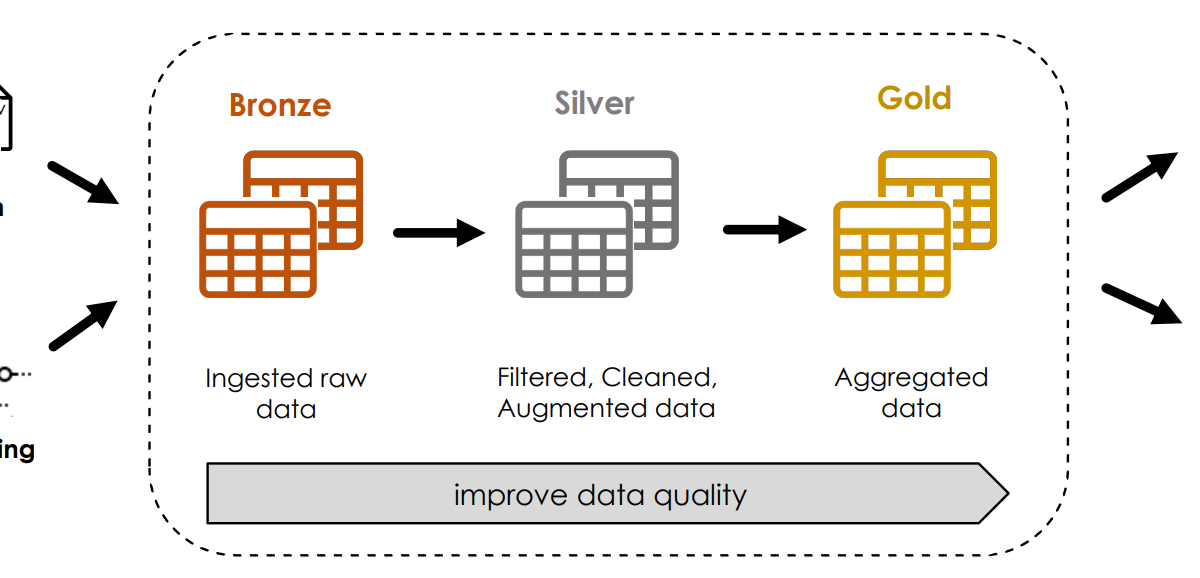
Serie | Data Integration (Migration & ETL) – Einführung & Anwendungsbeispiel in Databricks Databricks ist eine Multi-Cloud Lakehouse Plattform basierend auf Apache Spark, welche den gesamten Prozess der Datenverarbeitung abdeckt: Data Engineering, Data Science und Machine Learning. Databricks wird auf den größten Cloud-Plattformen Microsoft Azure, Google Cloud und Amazon AWS angeboten. Die Databricks Umgebung übernimmt dabei die Verwaltung von Spark
Serie | Data Science (ML & AI) – Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
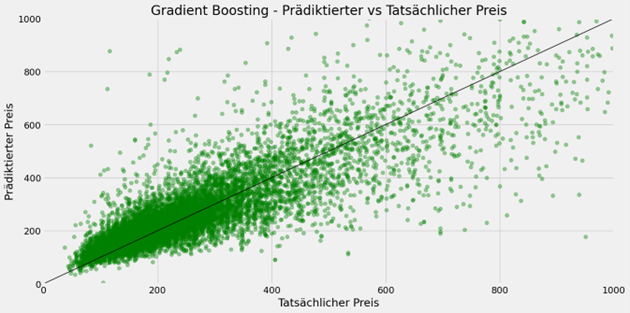
Serie | Data Science (ML & AI) – Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen Während es im ersten Teil um die Architektur und Funktionsweise von baumartigen Regressionsverfahren ging, folgt nun die praktische Anwendung. Dazu werden ein Regressionsbaum, eine Random Forest Regression sowie eine Gradient Boosting Regression entwickelt, welche die Preise von Airbnb-Unterkünften prädiktieren. Beschreibung des Datensatzes Der Datensatz
Serie | Data Science (ML & AI) – Architektur und Funktionsweise von baumartigen Regressionsverfahren
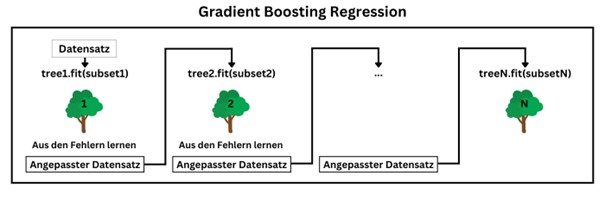
Serie | Data Science (ML & AI) – Architektur und Funktionsweise von baumartigen Regressionsverfahren Entscheidungsbäume eignen sich als Machine Learning Modelle zur Lösung komplexer Klassifikations- und Regressionsprobleme. Zudem bilden Entscheidungsbäume die wesentliche Komponente von Random Forest und Gradient Boosting Verfahren. Aufbau eines Regressionsbaums Der Wurzelknoten stellt den Beginn des Baums dar und repräsentiert den gesamten Datensatz. Von dort ausgehend
Serie | Data Governance – Einführung in Microsoft Purview
Serie | Data Governance – Einführung in Microsoft Purview Das Governanceportal Microsoft Purview bietet umfassende Lösungen zur Datenverwaltung, die helfen können, lokale, Multicloud- und Software-as-a-Service-Daten (SaaS) zu verwalten. Mit dem Microsoft Purview-Governanceportal kann man folgendes erreichen: Erstellung einer ganzheitlichen und aktuellen Übersicht über die aktuelle Datenlandschaft, mithilfe einer automatisierten Datenermittlung, Klassifizierung und Verfolgung der Daten nutzen. Befähigen Sie Data Owners,
Serie | Data Integration (Migration & ETL) – Schritte zur erfolgreichen Umsetzung eines DevOps-Projekts: Tools, Techniken und Best Practices
Serie | Data Integration (Migration & ETL) – Schritte zur erfolgreichen Umsetzung eines DevOps-Projekts: Tools, Techniken und Best Practices Die Implementierung eines DevOps Projektes kann eine Herausforderung sein, wenn sie noch nie zuvor damit gearbeitet haben. In diesem Artikel werden wir Ihnen die grundlegenden Schritte zur Umsetzung eines DevOps-Projektes aufzeigen und die verschiedenen Bestandteile erklären. Im Folgenden werden Ihnen
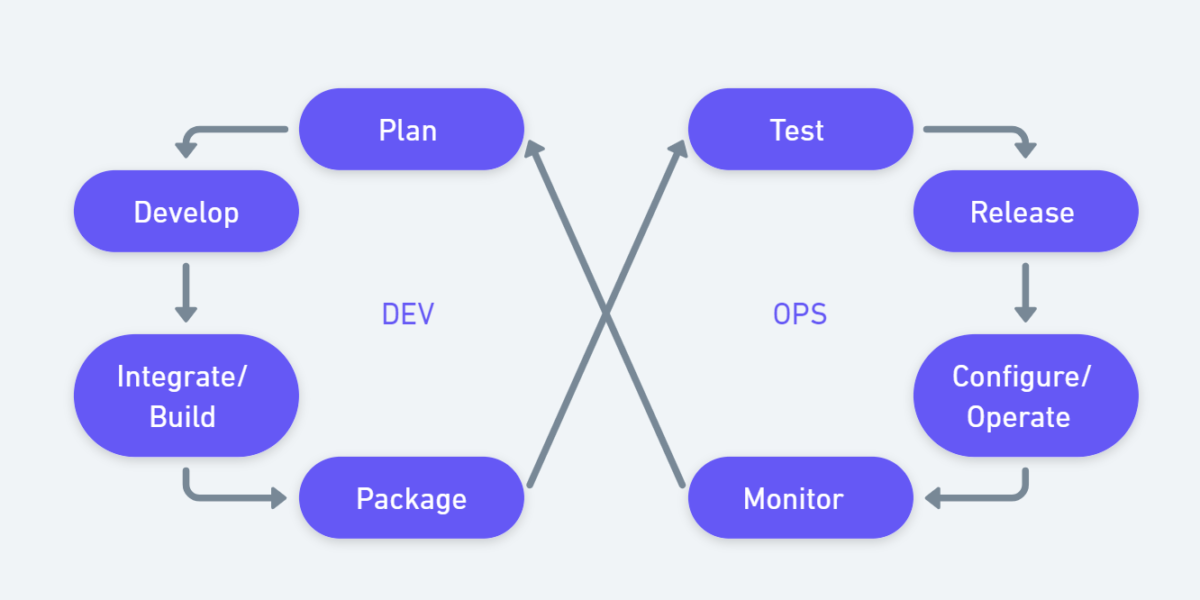
Serie | Data Integration (Migration & ETL) – Azure DevOps
Serie | Data Integration (Migration & ETL) – Einführung in Azure DevOps Was ist Azure DevOps Azure DevOps ist eine Plattform, die eine kollaborative Kultur und eine Reihe von Prozessen unterstützt, die Entwickler, Projektmanager und Mitwirkende bei der Entwicklung von Software zusammenbringen. Dafür können Sie mit Azure DevOps Ihre Arbeit planen, bei der Codeentwicklung zusammenarbeiten und Anwendungen erstellen und bereitstellen.
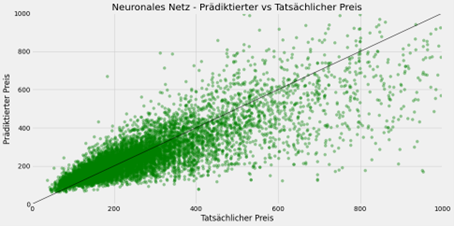
Serie | Data Science (ML & AI) – Entwicklung eines neuronalen Netzes zur Prädiktion von Airbnb-Preisen
Serie | Data Science (ML & AI) – Entwicklung eines neuronalen Netzes zur Prädiktion von Airbnb-Preisen Nachdem im letzten Teil die Architektur und Funktionsweise von neuronalen Netzen beschrieben wurde, geht es nun um die praktische Anwendung. Dazu wird ein neuronales Netz entwickelt, welches die Preise von Airbnb-Unterkünften prädiktiert. Beschreibung des Datensatzes Der Datensatz zum Training des neuronalen Netzes ist
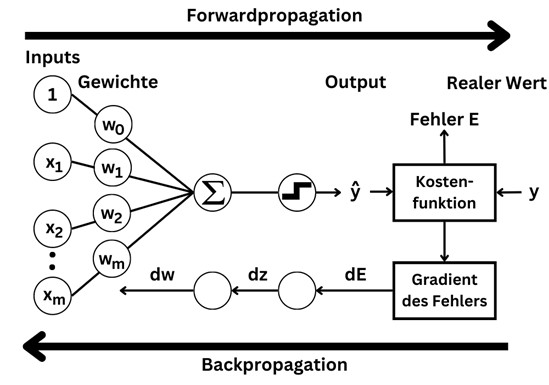
Serie | Data Science (ML & AI) – Architektur und Funktionsweise von neuronalen Netzen
Serie | Data Science (ML & AI) – Architektur und Funktionsweise von neuronalen Netzen Architektur und Funktionsweise von neuronalen Netzen Neuronale Netze bestehen aus mehreren Schichten von miteinander verbundenen Neuronen zur Simulation des menschlichen Gehirns. Im Gegensatz zu traditionellen Machine Learning Algorithmen, wie Linearer Regression, profitieren neuronale Netze durch die Vielzahl an Parametern von einer enormen Menge an Trainingsdaten. Neuronale

Serie – Data & AI Plattformen | Einführung in Palantir Foundry
Serie – Data & AI Plattformen | Einführung in Palantir Foundry Was ist Palantir Foundry? Foundry wurde neben Gotham und Apollo von Palantir Technologies entwickelt, einem amerikanischen Unternehmen, das sich auf Datenanalyse und -integration spezialisiert hat. Die Plattform wurde ursprünglich für Regierungsbehörden entwickelt, ist aber heute auch bei großen Unternehmen in verschiedenen Branchen wie Finanzen, Gesundheitswesen und Logistik im


Seiten Links
Social
Adresse
DE-80797 München
