Data Science

Serie | Data Science – Prompt Engineering in ChatGPT
Serie | Data Science – Prompt Engineering in ChatGPT Einführung Die rasante Entwicklung künstlicher Intelligenz (KI) und natürlicher Sprachverarbeitung (NLP) hat neue Möglichkeiten eröffnet, wie wir mit Technologie interagieren können. Ein Schlüsselelement dieser Interaktion ist das sogenannte „Prompt Engineering„, eine Methode, die entscheidend für die Effizienz und Effektivität von Large Language Models (LLMs) wie ChatGPT geworden ist. Was sind Prompts?

LinkedIn I Tiefgehende Datenanalyse mit ChatGPT – wie geht das?
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden. Inhalt entsperren Erforderlichen Service akzeptieren und Inhalte entsperren Weitere Informationen

LinkedIn I Tipp zur wirkungsvollen Dashboardgestaltung
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden. Inhalt entsperren Erforderlichen Service akzeptieren und Inhalte entsperren Weitere Informationen

Serie | Data Science – Das Large Language Model GPT-4
Serie | Data Science – Das Large Language Model GPT-4 OpenAI’s GPT-4-Modell Wie bereits im vorherigen Impuls-Bericht „Large Language Models“ unserer Data Science-Serie erläutert, ist OpenAI’s GPT-Modell ein leistungsstarkes KI-Modell, die auf umfangreichen Textdaten mittels selbst-überwachtem (self-supervised), überwachtem (supervised) und verstärkendem (reinforcement) Lernen trainiert wird. Es ist dazu in der Lage, natürliche Sprache zu verstehen sowie zu generieren und wird

LinkedIn I Wie gestalte ich ein wirkungsvolles Dashboard, das meiner Zielgruppe echten Mehrwert liefert?
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden. Inhalt entsperren Erforderlichen Service akzeptieren und Inhalte entsperren Weitere Informationen

LinkedIn I Wie können Unternehmen Large Language Models wie GPT-4 nutzen?
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden. Inhalt entsperren Erforderlichen Service akzeptieren und Inhalte entsperren Weitere Informationen

Serie | Data Science – Large Language Models
Serie | Data Science – Was sind Large Language Models? Was sind Large Language Models? Large Language Models (LLMs) sind leistungsstarke KI-Modelle, die auf umfangreichen Textdaten trainiert werden. Sie haben die Fähigkeit, natürliche Sprache zu verstehen und zu generieren. LLMs werden für verschiedene Natural Language Processing (NLP)-Aufgaben eingesetzt, darunter zum Beispiel: Traditionelle Ansätze zur Verarbeitung natürlicher Sprache Traditionelle Ansätze zur

LinkedIn I Data Governance Dos and Donts
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden. Inhalt entsperren Erforderlichen Service akzeptieren und Inhalte entsperren Weitere Informationen
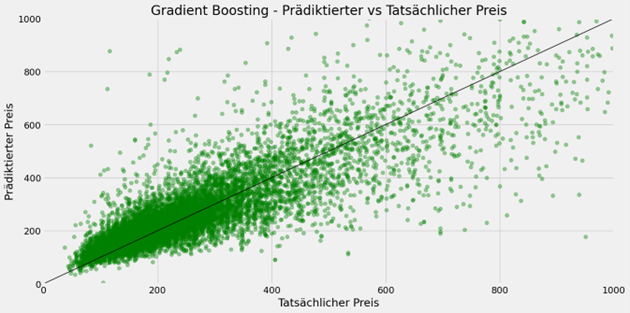
Serie | Data Science (ML & AI) – Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
Serie | Data Science (ML & AI) – Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen Während es im ersten Teil um die Architektur und Funktionsweise von baumartigen Regressionsverfahren ging, folgt nun die praktische Anwendung. Dazu werden ein Regressionsbaum, eine Random Forest Regression sowie eine Gradient Boosting Regression entwickelt, welche die Preise von Airbnb-Unterkünften prädiktieren. Beschreibung des Datensatzes Der Datensatz
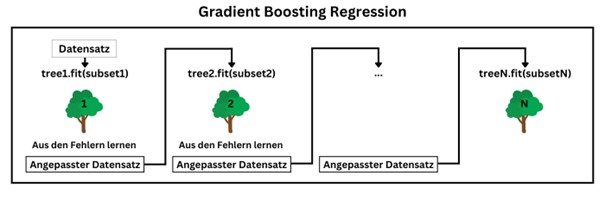
Serie | Data Science (ML & AI) – Architektur und Funktionsweise von baumartigen Regressionsverfahren
Serie | Data Science (ML & AI) – Architektur und Funktionsweise von baumartigen Regressionsverfahren Entscheidungsbäume eignen sich als Machine Learning Modelle zur Lösung komplexer Klassifikations- und Regressionsprobleme. Zudem bilden Entscheidungsbäume die wesentliche Komponente von Random Forest und Gradient Boosting Verfahren. Aufbau eines Regressionsbaums Der Wurzelknoten stellt den Beginn des Baums dar und repräsentiert den gesamten Datensatz. Von dort ausgehend


Seiten Links
Social
Adresse
DE-80797 München
