
Serie | RPA – Automatisierte Extrahierung von Daten aus unstrukturierten Dokumenten mit UiPath
Rechnungsverarbeitung mit UiPath
In den vorherigen beiden Impulsen der RPA-Serie “Serie | RPA – Einsatz von Robotic Process Automation zur Automatisierung regelbasierter Prozesse” und “Serie | RPA – Robotic Process Automation mit UiPath als Softwaretool zur Automatisierung von Geschäftsprozessen” wurden bereits die Grundlagen zu RPA im Allgemeinen sowie UiPath als Softwaretool zur Umsetzung der Automatisierungen ausführlich erläutert.
In diesem Impuls-Beitrag soll es nun um die praktische Umsetzung einer solchen Automatisierung innerhalb des Tools UiPath Studio gehen. Für eine anschauliche Erklärung wird dies konkret anhand der Rechnungsverarbeitung gezeigt. Dabei besteht das Ziel darin, einen Roboter zu entwickeln, der bestimmte Daten aus Rechnungen automatisiert extrahiert und zur Weiterverarbeitung in ein Excel-Sheet speichert. Eine der Herausforderungen hierbei ist, dass die unterschiedlichen Rechnungen verschiedene Strukturen aufweisen.
Beschreibung der Code-Struktur in UiPath Studio
Der Prozess der Datenextraktion besteht aus fünf Aktivitäten:

Im Taxonomy Manager von UiPath werden zunächst unterschiedliche Dokumenttypen in Gruppen und Kategorien eingeteilt, um diese zu klassifizieren. Dokumenttypen können beispielsweise Belege, Zeugnisse, Urkunden oder auch Rechnungen sein. Der Name des Dokumenttyps lautet in diesem Anwendungsfall „Rechnung“.
UiPath generiert automatisch eine ID des Dokumenttyps, welcher später bei der Aktivität „Classify Document Scope“ Verwendung findet. Anschließend werden im Taxonomy Manager alle Felder, die aus einem Dokument vom Typ „Rechnung“ ausgelesen werden sollen, festgelegt. Diese Felder lauten „RechnungsNummer“, „Rechnungssteller“ und „RechnungsDatum“ sowie „Artikel-Nummer“, „ArtikelMenge“ und „Preis“.
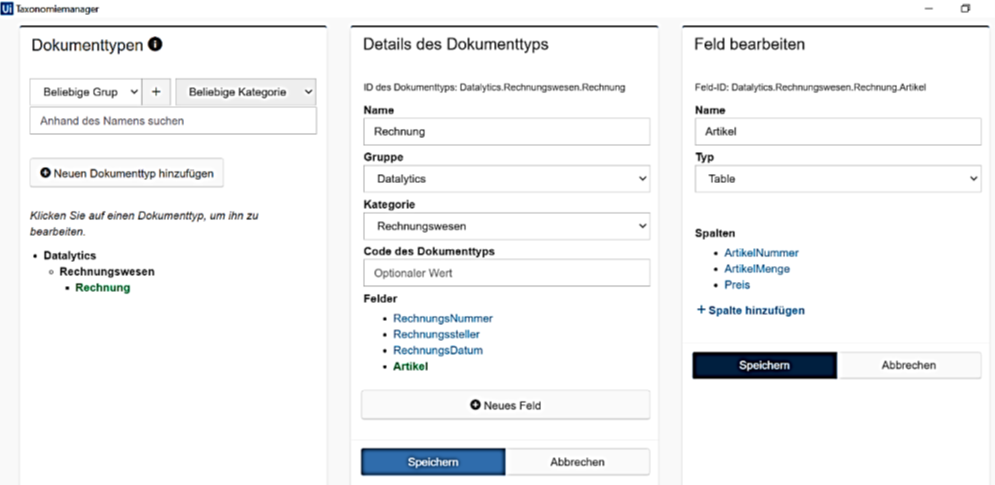
Die Informationen über die zu extrahierenden Felder dieses Dokumenttyps können anschließend in einer Variable gespeichert und innerhalb der Aktivität „Load Taxonomy“ aufgerufen werden.
Im zweiten Schritt des Extrahierungsprozesses wird nun der gesamte Inhalt des Rechnungsdokuments ausgelesen. Um Inhalte aus Dokumenten auszulesen, stellt UiPath die drei Scraping-Methoden FullText, Native sowie Optical Character Recognition (OCR) zur Verfügung.
- Die FullText-Methode eignet sich, um Informationen aus Dokumenten und Websites zu extrahieren. Sie ist die schnellste der drei Methoden, kann im Hintergrund laufen und ist in der Lage, versteckte Texte zu erkennen.
- Die Native-Methode kann nicht im Hintergrund arbeiten und erkennt keine versteckten Texte. Im Gegensatz zur FullText-Methode ermöglicht sie jedoch zusätzlich die Extrahierung der Position des Textes.
- OCR stellt eine Texterkennungstechnik dar, die angewandt wird, wenn die beiden zuvor genannten Methoden den Text des Dokuments nicht erkennen können. Dies ist beispielsweise der Fall, wenn Informationen aus Bildern, gescannten Dokumenten oder unstrukturierten PDFs gelesen werden sollen.
Über die Aktivität „Digitize Document“ wird das Dokument nun also zunächst digitalisiert. Damit wandelt der Roboter die unstrukturierten Daten in strukturierte Daten um, welche anschließend durch OCR extrahiert werden. Der gesamte Inhalt wird dann in einer Variable gespeichert.
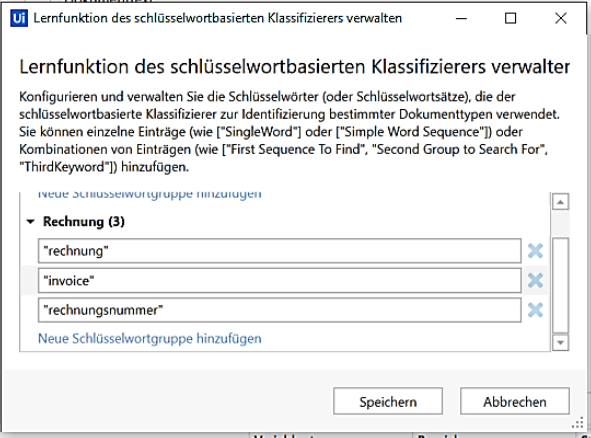
Die dritte Aktivität „Classify Document Scope“ ist dafür zuständig, das Rechnungsdokument dem zuvor im Taxonomy Manager erstellten Dokumenttyp „Rechnung“ zuzuweisen. Die Klassifizierung des eingelesenen Rechnungsdokuments ist über den Keyword Based Classifier möglich. Dort werden bestimmte Schlüsselwörter festgelegt, durch die der schlüsselwortbasierte Klassifizierer einen bestimmten Dokumenttyp identifizieren kann. In diesem Anwendungsfall werden die Schlüsselwörter „rechnung“, „invoice“ und „Rechnungsnummer“ gewählt, da mindestens eines davon auf jeder Rechnung auftaucht.
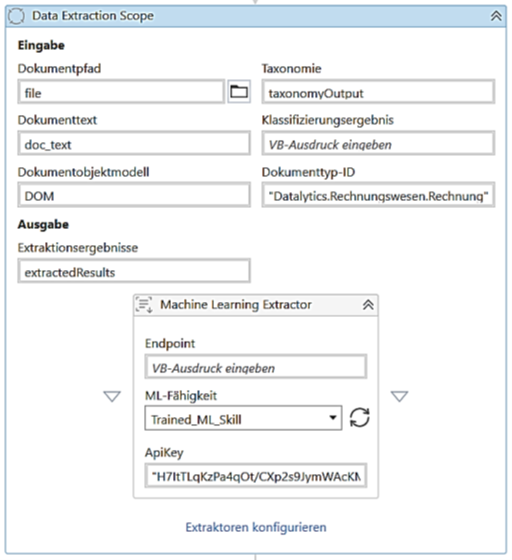
Innerhalb der vierten Aktivität „Data Extraction Scope“ werden die entsprechenden Daten schließlich aus den Feldern des jeweiligen Dokuments extrahiert und in einer Variablen gespeichert. Hierfür verwendet der Extractor ein Machine Learning Modell. Zur Extrahierung der Rechnungsdaten wurde das bereits vortrainierte, von UiPath zur Verfügung gestellte Machine-Learning-Modell „Invoices“ des Out-of-the-Box-Pakets „UiPath Document Understanding“ ausgewählt. Dieses Modell eignet sich zur Extrahierung häufig in Rechnungen vorkommender Daten, kann innerhalb des AI Centers von UiPath erstellt werden und ist sofort einsatzbereit.
Über den API-Key, welcher in der nachfolgend abgebildeten Aktivität angegeben werden muss, erhält man Zugriff auf die Machine-Learning-Modelle von UiPath. Dieser wird automatisch generiert, sobald ein Account für die UiPath Automation Cloud erstellt wurde.
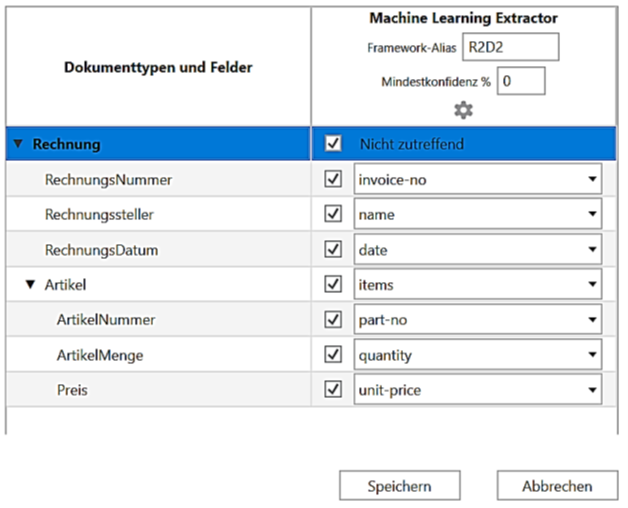
Über den Button „Extraktoren konfigurieren“ wird festgelegt, welche bereits vorhandenen Extraktoren auf die einzelnen Felder angewendet werden sollen. Beispielsweise wird dem eigens benannten Feld „RechnungsNummer“ der Extraktor mit der eindeutigen internen Taxonomie „invoice-no“ zugewiesen. Dadurch erkennt das vortrainierte Machine-Learning-Modell, welches Rechnungsfeld gesucht wird und kann es anschließend auswählen und extrahieren.
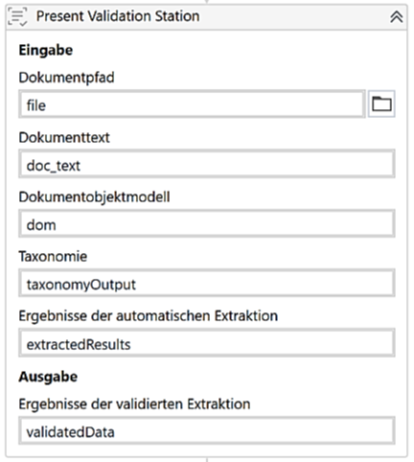
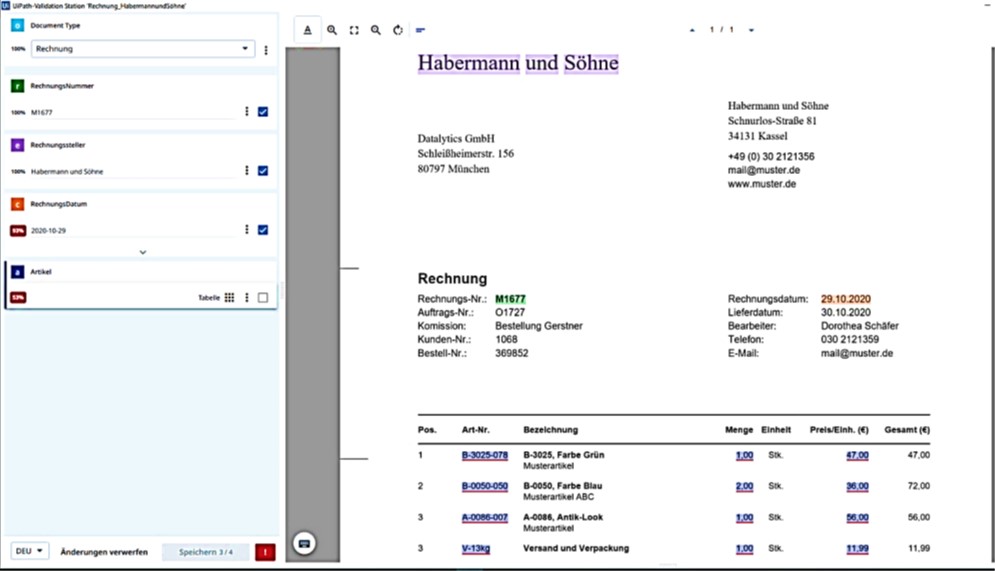
Die fünfte Aktivität des Prozesses ist „Present Validation Station„. Hier werden die durch das ML-Modell extrahierten Daten geladen und an die Validation Station von UiPath übergeben. Bei Ausführung dieser Aktivität öffnet sich die Benutzeroberfläche der Validation Station. Diese stellt neben dem UiPath Action Center eine von zwei Möglichkeiten dar, die UiPath seinen Nutzern bietet, um Daten über eine Mensch-Maschinen-Schnittstelle zu validieren.
Der Nutzer überprüft und bestätigt die extrahierten Daten. Er hat die Möglichkeit, falsch ausgelesene Daten in der Validation Station zu korrigieren. Die Daten werden anschließend in einer Variable gespeichert. Der Roboter wartet so lange bis die Daten bestätigt wurden und setzt den Prozess erst nach der Speicherung fort.
Im Anschluss an die Extrahierung und Validierung exportiert der Roboter schließlich die Daten über die Aktivität „Export Extraction Results“ in ein Dataset. Anschließend werden die Daten über die Aktivität „Write Range“ in eine Excel-Tabelle geschrieben. Im Anschluss kann die Excel-Tabelle beispielsweise dazu verwendet werden, die Daten in ein ERP-System zu übertragen oder anderweitig weiterverarbeitet werden.
Eine Möglichkeit, die Datenextraktion mithilfe von OCR weiter zu verbessern und somit Fehler beim Auslesen der Daten zu vermeiden, ist das Trainieren des ML-Modells. Möchten Sie mehr darüber erfahren, wie ML-Modelle in UiPath trainiert werden können? Dann lesen Sie unseren Impuls-Beitrag der RPA-Serie „Serie | RPA – Trainieren eines ML-Modells mit UiPath„.
Übersicht der RPA Serie:
- Einsatz von Robotic Process Automation zur Automatisierung regelbasierter Prozesse
- Robotic Process Automation mit UiPath als Softwaretool zur Automatisierung von Geschäftsprozessen
- Einführung von Power BI Robots zur automatischen Versendung von Reports und Dashboards
- Automatisierte Extrahierung von Daten aus unstrukturierten Dokumenten mit UiPath
- Trainieren eines ML-Modells mit UiPath zur optimierten Dokumentenverarbeitung
- Automatisiertes Dokumentenmanagement für ein strukturiertes Ablagesystem mit UiPath
- RPA Best Practices
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns gerne.
Ihre Ansprechpartnerin



