
Serie | RPA – Trainieren eines ML-Modells mit UiPath zur optimierten Dokumentenverarbeitung
Einführung ML-Modelle
Im vorherigen Beitrag “Automatisierte Extrahierung von Daten aus unstrukturierten Dokumenten mit UiPath” unserer Impuls-Serie zum Thema RPA wurde die Vorgehensweise zur Automatisierung der Datenauslesung aus unstrukturierten Rechnungsdokumenten mit UiPath genau erklärt.
In diesem Impuls-Beitrag soll es nun um die Verbesserung der Daten-Auslesung mithilfe eines Machine Learning Modells gehen. Für eine anschauliche Erklärung wird dies wieder konkret anhand der Rechnungsverarbeitung gezeigt. Dabei besteht das Ziel darin, einen Roboter zu entwickeln, der bestimmte Daten aus Rechnungen automatisiert extrahiert und zur Weiterverarbeitung in ein Excel-Sheet speichert. Mithilfe des Trainierens eines ML-Modells soll die korrekte Extrahierung bestimmter Daten noch einmal verbessert werden, sodass keine Überprüfung durch einen Menschen mehr notwendig ist.
Das AI-Center von UiPath
Im Artificial-Intelligence-Center (kurz AI-Center) von UiPath können ML-Modelle erstellt, entwickelt, verwaltet und angepasst werden. Außerdem findet hier das Trainieren und Testen der Modelle statt. Anschließend können sie innerhalb eines Prozesses in UiPath Studio eingesetzt werden. Die ML-Modelle können entweder in einer Python-IDE wie Eclipse oder Visual Studio von einem Nutzer selbst entwickelt oder mithilfe einer Auto-Machine-Learning-Plattform wie H30 Driverless AI erstellt werden. Daraufhin wird das Modell im AI-Center hochgeladen und ist einsatzbereit.
Neben der Nutzung eigener Modelle, stellt UiPath selbst ML-Pakete für seine Nutzer bereit. Diese werden als „Out-of-the-Box-Pakete“ bezeichnet. Zu diesen gehören „UiPath Document Understanding“, „UiPath Task Mining“ und einige weitere Open-Source-Packages wie „Image Analysis“ und „Language Analysis“.
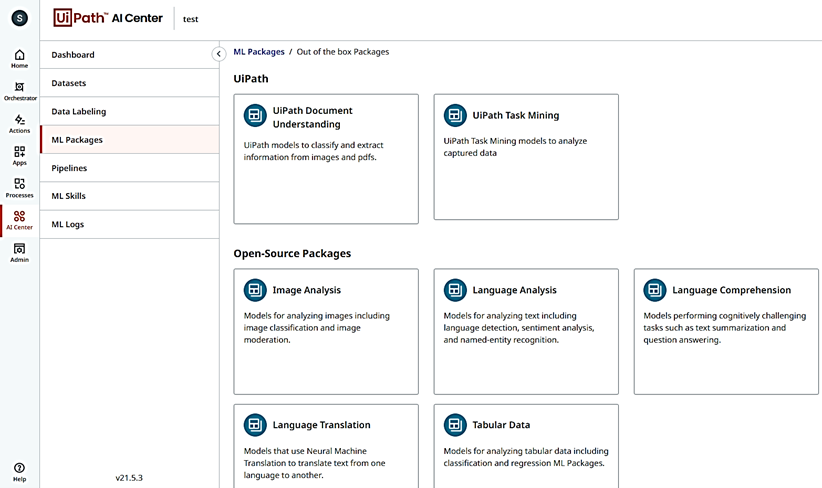
Document Understanding enthält mehrere ML-Packages, welche in vier Kategorien unterteilt werden können:
- UiPath Document OCR
- Document Understanding Models
- Out of the box pre-trained Machine-Learning-Models
- Out-of-the-box Packages
UiPath Document OCR ist ein ML-Modell, welches nicht weiter trainierbar ist. Unter Optical Character Recognition (OCR) versteht man die automatisierte Texterkennung innerhalb von Bildern und Dokumenten. UiPath bietet für die Anwendung von OCR, um beispielsweise Daten aus Rechnungen oder Belegen zu lesen, einige unterschiedliche Module, wie Google Cloud Vision OCR, Microsoft OCR sowie OmniPage OCR an.
Document Understanding Modelle sind trainierbar. Durch den Einsatz dieser Modelle können beliebige Daten aus jeder Art von strukturierten sowie semi-strukturierten Dokumenten extrahiert werden.
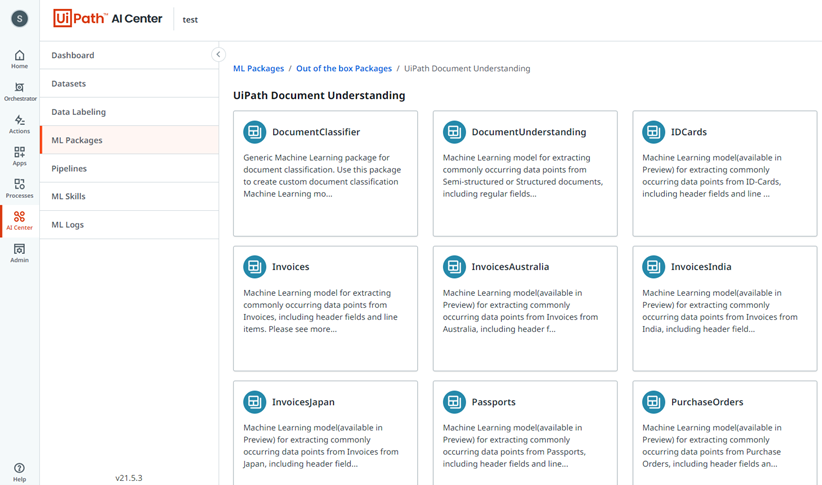
Out of the box pre-trained Machine-Learning-Modelle sind, wie der Name bereits sagt, trainierte Modelle, welche jedoch durch individuelles Training erweitert werden können. Dadurch kann diesen beispielsweise beigebracht werden, zusätzliche Felder in Dokumenten zu erkennen oder weitere Sprachen zu unterstützen. Diese ML-Modelle eignen sich besonders gut für die Verarbeitung von Rechnungen, Belege sowie Bestellformulare.
In der Anwendung, die im Rahmen dieser Impuls-Serie entwickelt worden ist, wurde das Out-of-the-box-pre-trained Machine-Learning-Modell „Invoices“, verwendet und trainiert, um die korrekten Daten aus den Dokumenten extrahieren zu können.
Trainieren des ML-Modells
Um das Trainieren des ML-Modells anzustoßen, wird in UiPath Studio der „Machine Learning Extractor Trainer“ eingesetzt. (Um den vorhergehenden Code nachvollziehen zu können, lesen Sie bitte unseren letzten Impuls-Beitrag)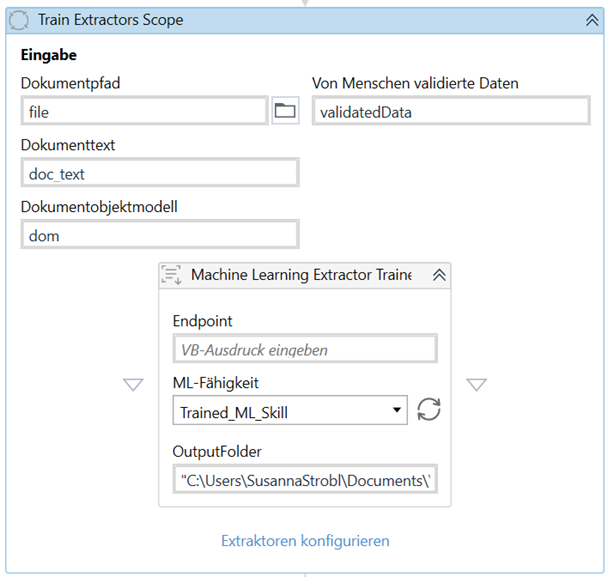
Sobald der Prozess gestartet wird, werden automatisch drei Unterordner, namens „documents“, „metadata“ und „predicitions“ erstellt. Im Ordner „documents“ befinden sich alle Rechnungen als PDF, die den Prozess bisher durchlaufen haben. Der Ordner „predicitions“ beinhaltet Informationen zum Aufbau und zur Struktur der Dokumente, bevor die Daten in der Validation Station validiert wurden. Im Ordner „metadata“ sind Informationen zum Aufbau und zur Struktur der einzelnen Dokumente nach Validierung der Daten gespeichert.
Diese Unterordner werden in den Data Manager von UiPath importiert. Der Data Manager ist eine Webanwendung, die als Docker Container bereitgestellt wird und über das AI Center von UiPath aufgerufen werden kann. Um den Data Manager nutzen zu können, muss zum einen eine Enterprise-Lizenz vorhanden sein und zum anderen müssen die Berechtigungen für die Verwendung von ML-Paketen im Orchestrator aktiviert werden.
Im Data Manager werden unterschiedliche Operationen durchgeführt. Dafür wird zunächst im AI-Center ein neues Projekt und in diesem ein Dataset angelegt, in das später die Trainings- und Testdaten geladen werden.
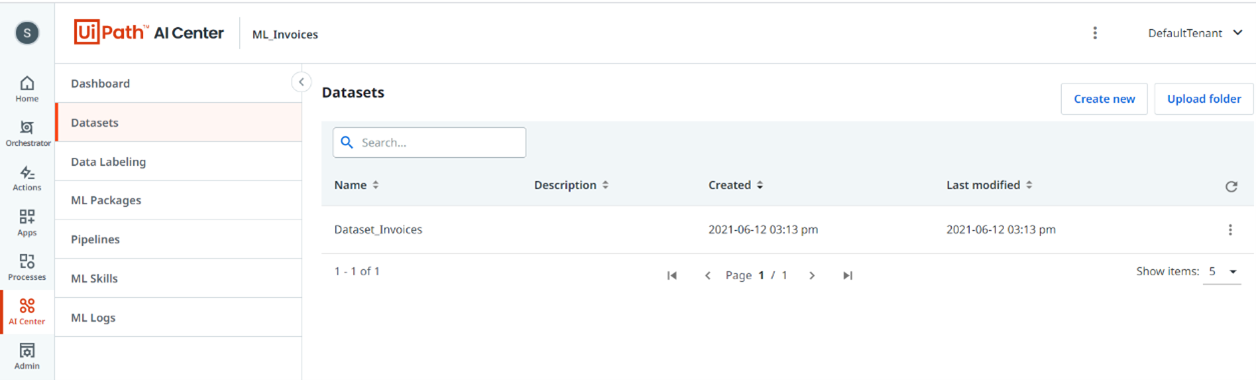
Anschließend wird innerhalb dieses Projekts eine Data Labeling Session angelegt, über die der Data Manager aufgerufen werden kann. Allgemein gesprochen versteht man unter „Data Labeling“ das Erkennen und Markieren von bestimmten Beispiel- bzw. Lern-Daten. Das Data Labeling erfolgt über einen OCR-Service.
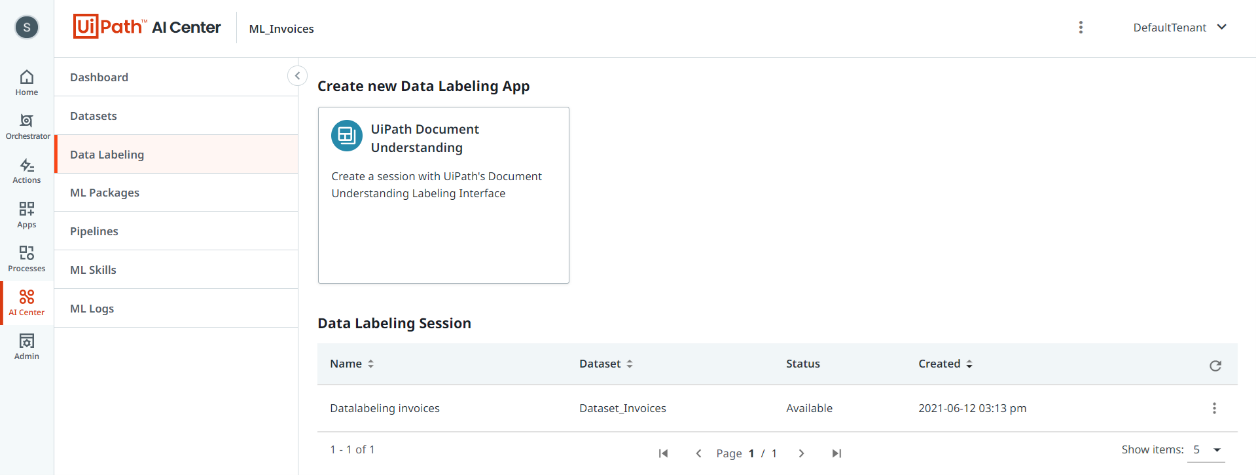
Sobald der Data Manager aufgerufen wurde, muss zunächst ein Schema in den Data Manager importiert werden. Dieses Schema enthält einen Satz von denjenigen Feldern, die bereits von dem vortrainierten ML-Modell „Invoices“ extrahiert wurden. Das Schema des Out-of-the-box-Modells wird von UiPath zur Verfügung gestellt und kann damit direkt in den Data Manager importiert werden.
In der unten stehenden Abbildung sind auf der rechten Seite und auf der oberen Hälfte des Screenshots die exportierten Felder zu sehen.
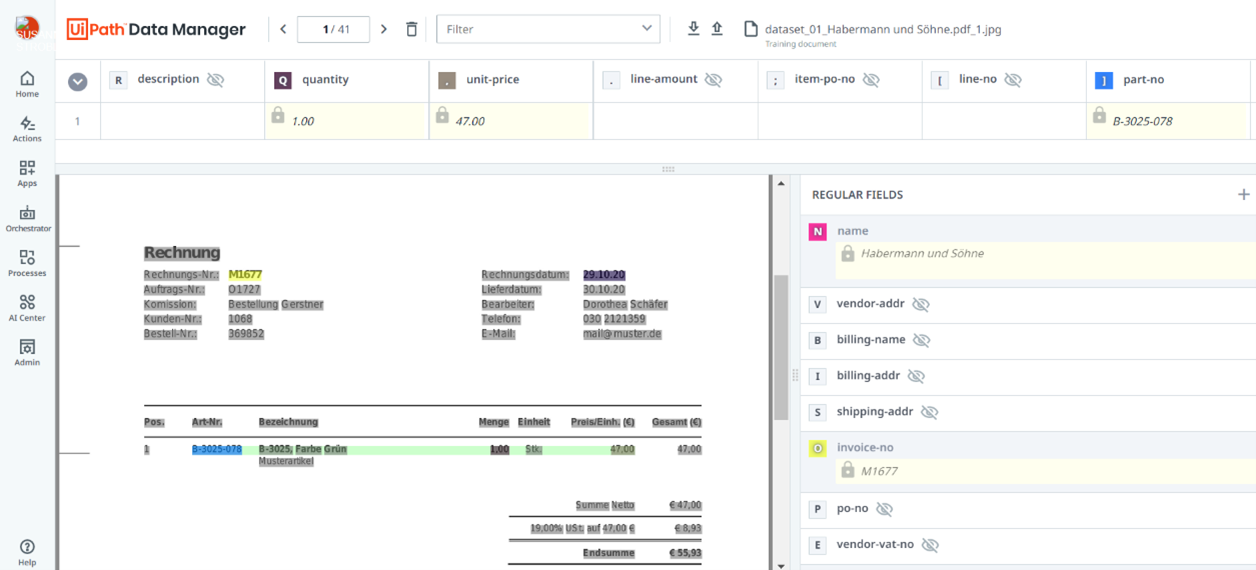
Anschließend werden die drei zuvor automatisch erstellten Unterordner „documents“, „metadata“ und „predicitions“ in den Data Manager importiert. Der Data Manager erkennt, dass der Import-Ordner Daten enthält, die vom Machine Learning Extractor Trainer erzeugt wurden und importiert sie entsprechend. Im oben abgebildeten Screenshot ist in der linken Bildhälfte beispielhaft eine in den Data Manager geladene Rechnung zu sehen. Die Felder, die zuvor extrahiert wurden, sind farbig markiert.
Nun kann der Anwender noch ein letztes Mal kontrollieren, ob alle Daten richtig validiert wurden, bevor die Daten anschließend in das AI Center exportiert werden. Spätestens an diesem Punkt sollten keine falsch validierten Daten mehr vorliegen, da sonst das ML-Modell falsch trainiert wird.
Durch den Export der Daten in das AI Center von UiPath, werden diese in das zuvor erstellte Dataset, das der Data Labeling Session zugeordnet wurde, gespeichert. Das automatisch generierte Dataset besteht nun aus zwei Unterordnern und zwei Dateien, wie im unten stehenden Screenshot zu sehen ist.
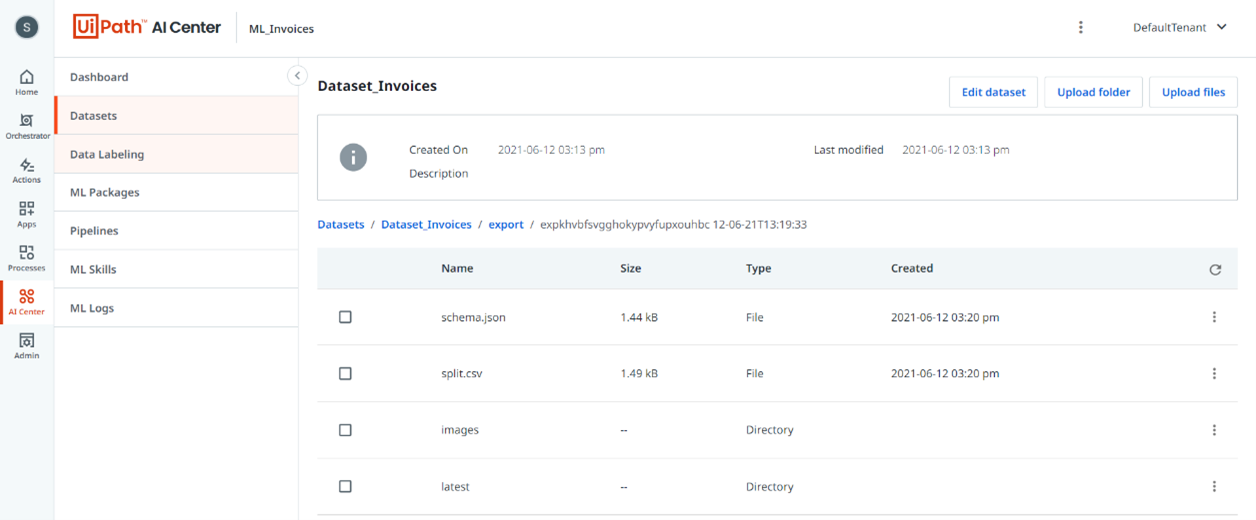
Unter anderem liegt eine Datei namens split.csv in dem Ordner ab, in der festgelegt wird, welche Dokumente zu Trainingszwecken und welche zu Testzwecken verwendet werden.
Sobald diese vorliegt, kann im AI Center von UiPath eine Trainings- sowie Test-Pipeline erstellt werden, über die das Modell im Anschluss trainiert und getestet wird.
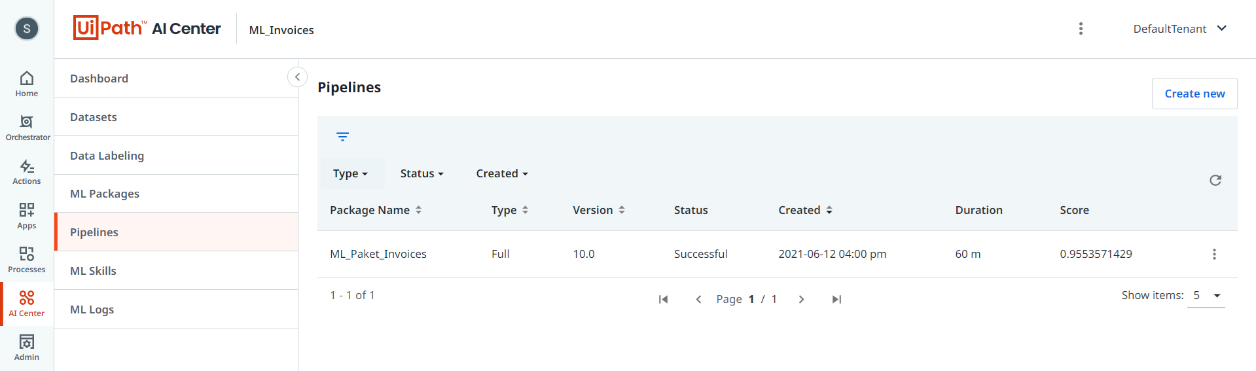
Nach erfolgreich abgeschlossenem Trainieren und Testen des Modells liegen unter anderem Evaluationsergebnisse des ML-Modells vor. Der Gesamt-F1-Score von 0,96 weist auf eine sehr hohe Genauigkeit des ML-Modells hin.
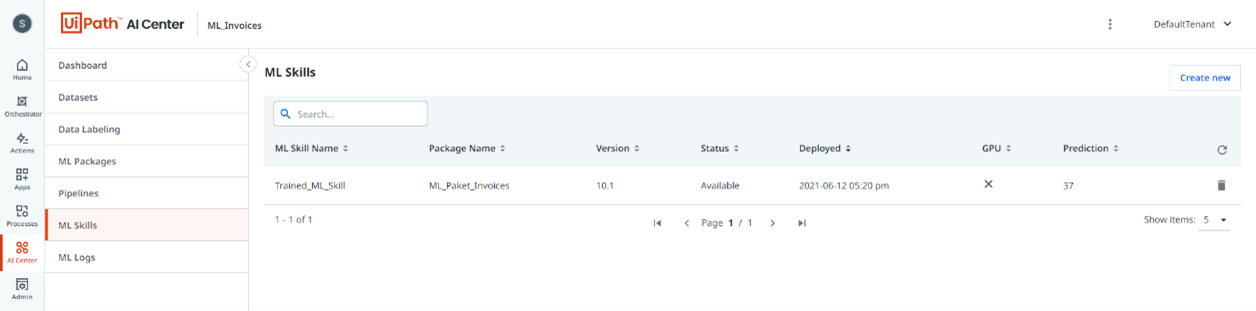
Zum Schluss kann für das neue Modell ein Machine Learning Skill erstellt werden, welcher in UiPath Studio innerhalb der Aktivität „Machine Learning Extractor“ eingesetzt wird. Somit kann der nächste Prozessdurchlauf mit dem weitertrainierten ML-Modell durchgeführt werden.
Übersicht der RPA Serie:
- Einsatz von Robotic Process Automation zur Automatisierung regelbasierter Prozesse
- Robotic Process Automation mit UiPath als Softwaretool zur Automatisierung von Geschäftsprozessen
- Einführung von Power BI Robots zur automatischen Versendung von Reports und Dashboards
- Automatisierte Extrahierung von Daten aus unstrukturierten Dokumenten mit UiPath
- Trainieren eines ML-Modells mit UiPath zur optimierten Dokumentenverarbeitung
- Automatisiertes Dokumentenmanagement für ein strukturiertes Ablagesystem mit UiPath
- RPA Best Practices
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns!
Ihre Ansprechpartnerin



