
Serie | Data Science – Maschinelles Lernen in Databricks mithilfe von MLlib
Einführung
In den letzten Jahren hat maschinelles Lernen die Art und Weise, wie Unternehmen Daten analysieren und nutzen, erheblich verändert. Die MLlib-Bibliothek, bereitgestellt von Databricks, einer Multi-Cloud-Lakehouse-Plattform basierend auf Apache Spark, bietet eine Vielzahl an Werkzeugen für maschinelles Lernen. Eines dieser Werkzeuge ist die binäre Klassifikation, mit der sich dieser Impuls eingehend beschäftigt.
Binäre Klassifikation (binary classification)
Mittels der binären Klassifikation, die dank der MLlib-Bibliothek von Databricks ohne großen Aufwand nutzen lässt, können unter anderem E-Mails als Spam oder Nicht-Spam klassifiziert, die Relevanz von Werbung für einen Nutzer ermittelt oder Vorhersagen über das Wetter für die kommenden Tage getroffen werden.
Das Vorgehen zum Einsatz der binären Klassifikation gliedert sich in drei Schritte:
- Datenvorbereitung: Umwandlung der Daten in numerische Werte
- Modellbildung und -optimierung: Aufbau und Optimierung verschiedener Modelle, Validierung der Ergebnisse und Vergleich der Modelle bzw. der Ergebnisse
- Vorhersage: Erstellung der Vorhersage mithilfe des besten Modells und den zugrundeliegenden Eingangsdaten
1. Datenvorbereitung
In vielen Algorithmen, insbesondere im Bereich des maschinellen Lernens, ist es schwierig, mit nicht-numerischen Werten als Labels zu arbeiten. Um dieses Problem zu umgehen, können die vorhandenen Werte mithilfe verschiedener Methoden in numerische Werte umgewandelt werden.
Eine gängige Methode ist das Category Indexing, bei dem, wie unten dargestellt, jedem eindeutigen Label eine Zahl zugeordnet wird:
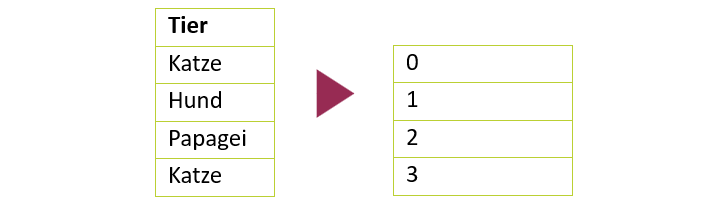
So erhält Kategorie 1 (Katze) die Ziffer 0, Kategorie 2 (Hund) die Ziffer 1 und Kategorie n die Ziffer n-1. Dies schafft eine Reihenfolge, die besonders nützlich ist, wenn die Variablen vorher ordinal angeordnet waren.
Eine weitere Methode ist das One-Hot-Encoding, bei dem jede Kategorie einer kategorialen Spalte in eine eigene Spalte umgewandelt wird. Jede dieser neuen Spalten repräsentiert eine Kategorie und enthält eine Eins, wenn die Kategorie in einer bestimmten Zeile zutrifft, und eine Null, wenn nicht. Auf diese Weise entsteht ein Vektor, der anzeigt, welche Kategorie in einer bestimmten Zeile vorhanden ist. Ordinale Beziehungen und Reihenfolgen werden dabei nicht berücksichtigt:

In einem weiteren Beispiel, bei dem vorhergesagt werden soll, ob eine Person mehr oder weniger als 50.000€ im Jahr verdient, basierend auf Variablen wie Alter, Abschluss, Geschlecht und Arbeitsstunden, wird One-Hot-Encoding verwendet. Um die Codierungsphasen besser zu organisieren, werden die Schritte in einer Pipeline angeordnet.
Der nachstehende Code wandelt kategoriale Variablen in numerische und One-Hot-encodierte Variablen um und organisiert diese in einer Pipeline. Mithilfe der Funktion StringIndexer wird jede kategoriale Spalte in Indizes umgewandelt, die dann in One-Hot-encodierte Variablen konvertiert werden:
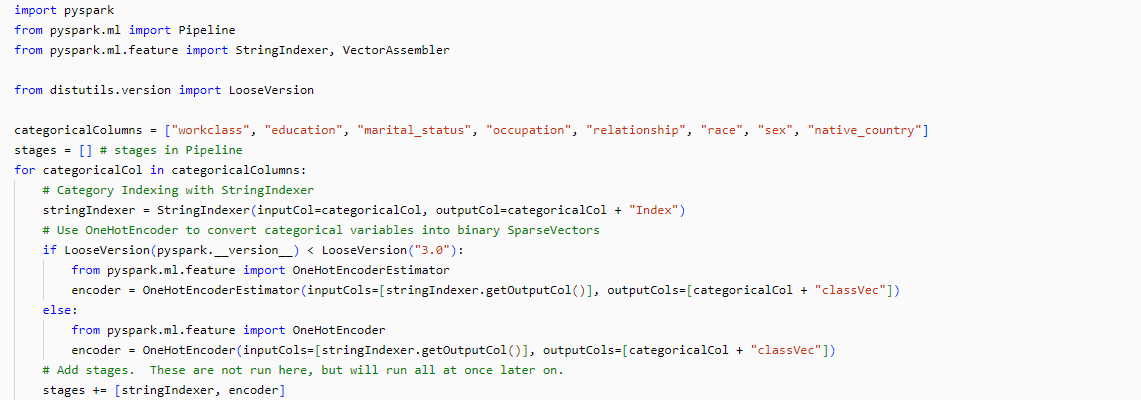
Die verschiedenen Feature-Spalten werden mithilfe des VectorAssemblers zu einer einzigen Vektor-Spalte kombiniert. Anschließend muss die Pipeline nur noch ausgeführt werden, um alle Transformationen gleichzeitig auf die Daten anzuwenden.
2. Erstellung und Optimierung des Modells



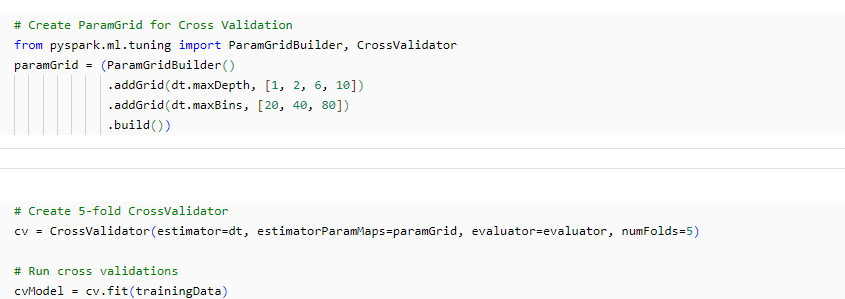
3. Treffen von Vorhersagen
Fazit ML in Databricks mithilfe von MLlib
Die MLlib-Bibliothek in Databricks stellt eine leistungsfähige und benutzerfreundliche Plattform für maschinelles Lernen bereit. Insbesondere die binäre Klassifikation wird durch die klar strukturierte Datenvorbereitung, Modellbildung und Vorhersage erheblich vereinfacht. Unternehmen können so präzise Vorhersagen und Klassifikationen durchführen, die ihre Entscheidungsprozesse und Geschäftsstrategien unterstützen. Die Integration von Databricks mit MLlib ermöglicht es, große Datenmengen effizient zu verarbeiten und komplexe Modelle zu implementieren, was letztlich die Nutzung von maschinellem Lernen in der Praxis erleichtert und verbessert.
Sie möchten mehr über ML in Databricks erfahren? Dann nichts wie ab zu unserem Data Strategy & Analytics Assessment!
Übersicht der Data Science (ML & AI) Serie:
- AI im Fußball: Entwicklung eines Expected Goals Modells
- Einführung in Deep Learning und PyTorch
- NLP zur Analyse von E-Mails
- Entwicklung eines Machine Learning Modells auf Azure
- Architektur und Funktionsweise von neuronalen Netzen
- Entwicklung eines neuronalen Netzes zur Prädiktion von Airbnb-Preisen
- Architektur und Funktionsweise von baumartigen Regressionsverfahren
- Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
- Was sind Large Language Modelle
- Das Large Language Model GPT-4
- Prompt Engineering in ChatGPT
- Entwicklung eines Large Language Modells mit LangChain & OpenAI
- Überblick zu Künstlicher Intelligenz, Machine Learning und Deep Learning
- Maschinelles Lernen in Databricks mithilfe von MLlib
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns.
Ihre Ansprechpartnerin



