Serie | Data Science (ML & AI) – Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
Während es im ersten Teil um die Architektur und Funktionsweise von baumartigen Regressionsverfahren ging, folgt nun die praktische Anwendung. Dazu werden ein Regressionsbaum, eine Random Forest Regression sowie eine Gradient Boosting Regression entwickelt, welche die Preise von Airbnb-Unterkünften prädiktieren.
Beschreibung des Datensatzes
Der Datensatz zum Training der Regressionsmodelle ist auf kaggle verfügbar und enthält Daten zu Airbnb-Unterkünften aus verschiedenen europäischen Städten. Zu jedem Objekt gibt es neben der Angabe des Preises auch Attribute zum Zimmer und zur Lage sowie mehrere Ratings. Insgesamt besteht der Datensatz aus 51.707 Einträgen mit Airbnbs aus Amsterdam, Athen, Barcelona, Berlin, Budapest, Lissabon, London, Paris, Rom und Wien.
Erstellung eines Regressionsbaums
Im ersten Schritt wird ein Regressionsbaum zur Prädiktion der Airbnb-Preise entwickelt. Dabei wird eine Hyperparameteroptimierung durchgeführt, um die optimale Tiefe des Baumes und die Anzahl an genutzten Features zu bestimmen. Dazu dient die folgende Funktion, welche für ein Modell die besten Parameter aus einem vorgegebenen Parameterraum mithilfe einer Grid-Suche auswählt. Anschließend wird das Modell mit den optimalen Parametern auf dem Trainingssatz trainiert und anhand verschiedener Metriken auf dem Testsatz evaluiert.
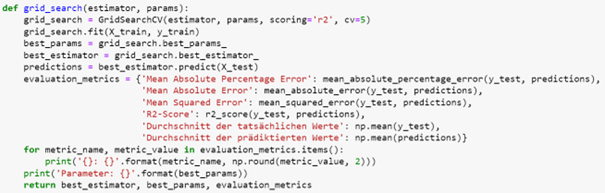
In unserem Beispiel besteht der Suchraum für die Parameter aus einer maximalen Baumtiefe von 3, 5, 7 oder einer unbegrenzten Tiefe und maximal 3, 5, 7 oder beliebig vielen verwendeten Features im Regressionsbaum.
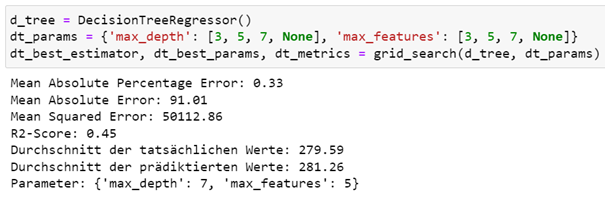
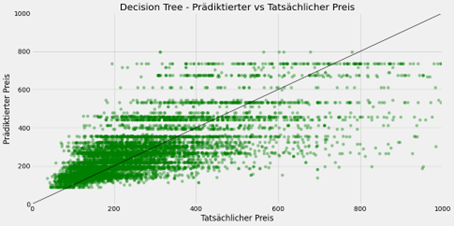
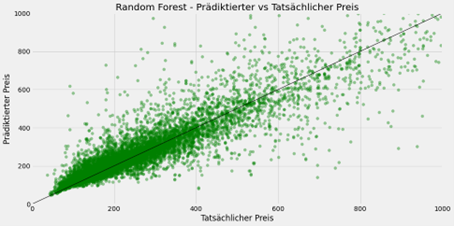
Als optimale Parameterkombination ergab sich dabei eine Baumtiefe von sieben mit maximal fünf Features. Damit erreicht der Regressionsbaum einen Mean Absolute Error von 91 und einen R2-Wert von 0,45 auf dem Testsatz. Die folgende Grafik stellt den tatsächlichen und vom Regressionsbaum prädiktierten Preis für die einzelnen Airbnb-Unterkünfte dar.
Entwicklung einer Random Forest Regression
Als nächstes wird eine Random Forest Regression gebildet, wobei hier der Parametersuchraum aus entweder 300 oder 500 Regressionsbäumen mit einer maximalen Baumtiefe von 3, 5, 7 oder einer unbegrenzten Tiefe besteht.
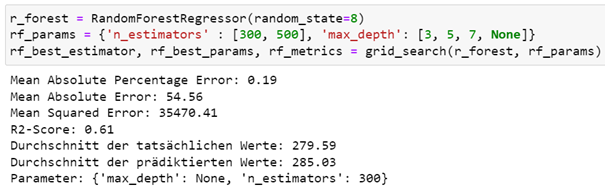
Insgesamt erzielt die Random Forest Regression bei 300 Regressionsbäumen mit einer unbegrenzten Baumtiefe einen Mean Absolute Error von 54,56 und einen R2-Wert von 0,61 auf dem Testsatz.
Bildung eines Gradient Boosting Regressors
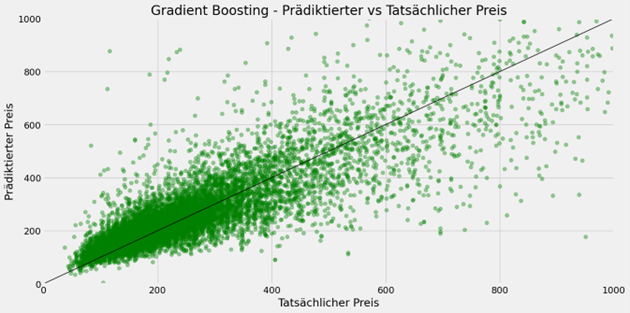
Zum Abschluss wird auch eine Gradient Boosting Regression zur Prädiktion der Airbnb-Preise genutzt. Hierbei enthält der Suchraum für die Hyperparameteroptimierung Werte für die Anzahl der Regressionsbäume, die Lernrate und die maximale Baumtiefe. Die Anzahl der Regressionsbäume liegt entweder bei 300 oder 500 Bäumen, die Lernrate beträgt 0,01 oder 0,1 und die maximale Baumtiefe ist 3, 5 oder unbegrenzt.
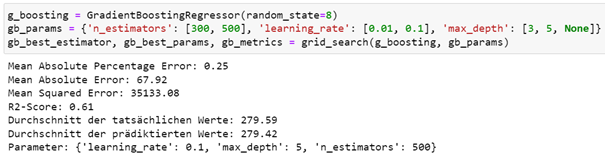
Die Gradient Boosting Regression kommt mit 500 Regressionsbäumen und einer maximalen Baumtiefe von 5 bei einer Lernrate von 0,1 auf einen Mean Absolute Error von 67,92 und einen R2-Wert von 0,61.
Fazit zu baumartigen Regressionsverfahren
Nach Auswertung der drei baumartigen Regressionsverfahren liefert die Random Forest Regression die genauesten Vorhersagen für die Preise von Airbnb-Unterkünften, wobei die durchschnittliche Abweichung vom tatsächlichen Preis 54,56€ beträgt.
| Regressionsverfahren | Mean Absolute Error | R2-Wert |
| Regressionsbaum | 91,01 | 0,45 |
| Random Forest | 54,56 | 0,61 |
| Gradient Boosting | 67,92 | 0,61 |
Sie möchten mehr über die Möglichkeiten von Data Science erfahren? Dann nichts wie ab zu unserem Data Strategy & Analytics Assessment!
Übersicht der Data Science (ML & AI) Serie:
- AI im Fußball: Entwicklung eines Expected Goals Modells
- Einführung in Deep Learning und PyTorch
- NLP zur Analyse von E-Mails
- Entwicklung eines Machine Learning Modells auf Azure
- Architektur und Funktionsweise von neuronalen Netzen
- Entwicklung eines neuronalen Netzes zur Prädiktion von Airbnb-Preisen
- Architektur und Funktionsweise von baumartigen Regressionsverfahren
- Entwicklung baumartiger Regressionsverfahren zur Prädiktion von Airbnb-Preisen
- Was sind Large Language Modelle
- Das Large Language Model GPT-4
- Prompt Engineering in ChatGPT
- Entwicklung eines Large Language Modells mit LangChain & OpenAI
- Überblick zu Künstlicher Intelligenz, Machine Learning und Deep Learning
- Maschinelles Lernen in Databricks mithilfe von MLlib
Haben wir Ihr Interesse geweckt? Kontaktieren Sie uns!
Ihr Ansprechpartner



